







solrj针对solrcloud提供了CloudSolrClient,用于对集群环境solr操作,从一个测试例子,一步步深入,看看CloudSolrClient是如何做查询操作的
1、使用CloudSolrClient发起一个查询请求

2、接着调用CloudSolrClient的request方法

3、CloudSolrClient的request方法中,首先回去获取请求中的collection名字,如果没有,获取默认设置的collcetion,然后调用requestWithRetryOnStaleState方法

4、requestWithRetryOnStaleState方法中,先去连接zk获取solrclound注册在zk上的信息

5、获取zk上的信息,经过处理后,封装到request中,调用sendRequest方法

6、在sendRequest中,会获取每个片的每个replicat的url与注册在zk上的live url做一个交集,得到一个查询url集合,然后创建一个LBHttpSolrClient,请求solrcloud


7、LBHttpSolrClient的request中会在for循环中挨个的轮询上一个步骤中放入的urllist发起http查询请求
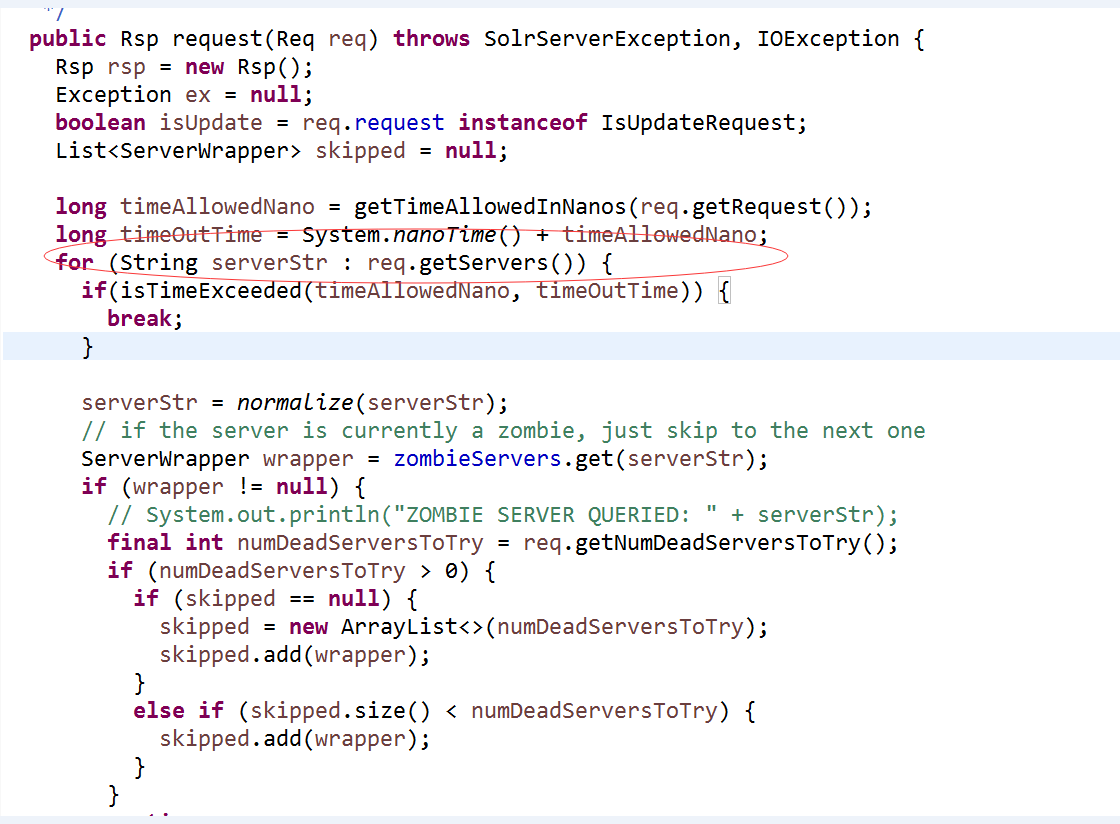

在rsp合并结果,并返回
问题
在LBHttpSolrClient的request中,http请求是串行化的,也就说,一次查询,需要串行的发起n个http请求,太耗费时间
建议
在LBHttpSolrClient的request中对多个url发起请求,可以考虑并行化的http请求
在CloudSolrClient中保持对zk的长连接watch不断
也可以从业务入手,采取手动路由的方式,即”知道自己要的数据在那个分片上“,直接对该分片发起http查询请求,这样会减少http请求个数

















 4027
4027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









