







现在在回头去看前面写的东西感觉有些杂乱,虽然在写之前已经大概想好要按着怎样的思路去写,但是在真正写的时候发现问题越来越多,不懂的地方也越来越多,于是就不断的上网去查解决的方法,结果又获得了很多知识,而且也很想将这些知识写进来,所以就成了现在这个样子,以后还是需要常常提醒自己最初的目的是什么
我们来回顾一下前面讲的知识,为了实现模拟登录,我们先分析了大多数情况下自动登录的方法,于是我们知道了 cookies,接着我们又讨论了怎么使用浏览器工具找到cookies,并且编写代码实现了直接使用 cookies 登录网站,为了进一步的学习 cookies,我们又讲解了 cookielib 模块的使用,而且知道了 cookies 有时效性,于是我们认为不能每一次运行代码前都要先手动登录,然后获取 cookies 写入再进行登录,所以我们分析了浏览器将用户名密码等信息发送出去的过程,讨论了浏览器发送数据的两种方式:POST 和 GET,这时我突然冒出了一个想法,既然浏览器在 POST 数据之后能够自动登录,那么我能不能在代码中直接模拟这个过程呢?
于是我设定了这样的一个流程
1. 设置浏览器的 headers, 设置请求等
2. 使用 httpfox 工具获取post data
3. 将post data 写下来并进行编码
4. 携带 headers 和 data 等信息进行网页请求
这里还是将获取post data 的过程截图出来,首先是登陆界面的网址:http://www.lvye.org/user.php

我们来看看headers和post data

大家可以看到,这里在post的后面还有一个url,这个url很重要,真的很重要,它就是的发送数据的真正网址

好了,这里的post data 也不是很多,我打算把它全部写下去,于是,我写了这样的代码
#!/usr/bin/env python
# -*- coding:UTF-8 -*-
__author__ = "217小月月坑"
'''
使用post直接登陆
'''
import urllib
import urllib2
url = "http://www.lvye.org/user.php"
user_agent = "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:39.0) Gecko/20100101 Firefox/39.0"
referer = "http://www.lvye.org/user.php"
host = "www.lvye.org"
headers = {'User-Agent':user_agent,
'Referer':referer,
'Host':host}
data = {'uname':'xxxxxxxxxxx',
'pass': 'xxxxxxxxxx',
'op': 'login',
'xoops_redirect':''}
post_data = urllib.urlencode(data)
request = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(request,post_data)
print response.read()然后我满心欢喜的等待输出结果......
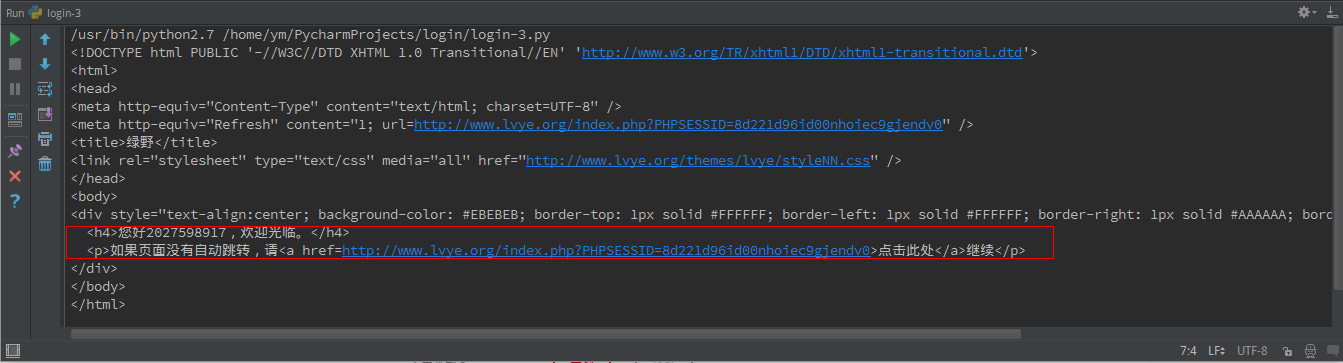
这个页面源码是什么鬼,跟我们前面直接使用cookies获取到的页面源码不一样啊,为什么呢?难道我们的程序出错了吗?
其实并没有,我们的程序已经达到我我们想要的效果,它出现了一个我已经登陆的提示,就是图中框出来的那部分,但这又是为什么呢,而且这些字眼我好像在哪里看到过,为了找出这个原因,我又去重新登陆了一次

我们看到网址还是原来的网址,但是界面却是这样的,而且,这里的文字不就是跟源码里面的文字一样吗,那为什么会出现这样的情况呢?
我们知道当你输入用户名密码登陆一个网站的时候,页面会自动跳转到网站的主页或者其他的网页,总之不会停留在登陆的界面,这在浏览器中很容易实现,但是在爬虫代码中就很难实现,因为一发生跳转就是两个界面,也就是两个不同的url,但是在程序中不可能自动帮你跳转,所以必须要进行两次urlopen()操作,那我就在代码中进行两次urlopen()操作不行吗?来实践看看吧
由于 data 是发送给登陆界面的数据(前面已经讲解了怎么找post data 里面说有找对应的url的),所以我们在打开另一个url时不需要再携带data 信息了,只要在前面那段代码的基础上加上两句话就可以了
response2 = urllib2.urlopen("http://www.lvye.org/userinfo.php?uid=409557")
print response2.read()我们来看输出结果
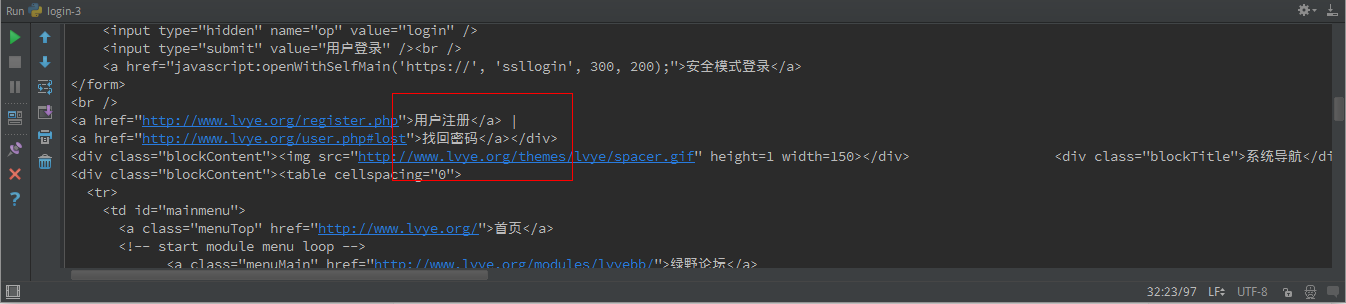
这还是没有返回登陆后的页面的源码,这是为什么呢?
这篇太长了我们下一篇讲解吧















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









