







=======对表结构的访问与操作============
一、获取数据库下所有的表名
select name from NewWorkLog.sys.tables go --NewWorkLog为表名二、要是只获取特定表里特定的字段的数据类型
SELECT data_type FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_NAME ='hos_booking' and COLUMN_NAME='bk_sn' --hos_booking为表名,bk_sn 为字段名三、获取表结构详细信息
SELECT
表名 = case when a.colorder=1 then d.name else '' end,
字段序号 = a.colorder,
字段名 = a.name,
标识 = case when COLUMNPROPERTY( a.id,a.name,'IsIdentity')=1 then '√'else '' end,
主键 = case when exists(SELECT 1 FROM sysobjects where xtype='PK' and parent_obj=a.id and name in (
SELECT name FROM sysindexes WHERE indid in(
SELECT indid FROM sysindexkeys WHERE id = a.id AND colid=a.colid))) then '√' else '' end,
类型 = b.name,
占用字节数 = a.length,
长度 = COLUMNPROPERTY(a.id,a.name,'PRECISION'),
小数位数 = isnull(COLUMNPROPERTY(a.id,a.name,'Scale'),0),
允许空 = case when a.isnullable=1 then '√'else '' end,
默认值 = isnull(e.text,'')
FROM
syscolumns a
left join
systypes b
on
a.xusertype=b.xusertype
inner join
sysobjects d
on
a.id=d.id and d.xtype='U' and d.name<>'dtproperties'
left join
syscomments e
on
a.cdefault=e.id
where
d.name='Department' --如果只查询指定表,加上此条件
order by
a.id,a.colorder四、获取表结构详细信息,包括说明。上面的并没有附加说明
SELECT
[列名]=a.name,
[数据类型]=b.name,
[长度]=COLUMNPROPERTY(a.id,a.name,'PRECISION'),
[是否为空]=case when a.isnullable=1 then '√'else '' end,
[默认值]=isnull(e.text,''),
[说明]=isnull(g.[value],'未填说明')
FROM syscolumns a
left join systypes b on a.xusertype=b.xusertype
inner join sysobjects d on a.id=d.id and d.xtype='U' and d.name<>'dtproperties'
left join syscomments e on a.cdefault=e.id
left join sys.extended_properties g on a.id=g.major_id and a.colid=g.minor_id
left join sys.extended_properties f on d.id=f.major_id and f.minor_id=0where d.name='Base_Organization' order by a.id,a.colorder
--Base_Organization是我们要获取表结构的表名五、修改字段默认值
格式:
alter table 表名 drop constraint 约束名字
说明:删除表的字段的原有约束
alter table 表名 add constraint 约束名字 DEFAULT 默认值 for 字段名称--通过sysdatetime()函数获取当前的默认时间
alter table dbo.Orders
add constraint dft_Orders_orderts
default(sysdatetime()) for orderts
--实例
USE [RM_DB]
GO
alter table [dbo].[Base_Dic_Organize] drop constraint DF__EAI_DIC_O__del_f__14270015
ALTER TABLE [dbo].[Base_Dic_Organize] ADD DEFAULT ('1') FOR [DeleteMark]
GO
--[RM_DB] 为数据库
--[Base_Dic_Organize] 为需要对其约束的字段所在的表名
--DF__EAI_DIC_O__del_f__14270015 为已经存在的约束名
--[DeleteMark] 需要约束的字段六.约束
1.唯一性约束
--如果想同时约束多列唯一性,可以在Name后面指定多个,且以逗号相隔即可
alter table Dict_rgt_Unit add constraint uniqueUnitName unique(Name)2.主键约束
--给表添加主键
use [TSQL2012]
if OBJECT_ID('dbo.Employees','U') is not null
begin
alter table dbo.Employees
add constraint PK_Employees primary key ([empid])
end3.Check约束
use [TSQL2012]
if object_id ('dbo.Employees','U') IS NOT NULL
begin
alter table dbo.Employees
add constraint Ck_salary check([salary]>0)
end4.外键约束
--与其他表建立外键约束,orders中的empid的值只能来自emplyees表中的empid
alter table dbo.orders
add constraint FK_orders_Employees foreign key (empid)
references dbo.employees(empid);
--单张表对自身设置外键。mgrid的值只能来自同表的empid
alter table dbo.Employees
add constraint FK_Employees_Employees foreign key ([mgrid])
references dbo.Employees(empid);七.创建表
--OBJECT_ID是内置函数,查询表dbo.Empleyees是不是在数据库中。U表示为用户表
--创建一张新表建议显示置顶是否为空。
if OBJECT_ID('dbo.Employees','U') is not null
drop table dbo.Employees
create table dbo.Employees
(
empid int not null,
firstname varchar(30) not null,
lastname varchar(30) not null,
hiredate date not null,
mgrid int null,
ssn varchar(20) not null,
salary money not null
);==========对表数据的操作==============
一、查询部分
-
单表查询
select * from [表名】 where 条件
- offset -fetch 筛选(默认最好使用这个,而不是用top,前者是标准的,top不是。)
-
--排序后,跳过五十行后,截取后面的25行数据 select orderid,orderdate,custid,empid from Sales.Orders order by orderdate,orderid offset 50 rows fetch next 25 rows only; --排序后,跳过0行后,截取后面的2行数据 select orderid,orderdate,custid,empid from Sales.Orders order by orderdate,orderid offset 0 rows fetch next 2 rows only; --排序后,跳过五行后,获取后面所有的数据 select orderid,orderdate,custid,empid from Sales.Orders order by orderdate,orderid offset 5 rows ;3.条件谓词
--条件谓词between ... and ... select orderid ,empid,orderdate from Sales.Orders where orderid between 10300 and 10310; --条件谓词in select orderid,empid,orderdate from Sales.Orders where orderid in (10248,10249,10250); --条件谓词LIKE(里面的N代表着数据类型为nvarchar或者nchar) select empid,firstname,lastname from HR.Employees where lastname like N'D%';ps:条件谓词=,>,<,>=,<=,<>是标准的谓词,!>,!<,!=是标准的。我们应该尽量使用标准化的语法格式.
-
算术运算符在查询中的运用
select orderid, productid, qty, unitprice, discount, qty*unitprice*(1-discount) as val from Sales.OrderDetails; -
case 表达式
use [TSQL2012] --一般用法 select productid,productname,categoryid, case categoryid when 1 then 'Beverages' when 2 then 'x' when 3 then 'y' when 4 then 'i' else 'hh' end as categoryname from Production.Products; --加入计算逻辑的case语句 select orderid, custid, val, case when val<1000.00 then '少于1000' when val between 1000.00 and 3000.00 then '1000到3000之间' when val >3000.00 then '超过3000' else '未知' end as valuecategory from Sales.OrderValues; --case在条件查询中的运用 select col1,col2 from dbo.T1 where case when col1=0 then 'no' when col2/col1>2 then 'yes' else 'no' end ='yes' -
多表联查
I.left join(左链接)
select a.* from [表1] as a left join [表2】 as b
on a.字段名=b.字段名
where 条件
-
group by子句,实现分组查询
-
区分大小写的查询
--数据库默认不区分大小写查询,查询结果集有两个,rabbit,和Rabbit select name from dbo.userCenter where name='rabbit'; --区分大小写的查询,只查询出一个数据,rabbit。Rabbit被过滤掉了 select name from dbo.userCenter where name collate latin1_General_CS_AS=N'rabbit';
================常用系统函数=======================
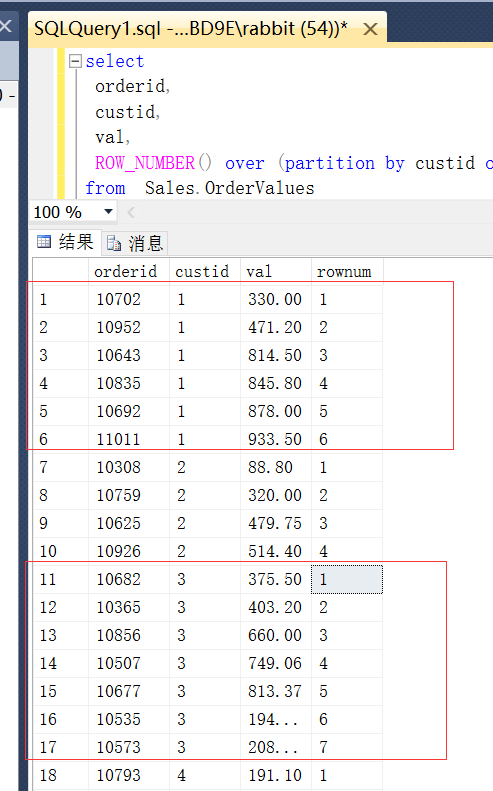
1.row_number()计算行号的。需要和over子句搭配,over子句需和order by子句搭配。主要可以对某个字段培训后,分组计算行号。示例sql,示例效果如下
sql示例:
select
orderid,
custid,
val,
ROW_NUMBER() over (partition by custid order by val) as rownum
from Sales.OrderValues
效果如下:
2.cast函数,强制转换输出的数据类型
示例如下
--使用cast函数将单价数据转为整型
select
orderid,
productid,
qty,
cast( unitprice as int) as price,
discount,
qty*unitprice*(1-discount) as val
from Sales.OrderDetails;3.coalesce支持两个或多个参数,isnull函数只支持两个参数,且前者还是标准的。建议使用前者
--coalesce(orderid,custid)返回多个参数中第一个非null的值。orderid若为null,则返回custid的值。若不为null,则返回orderid的值
use [TSQL2012]
select orderid,custid,coalesce(orderid,custid)
from Sales.OrderValues;4.IIF(<logical_expression>,<expr1>,<expr2>),
功能描述:如果logical_expression为true时,返回expr1,否则返回expr2.
示例
--IIF(<logical_expression>,<expr1>,<expr2>)
use [TSQL2012]
select orderid,custid,IIF(orderid<10249,custid,orderid)
from Sales.OrderValues;
*SUBSTRING(string,start,length)
功能描述:用于对输入的字符串string,从start位置开始,提取length个字符。(注意起始位置是1不是0)
实例:
--substring 函数用法示例
select SUBSTRING('abcde',1,2) as 子串;*LEFT(string,n) 和RIGHT(string,n)
功能描述:left函数作用是对输入的字符串string,提取坐起n个长度的子串。right函数的作用是对输入的字符串string,提取右起的n个长度的子串
示例:
--LEFT函数示例
select LEFT('abcdef',2);
--RIGHT函数示例
select RIGHT('abckdfasd',3);*CHARINDEX(substring,string[,start_pos])
返回子字符串(substring)在字符串(string)的第一次出现的位置。第三个参数如果被指定,则从字符串的指定起始位置开始匹配。如果不指定,则默认从0开始匹配。未找到则返回0.
--返回6
select CHARINDEX(' ','Itzik Ben-Gan')
--返回3
select CHARINDEX('bb','rabbit');
--返回3,不区分大小写
select CHARINDEX('B','rabbit');
--返回0
select CHARINDEX('d','rabbit');*PATINDEX(pattern,string)
描述:返回模式在字符串中第一次出现的位置
--有点类似正则表达式。返回5
select PATINDEX('%[0-9]%','abcd123efgh');*REPLACE(string,substring1,substring2)
描述:使用sub2替换string字符串中出现的所有sub1
--返回ab:cd:de
select replace ('ab-cd-de','-',':');*REPLICATE(string,n)
描述:string字符串按照指定的次数n重复连接后返回
--返回RabbitRabbit
select REPLICATE('Rabbit',2);*RTRM和LTRM
描述:分别表示返回删除尾随或者前面空格后的输入字符串
--去掉字符串右边尾部的空格
select RTRIM(' dfsd df ')
--去掉字符串左边尾部的空格
select LTRIM(' ddd ');
*LIKE谓词
通过通配符,对字符串进行模式匹配
示例:
--%通配符,百分号代表任意大小的字符串,包括空字符。like比substring优化
--以下示例,展示名字以D开头的员工
select empid,lastname
from HR.Employees
where lastname like N'D%'
--_(下划线) 通配符
--类似占位的意思,比如下面,则返回第二个字符是‘e‘的员工
select empid, lastname
from HR.Employees
where lastname like N'_e%';
--[<List of characters>]通配符
--方括号内带有的字符列表,代表单个字符必须是列表中指定的字符之一。
--下面的查询返回姓氏第一个带有A,或B,或C的员工
select empid,lastname
from HR.Employees
where lastname like N'[ABC]%'
--[^<character list or range>] 通配符
--方括号内又有插入符号,后跟一个字符列表或者字符范围(如[^A-E]),代表单个字符
--未在指定的字符列表或范围内。
--示例:姓氏的第一个字符不是字母A~E范围的雇员
select empid,lastname
from HR.Employees
where lastname like N'[A-E]%'
--对字符串包含有统配符进行搜索用[]括起来
select empid,lastname
from hr.Employees
where lastname like N'_[%]%';====================常见误区====================================
1.sql的同时操作,where条件的判断可以按任意顺序,sql根据成本估计来决定先运算那个逻辑条件。这一点是不同于编程的。
--常见误区,先判断col1不等于0,在判断相除的值大于2。
--但是sql的where条件是同时操作的,执行的顺序是任意的。会根据成本估计。
--而不是一成不变的从左到有的判断。一旦先判断col2/col1的值就会报错了
select col1,col2
from dbo.T1
where col1<> 0 and col2/col1 >2;
--正确做法
select col1,col2
from dbo.T1
where
case
when col1=0 then 'no'
when col2/col1>2 then 'yes'
else 'no'
end ='yes';=========================注意的小细节============================
* +号连接符链接字符串的时候,如果连接的是null,则整个结果就是null。
但是concat函数则不会,它会将null替换成空字符。
--使用+运算符连接字符串,如果连接时的NULL,则结果会为NULL
select
custid,country,region,city,
country+N''+region+N''+city as location
from Sales.Customers
--使用concat函数连接,如果碰到null,会将null替换成空字符. 但是注意concat函数只在sql server2012及其以上才有的.
select
custid,country,region,city,
concat(country,N','+region,N','+city) as loaction
from Sales.Customers
--如果有些版本太低,不能使用concat,可以用coalesce函数和+运算符混合使用达到要求
select
custid,country,region,city,
coalesce(country,'无')+N','+coalesce(region,N'无')+N','+coalesce(city,N'无')
from Sales.Customers















 99
99

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









