







在分布式系统中,对传统的单体应用进行水平或垂直的拆分,拆分后不可避免的出现了如何保证系统状态、数据之间一致性的问题。
在分布式的架构中,一致性指分布式服务化系统之间的弱一致性,包括应用系统的一致性和数据的一致性。
1.常见的一致性问题:
1.1 下订单和扣库存
在设计分布式电商系统中如何保证下订单和扣库存保持一致的问题。
1.2 同步调用超时
系统A调用系统B超时,系统A可以明确得到超时反馈,但是无法确定系统B是否已经完成了请求的预定功能,系统B自己不能发现自己是否超时。
1.3 异步回调超时
系统A同步调用系统B发出指令,系统B接受指令并返回接收成功信息,系统处理后异步通知系统A处理结果,在这个过程中如果系统A由于某些原因没有收到系统B的回调信息,就会导致两个系统对同一处理事件的状态不一致,导致系统错误。
1.4 缓存和数据库不一致
高并发系统为了保护数据库需要在数据库前加一层缓存,缓存和数据库的一致性如何保证。
1.5 不同的缓存节点间的数据不一致
同一服务的多个节点为了满足更高的性能,需要使用本地缓存,这样没个节点都会有一份缓存数据的拷贝,如果这些缓存数据是半静态的或者经常被更新,则被更新时各个节点的更新是有先后顺序的,在更新的瞬间,在某个时间窗口内各个节点的数据是不一致的,重复的请求进入不同的节点执行的逻辑可能就不同。
1.6 缓存数据结构不一致
有的系统在缓存中暂存某种类型的数据,该数据由多个数据元素组成,其中,某个数据元素需要从数据库或者服务中获取,如果一部分元素获取失败,由于程序处理不正确,仍然将不完全的数据存入缓存中,缓存的使用者可能会因为缓存的不完整出现异常。
2.解决一致性问题的模式和思路
2.1 分布式一致性协议
国际开放标准组织Open Group定义了DTS(分布式事务处理模型),根据DTS衍生了三种常用的协议。
2.1.1 两阶段提交协议
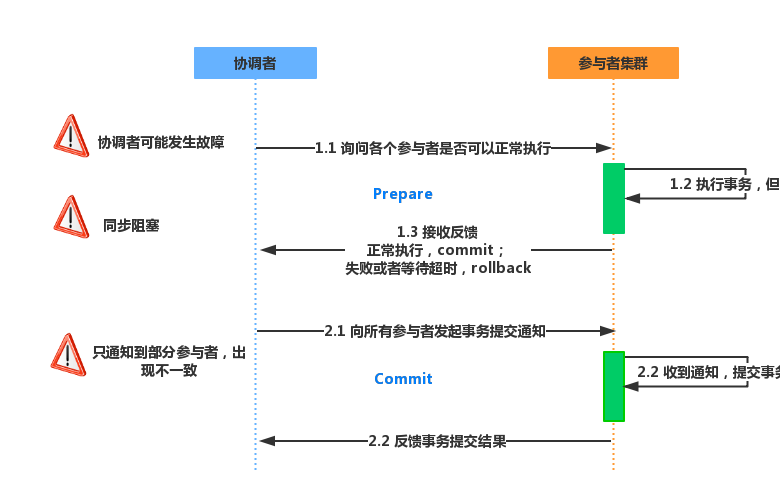
两阶段提交协议把分布式事务分为两个阶段,一个是准备阶段,另一个是提交阶段。准备阶段和提交阶段都是由事务管理器(下文协调者)发起的。
两阶段提交协议的流程如下所述。
a.准备阶段:事务管理器向事务参与者发起指令,参与者评估自己的状态,如果参与者评估指令可以完成,则会写redo或者undo日志,然后锁定资源,执行操作,但是并不提交。
b.提交阶段:如果每个参与者明确返回准备成功,也就是预留资源和执行操作成功,则事务管理器向参与者提交指令,参与者提交资源变更的事务,释放锁定的资源;如果任何一个参与者明确返回准备失败,也就是预留资源或者执行操作失败,则事务管理器向事务参与者发起中止指令,参与者取消已经变更的事务,执行undo日志,释放锁定的资源。
流程如下图(事务管理器起协调者作用):
2.1.2 三阶段提交协议
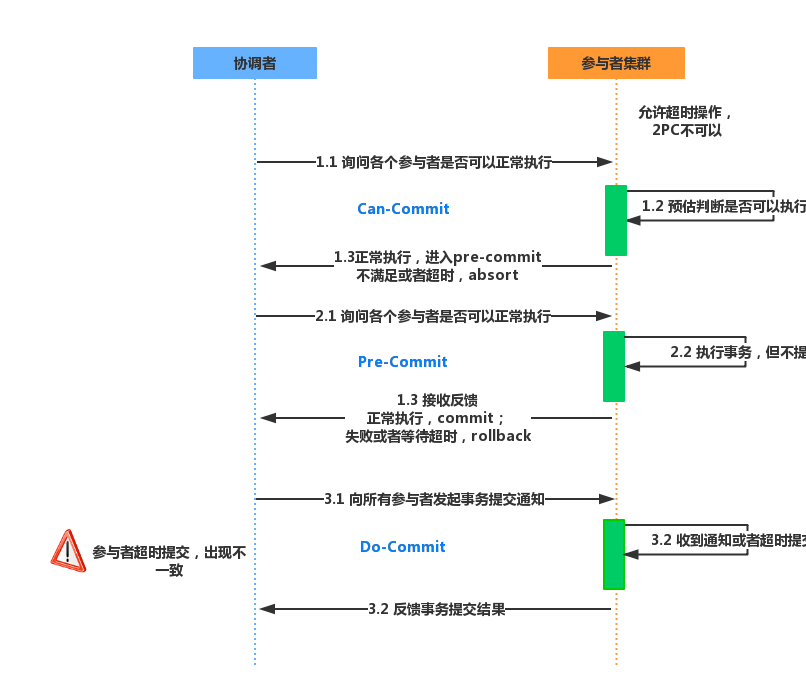
三阶段提交协议是两阶段提交协议的改进版本,通过超时机制解决了阻塞问题,并且把两个阶段增加为一下三个阶段。
a.询问阶段:协调者询问参与者是否可以完成指令,协调者只需要回答是或者不是,而不需要做真正的操作,这个阶段超时会导致中止。
b.主备阶段:如果在询问阶段所有参与者都返回可以执行操作,则协调者向参与者发送预执行请求,然后参与者写redo和undo日志,执行操作但是不提交操作;如果在询问阶段任意参与者返回不能执行操作的结果,则协调者向参与者发送中止请求,这里的逻辑与两阶段提交协议的准本阶段相似。
c.提交阶段:如果每个参与者在准备阶段都返回成功,则协调者向参与者发起提交指令,参与者提交资源变更的事务,释放锁定的资源;如果任何参与者返回准备失败,即预留资源或者执行操作失败,则协调者向参与者发起中止指令,参与者取消已经变更的事务,执行undo日志,释放锁定的资源。
流程如下图:
2.1.3 TCC协议
两阶段提交协议和三阶段提交协议实现方案中包含多个参与者、多个阶段实现一个事务,实现复杂,性能也是个很大的问题,因此严格意义上的两三阶段协议在实际高并发系统中很少使用。
后来有人这此基础上提出了TCC协议,TCC协议将一个任务拆分成Try、Confirm、Cancel三个步骤,正常的流程会先执行Try,如果执行没有问题,则载执行Confirm,如果执行过程中出了问题,则执行操作的逆操作Cancel。从正常流程来看,这仍然是一个两阶段提交协议,但是在执行出现问题时有一定的自我修复能力,如果任何参与者出现了问题,则协调者通过执行操作的逆操作Cancel之前的操作,达到最终的一致状态。
3 保证最终的一致性
上述描述的分布式事务协议实现起来复杂,对系统性能也有比较大的影响,所以在我们实际的业务中可以去考虑是否有必要实现事务的强一致性,如果我们的系统达到最终一致性就可以满足我的需求的话,尽量选择实现最终一致性,避免复杂的实现协议。最终的一致性可以用一些简单有效的方式来实现。
3.1 查询模式
你的服务对外提供一个查询接口,用来向外部输出操作执行的状态。服务操作的使用方可以通过查询接口得知服务操作的执行状态,然后根据不同的状态来做不同的处理操作。
3.2 补偿模式
查询模式中,在任何情况下,我们都能得知具体的操作所处的状态,如果整个操作都处于不正常的状态,则我们需要修正操作中有问题的子操作,这可能需要重新执行未完成的子操作,后者取消已经完成的子操作,通过修复使整个分布式系统达到一致。为了让系统最终达到一致状态而做出的努力都叫做补偿。
3.3 异步确保模式
异步确保模式是补偿模式的一个特例,经常应用到使用方对响应时间要求不太高的场景中,通常把这类操作从主流程中分离出来,通过异步的方式进行处理,然后把结果通知使用方。在实际场景中,将要执行的异步操作封装后持久入库,然后通过定时捞取未完成的任务进行补偿操作来实现异步确保模式,只要定时系统足够健壮,则任何任务最终都会被执行。
3.4 定期校对模式
在操作主流程中的系统执行校对操作,可以在事后异步地批量校对操作的状态,如果发现不一致的操作,则进行补偿,补偿操作与补偿模式中的补偿操作一致。
实现定期校对的关键是分布式系统中需要一个始终唯一的ID,关于生成全局唯一ID的方法可以参考我另一篇文章。
3.5 可靠消息模式
在分布式系统中,对于主流程中优先级比较低的操作,大多采用异步的方式执行,而在异步化的实现上消息队列是我们常用的选择。如何保证分布式消息队列的可靠性成了必须解决的问题。前提:消息可靠性发送,在发送消息前将消息持久到数据库,状态标记为未发送,然后发送消息,如果发送成功,则将消息改为发送成功。定时任务定时从数据库捞取在一定数据内未发送的消息并将消息发送。消息可靠发送机制实现后,我们需要在消息接收处理器实现幂等性,之前为了保证消息可靠发送需要重试机制,有了重试机制后消息一定会重复,所以消息处理端需要对重复的问题进行处理。
3.6 缓存一致性模式
在高并发的系统中,让大量请求直接打到数据库是有严重问题的,常用的做法就是使用缓存来抗住读流量,下面是关于实现缓存一致性的一些方法。
- 如果性能要求不是很高,则尽量使用分布式缓存,而不用本地缓存。
- 写缓存时数据一定要完整,如果缓存数据的一部分有效,另一部分无效,则宁可在需要的时候汇源数据库,也不要把部分数据放入缓存中。
- 使用缓存牺牲了一致性,为了提高性能,数据库与缓存只需要保持弱一致性,而不是要保持强一制性,否则违背了使用缓存的初衷。
- 读的顺序是先读缓存,后读数据库,写的顺序要先写数据库,后写缓存。















 2136
2136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









