







1. MapReduce 的概念
MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于 hadoop 的数据分析应用”的核心框架;
MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 hadoop 集群上。
2. 为什么要 MapReduce
(1) 海量数据在单机上处理因为硬件资源限制,无法胜任;
(2) 而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度;
(3) 引入 MapReduce 框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将分布式计算中的复杂性交由框架来处理。
(4) mapreduce分布式方案考虑的问题
A、运算逻辑要不要先分后合?
B、程序如何分配运算任务(切片)?
C、两阶段的程序如何启动?如何协调?
D、整个程序运行过程中的监控?容错?重试?
分布式方案需要考虑很多问题,但是我们可以将分布式程序中的公共功能封装成框架,让开发人员将精力集中于业务逻辑上。而 MapReduce 就是这样一个分布式程序的通用框架。
3. MapReduce 的核心思想

上图简单的阐明了 map 和 reduce 的两个过程或者作用,虽然不够严谨,但是足以提供一个大概的认知,map 过程是一个蔬菜到制成食物前的准备工作,reduce 将准备好的材料合并进而制作出食物的过程。
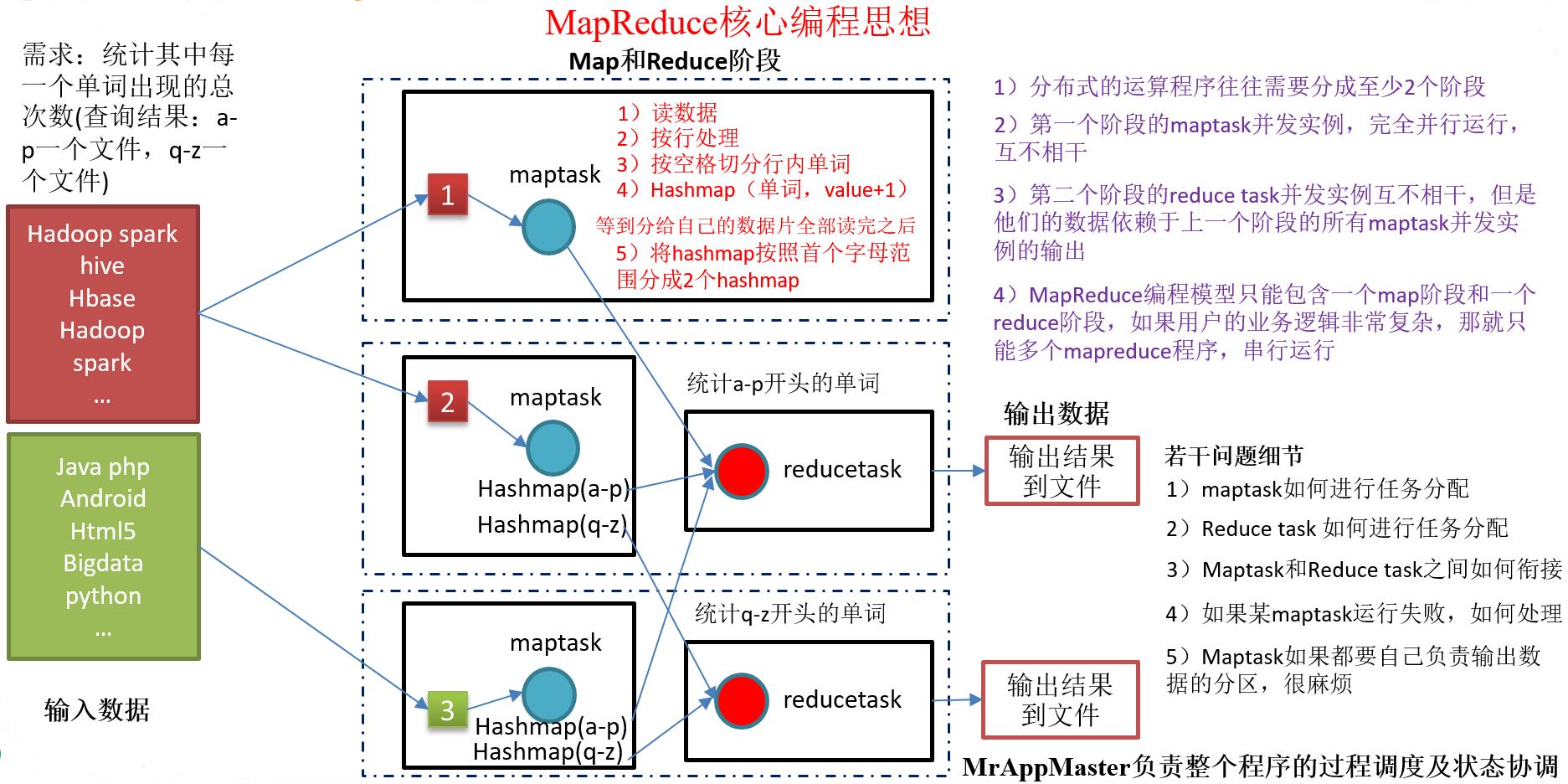
(1) 分布式的运算程序往往需要分成至少2个阶段;
(2) 第一个阶段的 maptask 并发实例,完全并行运行,互不相干;
(3) 第二个阶段的 reduce task 并发实例互不相干,但是他们的数据依赖于上一个阶段的所有 maptask 并发实例的输出;
(4) MapReduce 编程模型只能包含一个map阶段和一个 reduce 阶段,如果用户的业务逻辑非常复杂,那就只能多个 MapReduce 程序,串行运行。
4. MapReduce 进程
一个完整的 MapReduce 程序在分布式运行时有三类实例进程:
(1) MrAppMaster:负责整个程序的过程调度及状态协调;
(2) MapTask:负责map阶段的整个数据处理流程;
(3) ReduceTask:负责reduce阶段的整个数据处理流程。
5. MapReduce 编程规范
用户编写的程序分成三个部分:Mapper,Reducer,Driver (提交运行 MR 程序的客户端)
1. Mapper 阶段
(1)用户自定义的 Mapper 要继承自己的父类;
(2)Mapper 的输入数据是KV对的形式 ( KV 的类型可自定义)
(3)Mapper 中的业务逻辑写在 map() 方法中
(4)Mapper 的输出数据是KV对的形式 ( KV 的类型可自定义)
(5)map() 方法 ( maptask 进程)对每一个 <K,V> 调用一次
2. Reducer 阶段
(1)用户自定义的 Reducer 要继承自己的父类;
(2)Reducer 的输入数据类型对应 Mapper 的输出数据类型,也是 KV;
(3)Reducer 的业务逻辑写在 reduce() 方法中;
(4)Reducetask 进程对每一组相同k的<k,v>组调用一次 reduce() 方法。
3. Driver 阶段
整个程序需要一个 Drvier 来进行提交,提交的是一个描述了各种必要信息的 job 对象
6. MapReduce 程序运行流程
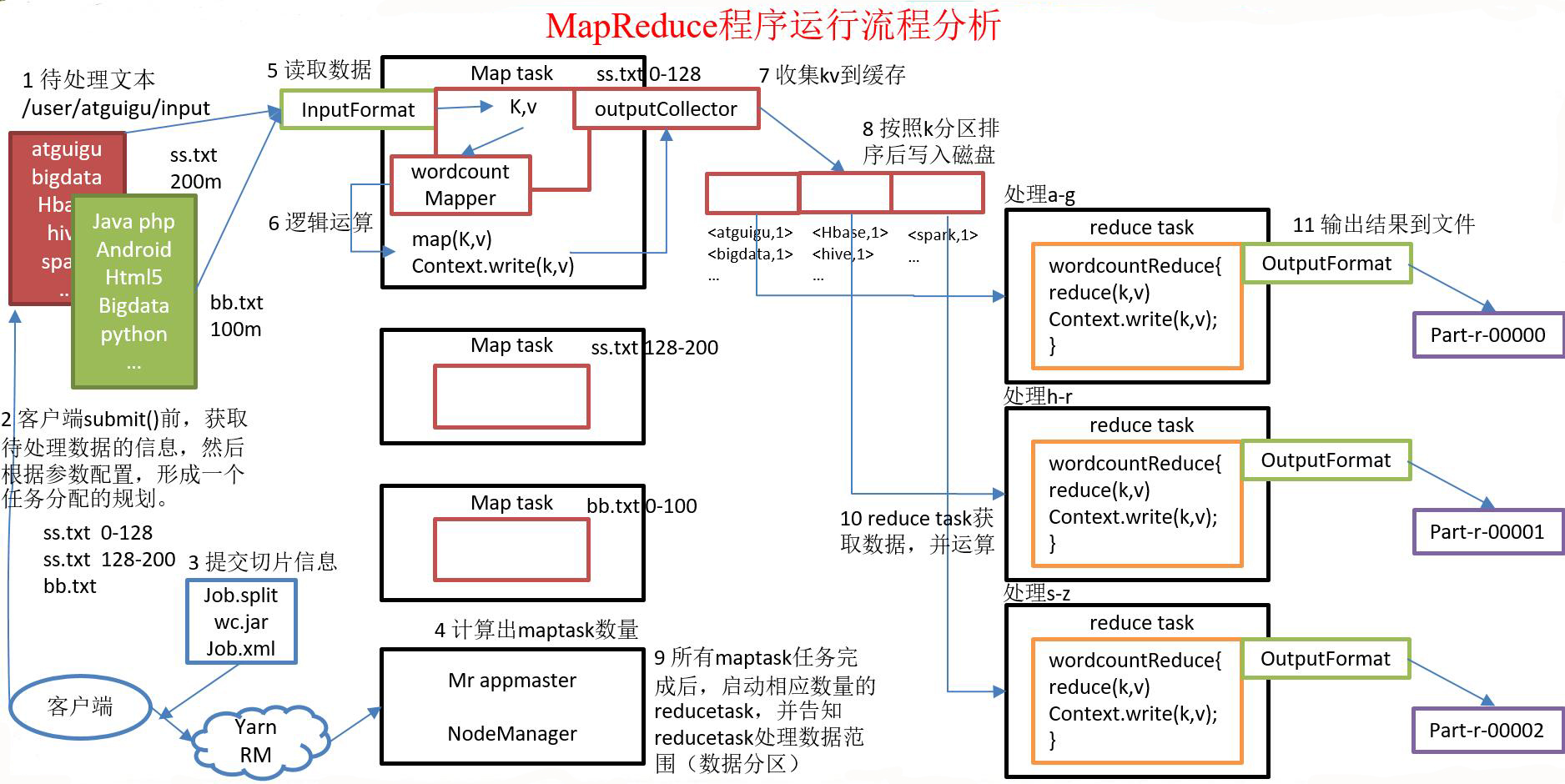
(1) 在 MapReduce 程序读取文件的输入目录上存放相应的文件;
(2) 客户端程序在 submit() 方法执行前,获取待处理的数据信息,然后根据集群中参数的配置形成一个任务分配规划;
(3) 客户端提交 job.split、jar 包、job.xml 等文件给 yarn,yarn 中的 resourcemanager 启动 MRAppMaster;
(4) MRAppMaster 启动后根据本次 job 的描述信息,计算出需要的 maptask 实例数量,然后向集群申请机器启动相应数量的 maptask 进程;
(5) maptask 利用客户指定的 inputformat 来读取数据,形成输入 KV 对;
(6) maptask 将输入 KV 对传递给客户定义的 map() 方法,做逻辑运算;
(7) map() 运算完毕后将 KV 对收集到 maptask 缓存;
(8) maptask 缓存中的 KV 对按照 K 分区排序后不断写到磁盘文件;
(9) MRAppMaster 监控到所有 maptask 进程任务完成之后,会根据客户指定的参数启动相应数量的 reducetask 进程,并告知 reducetask 进程要处理的数据分区;
(10) Reducetask 进程启动之后,根据 MRAppMaster 告知的待处理数据所在位置,从若干台 maptask 运行所在机器上获取到若干个 maptask 输出结果文件,并在本地进行重新归并排序,然后按照相同 key 的 KV 为一个组,调用客户定义的 reduce() 方法进行逻辑运算;
(11) Reducetask 运算完毕后,调用客户指定的 outputformat 将结果数据输出到外部存储。
本文为原创文章,如果对你有一点点的帮助,别忘了点赞哦!比心!如需转载,请注明出处,谢谢!














 403
403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









