







于是我设定了这样的一个流程
1. 设置浏览器的 headers, 设置请求等
2. 使用 httpfox 工具获取post data
3. 将post data 写下来并进行编码
4. 携带 headers 和 data 等信息进行网页请求
这里还是将获取post data 的过程截图出来,首先是登陆界面的网址:http://www.lvye.org/user.php
我们来看看headers和post data
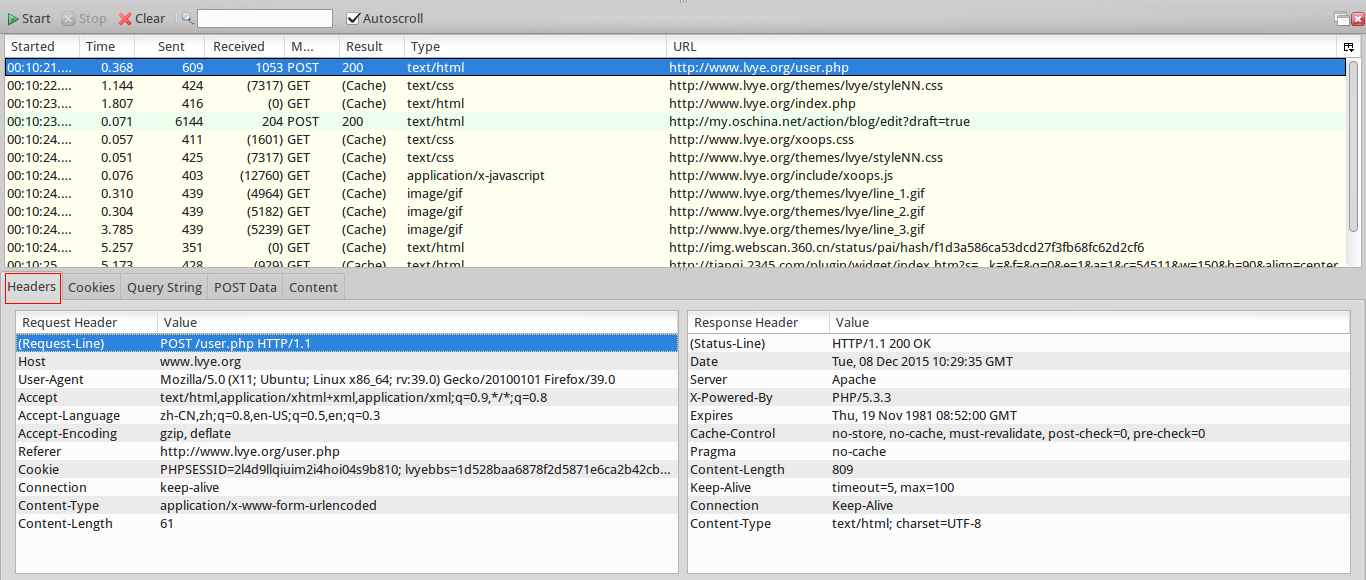
大家可以看到,这里在post的后面还有一个url,这个url很重要,真的很重要,它就是的发送数据的真正网址

好了,这里的post data 也不是很多,我打算把它全部写下去,于是,我写了这样的代码
#!/usr/bin/env python
# -*- coding:UTF-8 -*-
'''
使用post直接登陆
'''
import urllib
import urllib2
url = "http://www.lvye.org/user.php"
user_agent = "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:39.0) Gecko/20100101 Firefox/39.0"
referer = "http://www.lvye.org/user.php"
host = "www.lvye.org"
headers = {'User-Agent':user_agent,
'Referer':referer,
'Host':host}
data = {'uname':'xxxxxxxxxxx',
'pass': 'xxxxxxxxxx',
'op': 'login',
'xoops_redirect':''}
post_data = urllib.urlencode(data)
request = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(request,post_data)
print response.read()然后我满心欢喜的等待输出结果......
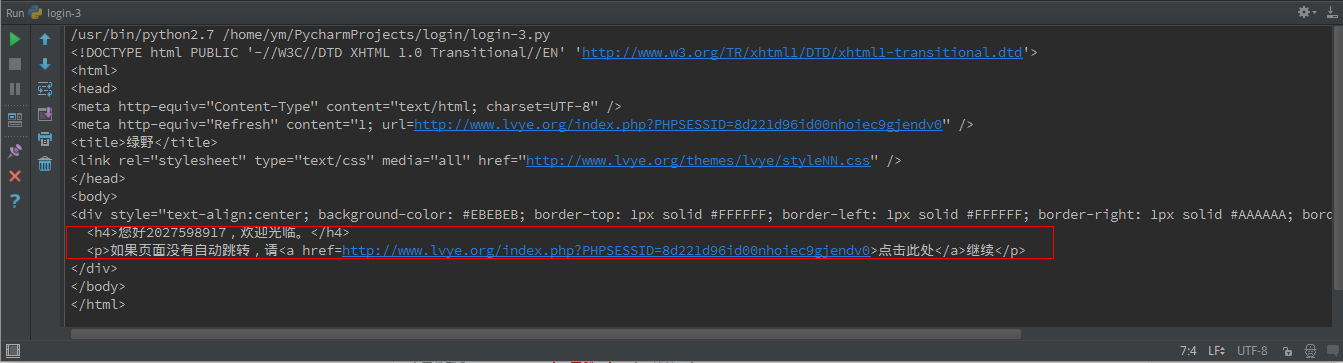
这个页面源码是什么鬼,跟我们前面直接使用cookies获取到的页面源码不一样啊,为什么呢?难道我们的程序出错了吗?
其实并没有,我们的程序已经达到我我们想要的效果,它出现了一个我已经登陆的提示,就是图中框出来的那部分,但这又是为什么呢,而且这些字眼我好像在哪里看到过,为了找出这个原因,我又去重新登陆了一次
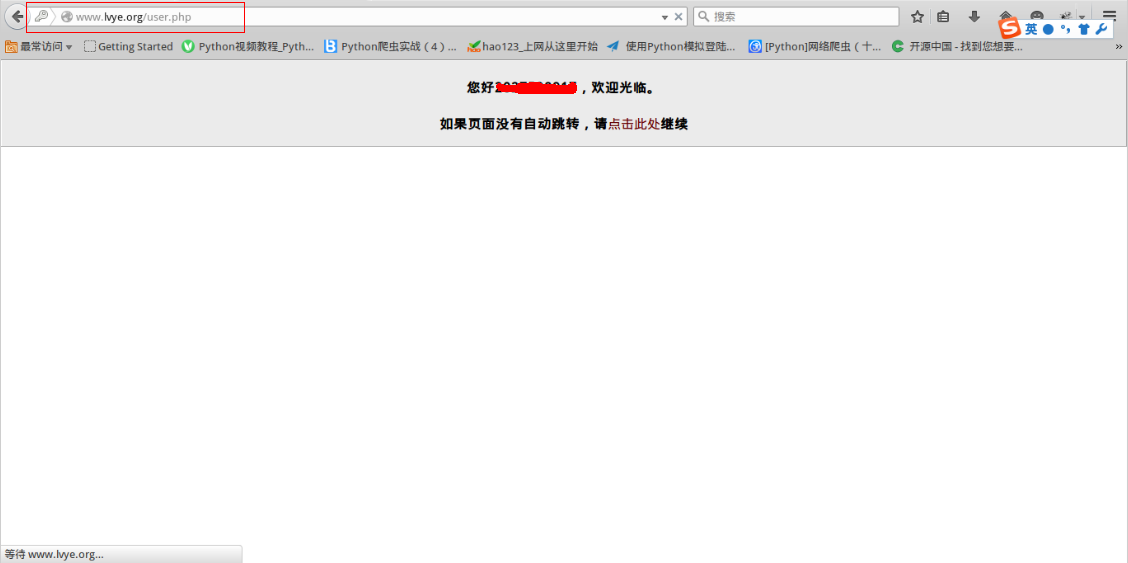
我们看到网址还是原来的网址,但是界面却是这样的,而且,这里的文字不就是跟源码里面的文字一样吗,那为什么会出现这样的情况呢?
我们知道当你输入用户名密码登陆一个网站的时候,页面会自动跳转到网站的主页或者其他的网页,总之不会停留在登陆的界面,这在浏览器中很容易实现,但是在爬虫代码中就很难实现,因为一发生跳转就是两个界面,也就是两个不同的url,但是在程序中不可能自动帮你跳转,所以必须要进行两次urlopen()操作,那我就在代码中进行两次urlopen()操作不行吗?来实践看看吧
由于 data 是发送给登陆界面的数据(前面已经讲解了怎么找post data 里面说有找对应的url的),所以我们在打开另一个url时不需要再携带data 信息了,只要在前面那段代码的基础上加上两句话就可以了
response2 = urllib2.urlopen("http://www.lvye.org/userinfo.php?uid=409557")
print response2.read()我们来看输出结果
这还是没有返回登陆后的页面的源码,这是为什么呢?
这里详细讲两个问题
1. 为什么同样是 urlopen(),第一个携带data,而第二个却没有携带
前面我们已经说了,data 是post发送的数据,而这个发送的数据是有一个规定的url的,通过httpfox可以找的到,不是随便向哪个url发送都行的,所以上面那段的第一个url是登陆的网址,data数据要被发送到这个网址,而第二个url是网站里面的其他网址,不需要传入任何数据,所以不用写data参数,但是其实你加上来也不会报错,但是还是不能得出你想要的结果
2. 为什么上面的做法会失败
首先我们可以确定的是,我们post的方法是完全正确的,因为我们已经从源码中看到了现象,但是为什么我们连续使用两个urlopen()却没有成功呢,因为实际上上面的两个urlopen()只是把两个独立的操作合起来而已,这跟你在两个程序中分别打开这两个url的效果是一样的,不管是哪个urlopen(),它们都只是将网址打开,发送数据,然后获取返回的页面源码而已,它们并没有处理任何数据的能力,比如像cookies,我们前面也说过,因为urlopen()没有处理cookies和http验证的能力,所以要使用opener,这就是根本的原因,就像水过鸭背一样,执行完了就完了,并没有对数据进行处理,还是一样白搭,然并卵。
要解决这个问题只能使用cookies,先post数据到登陆的网址,然后使用cookielib获取cookies,再使用这个cookies登陆网站中其他的网页。因为登陆,获取cookies,使用cookies再次登陆这个是在同一个程序中运行的,处理器够快的话,充其量也就是几秒钟的事情,所以cookies的时效性可以不用考虑,好了,结合我们前面讲解的知识,我们将代码完成吧
#!/usr/bin/env python
# -*- coding:UTF-8 -*-
'''
使用post直接登陆
'''
import urllib
import urllib2
import cookielib
# 登陆界面的url
login_url = "http://www.lvye.org/user.php"
# 用户个人界面的url
user_url = "http://www.lvye.org/userinfo.php?uid=409557"
# 设置浏览器的headers信息
user_agent = "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:39.0) Gecko/20100101 Firefox/39.0"
referer = "http://www.lvye.org/user.php"
host = "www.lvye.org"
headers = {'User-Agent':user_agent,
'Referer':referer,
'Host':host}
# 设置post 的数据
data = {'uname':'xxxxxxxxx',
'pass': 'xxxxxxxxxxxxxx',
'op': 'login',
'xoops_redirect':''}
# 将数据编码成url查询字符串
post_data = urllib.urlencode(data)
# 初始化一个cookieJar来处理 cookies,CookieJar 这个类是获取cookies并保存
cookieJar = cookielib.CookieJar()
# 给opener加入cookies的处理程序
handler = urllib2.HTTPCookieProcessor(cookieJar)
# 构建一个opener
opener = urllib2.build_opener(handler)
# 构造请求
request = urllib2.Request(login_url,headers=headers)
# 打开登陆界面的url,并将data post出去,
login_response = opener.open(request,post_data)
# 自动携带cookies去访问用户界面的url
response = opener.open(user_url)
print response.read()好了,现在用我们前面将的判断模拟登陆是否成功的方法来验证吧















 1638
1638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









