







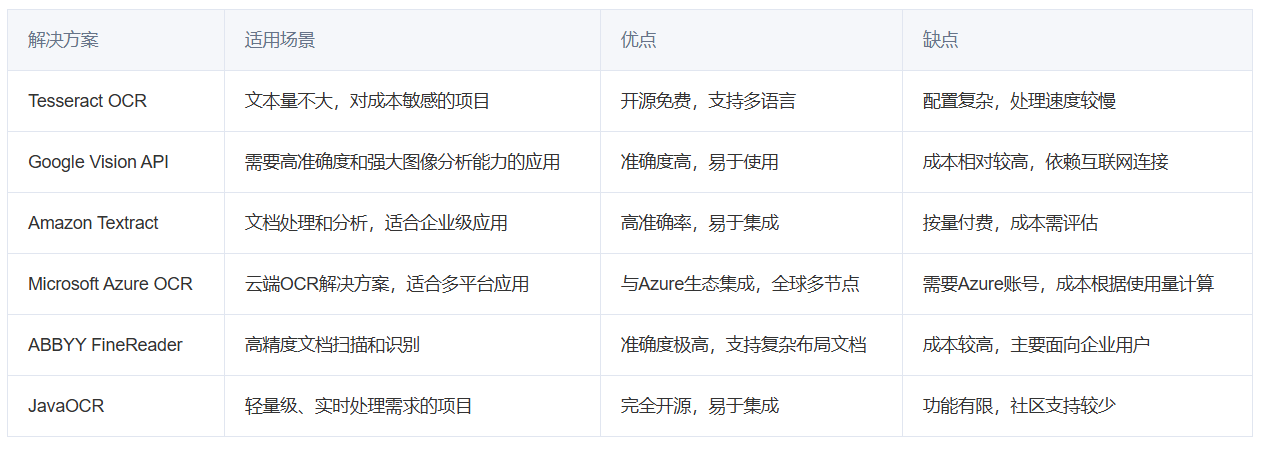
一、OCR的选择
系统的一大功能便是用户可自由上传多种形式的文件,由系统来负责提取信息。图片则是其中重要的部分,拥有完整的、正式的电子档教材的毕竟是少数。对图片的文本提取呢,很自然的就想到OCR技术,在网上查阅资料后,对比了几款易于获取的解决方案。
综合考虑了难度和性能要求,我们先尝试Tessertact OCR。
二、Tessertact的引入
Tessertact为我们提供了非常轻便的Java库。在pom.xml中添加依赖即可。
<!-- Tesseract OCR 的java api实现库 -->
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>5.7.0</version>
</dependency>
之后需要下载官网的训练数据,Tesseract OCR库通过训练数据来学习不同语言和字体的特征,以便更好地识别图片中的特定语言的文字。
Tesseract 在 GitHub 上有三个独立的语言模型存储库:
tesseract-ocr/tessdata tesseract-ocr/tessdata_best tesseract-ocr/tessdata_fast
这里以tessdata为例,在列表中找到中文。
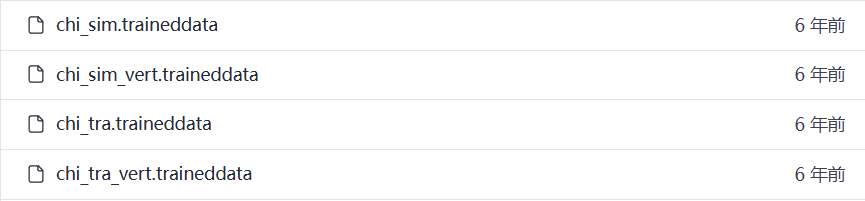
从上至下为:简体中文、简体中文修正版、繁体中文、繁体中文修正版。修正版消除了中文词内多余的空格(官方英文直译)。
下载后放置到一个合适的位置并把路径配置到application.properties文件:
# 训练数据路径
tess4j.datapath: D:/tessdata
若是yml文件,则格式有所差异。
tess4j:
datapath: D:/tessdata
三、Tessertact的配置
为了避免每次调用前都要设置Tessertact的参数,所以创建一个配置类。
package com.dpsk.dpsk_quiz_sys_java.config;
import net.sourceforge.tess4j.Tesseract;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class TesseractOcrConfiguration {
@Value("${tess4j.datapath}") // 从 application.properties 读取路径
private String dataPath;
@Bean
public Tesseract tesseract() {
Tesseract tesseract = new Tesseract();
tesseract.setDatapath(dataPath); // 设置 Tesseract 训练数据路径
tesseract.setLanguage("chi_sim"); // 设置中文简体
return tesseract;
}四、流程分析
我们的目标是完成对单图和多图都能正常识别,多图采用压缩包的形式;以及pdf的识别。
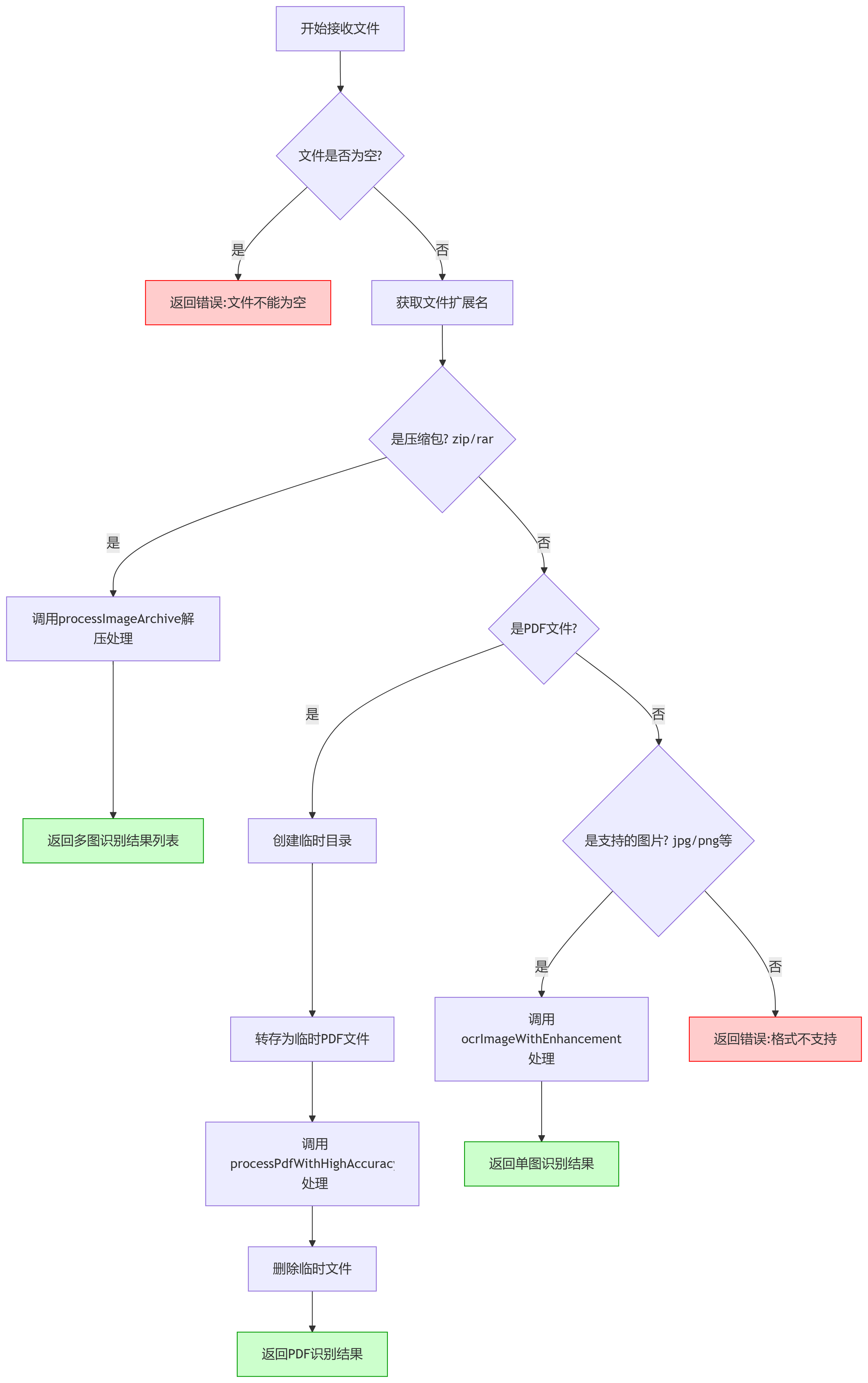
那Controller代码如下,很好理解:
@PostMapping(value = "/recognize", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public ResponseMessage recognizeImage(@RequestParam("file") MultipartFile mfile) {
try {
// 基础验证
if (mfile.isEmpty()) {
return ResponseMessage.error("文件不能为空");
}
String fileName = StringUtils.cleanPath(Objects.requireNonNull(mfile.getOriginalFilename()));
String extension = FilenameUtils.getExtension(fileName).toLowerCase();
// 1. 先判断是否是压缩包(优先级最高)
if (isArchiveFile(extension)) {
List<String> results = tessOcrService.processImageArchive(mfile);
return ResponseMessage.success(results);
}
// 2. 再判断PDF
else if (extension.equals("pdf")) {
Path tempDir = Files.createTempDirectory("pdf_ocr_");
Path tempFile = tempDir.resolve("temp.pdf");
try {
mfile.transferTo(tempFile.toFile());
String result = tessOcrService.processPdfWithHighAccuracy(tempFile.toFile());
return ResponseMessage.success(result);
} finally {
Files.deleteIfExists(tempFile);
Files.deleteIfExists(tempDir);
}
}
// 3. 最后判断普通图片
else if (isSupportedImage(extension)) {
String result = tessOcrService.ocrImageWithEnhancement(mfile);
return ResponseMessage.success(result);
}
else {
return ResponseMessage.error("不支持的文件格式: " + extension);
}
} catch (Exception e) {
return ResponseMessage.error("识别失败: " + e.getMessage());
}
}
// 判断是否是压缩包
private boolean isArchiveFile(String extension) {
return Set.of("zip", "rar").contains(extension);
}
// 判断是否是支持的图片格式
private boolean isSupportedImage(String extension) {
return Set.of("jpg", "jpeg", "png", "bmp", "tiff").contains(extension);
}
















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









