







前言
想实现python登录淘宝,大概有两种思路:1. 使用淘宝开放API接口;
2.使用模拟登陆发送post 数据登录。
两种方式各有优缺点。使用淘宝API,首先得装API库,比较大,有200多M,对小程序而言不划算。另一方面,需要研究他的API,里面函数很多,使用起来并没那么容易。第二种方式,就是各种过程需要亲自动手写代码,需要找post data结构,适合实现简单功能。本文采用第二种方式。
参考资料
python实现模拟登录 :博文,简介模拟登录代码流程(主要参考)
新浪博客登录 :python模拟登录新浪微博,代码更复杂,没有实际运行,不知道是否跑的通
详解抓取网站,模拟登陆,抓取动态网页的原理和实现(Python,C#等):讲原理的,还没来得及仔细看,大致浏览下还不错的样子
【整理】关于抓取网页,分析网页内容,模拟登陆网站的逻辑/流程和注意事项:讲解较详细,从上面网页中打开的链接
Python专题教程:抓取网站,模拟登陆,抓取动态网页 : 备用资料
流程简介
核心思想是:1.设置一个cookie处理器,它负责从服务器下载cookie到本地,并且在发送请求时带上本地的cookie (这部分还不是很懂,关于下载cookie的有效主页地址不是很明确)
2.向淘宝登录页面发送一个请求Request, 包括登录界面地址,上传的数据包post data(上传之前应先编码,使得与服务器编码一致),Http header
3.利用urllib2.urlopen发送请求,得到响应Response
4.查看响应结果
代码如下:
# -*- coding: utf-8 -*-
import urllib
import urllib2
import cookielib
hostUrl = "https://login.taobao.com/member/login.jhtml"
#此处不明白,不知道下载cookie主机地址,因此使用登录界面地址
tbLoginUrl = "https://login.taobao.com/member/login.jhtml"
#cookie 自动处理器
cj = cookielib.LWPCookieJar() #LWPCookieJar提供可读写操作的cookie文件,存储cookie对象
cookieSupport= urllib2.HTTPCookieProcessor(cj)
opener = urllib2.build_opener(cookieSupport, urllib2.HTTPHandler)
urllib2.install_opener(opener)
#打开登陆页面
taobao = urllib2.urlopen(tbLoginUrl)
curl = taobao.geturl()
print curl
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:14.0) Gecko/20100101 Firefox/14.0.1',
'Referer' : '******'
}
password = "" #你的用户名和密码
username = ""
postData = {
'CtrlVersion': '1,0,0,7',
'TPL_password':password,
'TPL_redirect_url':'',
'TPL_username':username,
#'_tb_token_':'I262PYW48um',
'action':'Authenticator',
'callback':'jsonp312',
'css_style':'',
'event_submit_do_login':'anything',
'fc':2,
'from':'tb',
'from_encoding':'',
'guf':'',
'gvfdcname':'',
'isIgnore':'',
'llnick':'',
'loginType':3,
'longLogin':0,
'minipara' :'',
'minititle':'',
'need_sign':'',
'need_user_id':'',
'not_duplite_str':'',
'popid':'',
'poy':'',
'pstrong':'',
'sign':'',
'style':'default',
'support':'000001',
'tid':''
}
#编码
postData = urllib.urlencode(postData)
#发送请求
request = urllib2.Request(tbLoginUrl, postData, headers)
print type(request)
response = urllib2.urlopen(request)
#查看响应结果
url = response.geturl()
text = response.read()#为str类型,但是尝试使用 gbk , ascii解码都不正确,无法输出,暂时没想到解决办法
#原来是编辑器的原因,改用eclipse或者python IDE运行,结果如下
info = response.info()
status = response.getcode()
print status,url,info
print text输出结果:
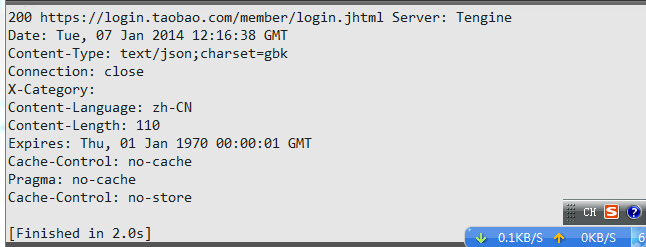
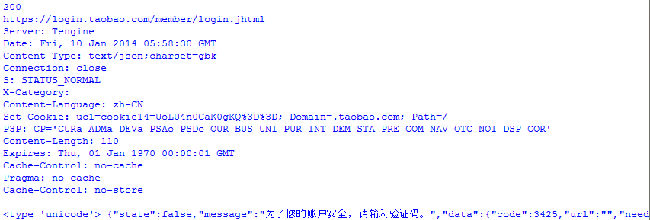
可以看到登录未成功,需要输入验证码,关于验证码,下一篇中介绍。















 8769
8769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









