






许多基础数据类型都和对象的集合有关。具体来说,数据类型的值就是一组对象的集合,所有操作都是关于添加、删除或是访问集合中的对象。在本节中,我们将学习三种这样的数据类型,分别是背包(Bag)、队列(Queue)、和栈(Stack). 他们的不同之处在于删除或者访问对象的顺序不同。
一、背包
API:
public class Bag<Item> implements Iterable<Item> Bag() 创建一个空背包 void add(Item item) 添加一个元素 boolean isEmpty() 背包是否为空 int size() 背包中的元素数量
背包一种不支持从中删除元素的集合数据类型。迭代的顺序不确定且与用例无关。
二、先进先出队列
在应用程序中使用队列的主要原因是在用集合保存元素的同时保存它们的相对顺序:使他们入列顺序和出列顺序相同。
API:
public class Queue<Item> implements Iterable<Item> Queue() 创建空队列 void enqueue(Item item) 添加一个元素 Item dequeue() 删除最近添加的元素 boolean isEmpty() 队列是否为空 int size() 队列中的元素数量
三、下压栈
下压栈(或简称栈)是一种基于后进先出策略的集合类型;当用例使用foreach语句迭代遍历栈中的元素时,元素的处理顺序和它们被压入的顺序正好相反。
在应用程序中使用栈迭代器的一个典型原因是在用集合保存元素的同时颠倒它们的相对顺序。
API:
public class Stack<Item> implements Iterable<Item> Stack() 创建一个空栈 void push(Item item) 添加一个元素 Item pop() 删除最近添加的元素 boolean isEmpty() 栈是否为空 int size() 栈中的元素数量
一个栈例子,计算( 1 + ( ( 2 + 3 ) * ( 4 * 5 ) ) )
如何使用程序来完成计算呢?
大神发明了一个非常简单的算法,用两个栈(一个用于保存运算符,一个用于保存操作数)完成了这个任务。
表达式由括号、运算符和操作数(数字)组成。我们根据以下4种情况从左到右逐个将这些实体送入栈处理:
.将操作数压入操作数栈;
.将运算符压入运算符栈;
.忽略左括号;
.在遇到右括号时,弹出一个运算符,弹出所需数量的操作数,并将运算符和操作数的运算结果压入操作数栈。(p91)
代码:


package algorithm; import stdLib.StdIn; import stdLib.StdOut; /** * 〈Dijkstra的双栈算术表达式求值算法〉<br> */ public class Evaluate { public static void main(String[] args) { Stack<String> ops = new Stack<>(); Stack<Double> vals = new Stack<>(); while (!StdIn.isEmpty()) { // 读取字符,如果是运算符则压入栈 String s = StdIn.readString(); if(s.equals("end")){ System.out.println(vals.pop()); break; } if (s.equals("(")) ; else if (s.equals("+")) ops.push(s); else if (s.equals("-")) ops.push(s); else if (s.equals("*")) ops.push(s); else if (s.equals("/")) ops.push(s); else if (s.equals("sqrt")) ops.push(s); else if (s.equals(")")){ //如果字符为")",弹出运算符和操作数,计算结果并压入栈 String op = ops.pop(); double v = vals.pop(); if(op.equals("+")) v = vals.pop() + v; else if(op.equals("-")) v = vals.pop() - v; else if(op.equals("*")) v = vals.pop() * v; else if(op.equals("/")) v = vals.pop() / v; else if(op.equals("sqrt")) v = Math.sqrt(v); vals.push(v); }//如果字符既非运算符也不是括号,将它作为double值压入栈 else vals.push(Double.parseDouble(s)); } } }
console输入计算表达式,输入end结束:
( 1 + ( ( 2 + 3 ) * ( 4 * 5 ) ) )
end
101.0
实现一个栈,先是定容栈,一个最简单的例子,它只能:
1)装String字符串;
2)指定容量,且不可迭代
实现如下:
package algorithm; /** * 〈定容栈 一个最简单的例子〉<br> */ public class FixedCapacityStackOfStrings { private String[] a; private int N; public FixedCapacityStackOfStrings(int cap){ a = new String[cap]; } public boolean isEmpty(){ return N == 0; } public int size(){ return N; } public void push(String item){ a[N++] = item; } public String pop(){ return a[--N]; } }
下面做些改进:
1)增加泛型
2)数组大小能动态调整
3)增加迭代方法
算法1.1:
package algorithm; import java.util.Iterator; /** * 〈能够动态调整数组大小的实现〉<br> */ public class ResizingArrayStack<Item> implements Iterable<Item>{ private Item[] a = (Item[]) new Object[1]; //栈元素 private int N = 0; //元素数量 public boolean isEmpty(){ return N == 0; } public int size(){ return N; } private void resize(int max){ //将栈移动到一个大小为max的新数组 Item[] temp = (Item[]) new Object[max]; for(int i=0; i<N; i++){ temp[i] = a[i]; } a = temp; } public void push(Item item){ //将元素添加到栈顶 if(N == a.length) resize(2*a.length); a[N++] = item; } public Item pop(){ //从栈顶删除元素 Item item = a[--N]; a[N] = null; //避免对象游离 if(N>0 && N==a.length/4) resize(a.length/2); return item; } @Override public Iterator<Item> iterator() { return new ReverseArrayIterator(); } private class ReverseArrayIterator implements Iterator<Item>{ //支持后进先出的迭代 private int i = N; @Override public boolean hasNext() { return i > 0; } @Override public Item next() { return a[--i]; } @Override public void remove() { } } }
算法1.1十分重要,因为它几乎(但还没有)达到了任意集合数据类型的实现的最佳性能:
1.每项操作的用时都与集合大小无关
2.空间需求总是不超过集合大小乘以一个常数。
但是ResizingArrayStack的缺点在于某些push和pop操作会调整数组的大小:这项操作的耗时和栈大小成正比。下面我们将学习一种克服该缺陷的方法,使用一种完全不同的方式来组织数据。--- 链表
链表
在此我们的实现将成为本书其他更加复杂的数据结构的构造代码的模板。
代码,算法1.2:
package algorithm; /** * 〈算法1.2 下压堆栈 链表实现〉<br> */ public class Stack<Item>{ private Node first; //栈顶(最近添加的元素) private int N; //元素数量 //定义的节点的嵌套类 private class Node{ Item item; Node next; } public boolean isEmpty(){ return first == null; //或N==0 } public int size(){ return N; } public void push(Item item){ //向栈顶添加元素 Node oldFirst = first; first = new Node(); first.item = item; first.next = oldFirst; N++; } public Item pop(){ //从栈顶删除元素 Item item = first.item; first = first.next; N--; return item; } }
这份泛型的stack实现的基础是链表数据结构。它可以用于创建任意数据类型的栈。要支持迭代,请添加算法1.4中为Bag数据类型给出的加粗部分代码。
链表的使用达到了我们的最优设计目标:
1.它可以处理任意类型的数据;
2.所需的空间总是和集合的大小成正比;
3.操作所需的时间总是和集合的大小无关。
队列的实现
基于链表数据结构实现Queue API也很简单。如算法1.3:
package algorithm; /** * 〈算法1.3 先进先出队列〉<br> */ public class Queue<Item> { private Node first; private Node last; private int N; private class Node{ Item item; Node next; } public boolean isEmpty(){ return first == null; //或 N == 0 } public int size(){ return N; } //向表尾添加元素 public void enqueue(Item item){ Node oldLast = last; last = new Node(); last.item = item; last.next = null; if(isEmpty()){ first = last; }else{ oldLast.next = last; } N++; } //从表头删除元素 public Item dequeue(){ Item item = first.item; first = first.next; if(isEmpty()){ last = null; } N--; return item; } //iterator()的实现请见算法1.4 }
在结构化存储数据集时,链表是数组的一种重要的替代方法。这种替代方案已经有数十年的历史。
背包的实现
用链表数据结构实现我们的Bag API只需要将Stack中的push方法改名为add();并去掉pop()的实现即可。如算法1.4所示:
package algorithm; import java.util.Iterator; /** * 〈算法1.4 背包〉<br> */ public class Bag<Item> implements Iterable<Item> { private Node first; private class Node{ Item item; Node next; } //和Stack的push完全相同 public void add(Item item){ Node oldFirst = first; first = new Node(); first.item = item; first.next = oldFirst; } @Override public Iterator<Item> iterator() { return new ListIterator(); } private class ListIterator implements Iterator<Item>{ private Node current = first; @Override public boolean hasNext() { return current!=null; } @Override public Item next() { Item item = current.item; current = current.next; return item; } @Override public void remove() { } } }
这份Bag的实现维护了一条链表,用于保存所有通过add添加的元素。size和empty方法和Stack中的完全相同,因此这里省略。我们可以将迭代的代码添加到算法1.1和算法1.2中使得Stack和Queue变为可迭代的,因为它们背后的数据结构是相同的。只是Stack和Queue的链表访问顺序分别是后进先出和先进先出而已。
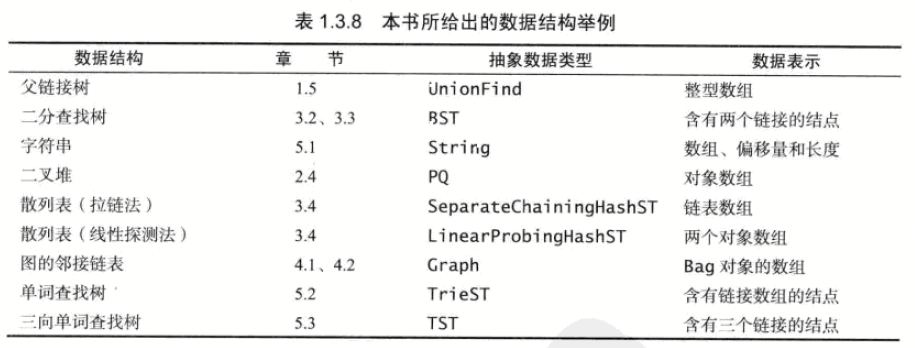
综述
















 549
549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









