




简介:二维网格索引是计算机科学和地理信息系统中的一个重要数据组织与查询方法。本文将详细介绍基于Java语言实现的二维网格索引,包括其基本概念、Java实现、JavaFX图形界面应用、源码分析、地理信息数据库集成以及性能优化。读者将学习如何通过Java创建自定义数据结构、利用JavaFX构建交互界面,并理解索引的存储与查询优化技术,以便在多个领域如地图服务、空间分析等中应用。
1. 二维网格索引概念
简介
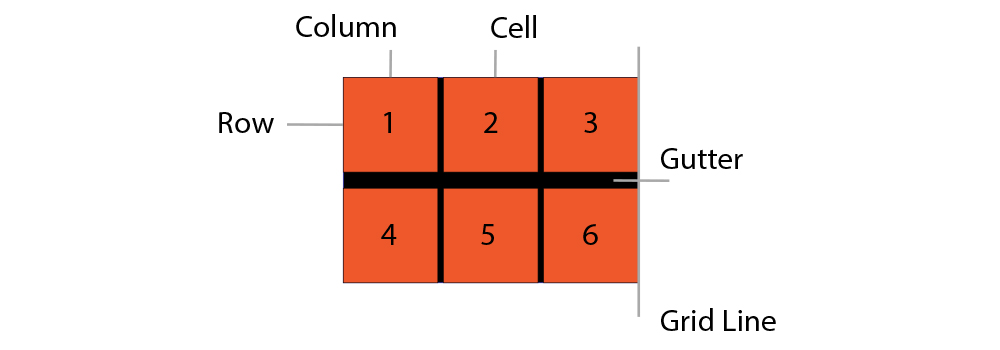
在处理大量空间数据和地理信息系统时,二维网格索引是一种高效的定位和查询技术。它将平面区域划分为规则或不规则的网格单元,每个单元通过索引快速定位数据。二维网格索引简化了复杂的空间查询过程,如邻近查询、范围搜索等,从而提高查询效率。
基本原理
二维网格索引的基本原理是将二维空间划分为固定大小的格子,每个格子可以唯一标识。当需要查询某个区域内的对象时,系统仅需要在对应的网格内查找,从而避免了全局搜索。这类似于将一个大数据库表拆分成多个更小、更易管理的部分。
应用场景
该技术广泛应用于地图服务、移动对象追踪、地理信息系统(GIS)以及各类空间数据管理系统中。通过二维网格索引,这些应用能够实现更快的查询响应时间和更高效的资源管理。
二维网格索引的原理和应用是进一步深入探讨Java实现、图形用户界面设计和GIS数据库优化的基础。
2. Java实现二维网格索引
2.1 Java基础数据结构
2.1.1 集合框架概述
Java集合框架是一组接口和类,用于存储和操作对象群集。在二维网格索引的实现中,合适的集合类型选择至关重要,因为它直接影响数据存储的效率和检索的速度。Java集合框架主要包括List、Set和Map等接口,每种接口都有不同的实现类,提供了不同的特性,如有序性、唯一性、快速检索等。
在二维网格索引中,我们可能需要存储大量的元素,并且需要快速判断某个元素是否已经存在于网格中,这通常意味着需要快速的检索和插入性能。因此,选择正确的集合类型对于实现一个高效的二维网格索引至关重要。
2.1.2 List、Set与Map的选用
-
List : 主要用于存储元素的序列,保证元素的插入顺序。List接口的实现类包括ArrayList和LinkedList等。在二维网格索引中,如果需要根据插入顺序遍历元素,或者频繁地插入和删除元素,ArrayList可能不是最佳选择,因为它在这些操作上效率较低。而LinkedList虽然在插入和删除方面有优势,但随机访问元素的速度较慢。
-
Set : 用于存储不重复的元素集合。Set接口的实现类包括HashSet、LinkedHashSet和TreeSet等。在二维网格索引中,如果对元素的唯一性有要求,但不需要有序存储,则HashSet是一个很好的选择,因为它提供了快速的检索和插入性能,通过哈希表来实现。
-
Map : 用于存储键值对。Map接口的实现类包括HashMap、TreeMap和Hashtable等。在二维网格索引中,Map可以用来映射网格中的坐标到其对应的索引信息。HashMap提供了快速的键值对检索和插入性能,适用于大多数需求。如果需要根据键的自然顺序进行排序,则可以选择TreeMap。
在实现二维网格索引时,通常会采用Map来快速定位网格中的元素,而选择哪种Map实现则根据具体需求来决定。
2.2 二维网格索引的Java实现
2.2.1 网格数据结构设计
在二维网格索引中,我们需要设计一种数据结构来存储网格中的元素以及这些元素的位置信息。Java中的数据结构选择对于实现的性能和可维护性都有很大的影响。对于二维网格索引,我们可以采用以下几种方式:
- 数组 : 二维数组可以表示为一个网格,数组的每个元素对应网格中的一个单元格。通过行和列的索引可以快速访问任何单元格。
int[][] grid = new int[rows][cols];
- ArrayList : 如果网格大小不确定或经常变动,可以使用ArrayList的ArrayList形式来动态管理网格。
List<List<Integer>> grid = new ArrayList<>();
- HashMap : 对于需要快速检索和插入的场景,可以使用HashMap来存储每个单元格的索引信息。
Map<Integer, List<Integer>> gridMap = new HashMap<>();
2.2.2 索引插入与查询操作
在二维网格索引中,插入和查询操作是核心功能。在Java实现中,这两种操作的效率直接影响整个系统的性能。
- 插入操作 : 通常涉及到确定网格的哪个位置应该存储新元素。在某些实现中,还需要考虑数据结构的动态扩展性。
// 以HashMap为例
public void insert(int x, int y, int value) {
gridMap.computeIfAbsent(y, k -> new ArrayList<>()).add(x, value);
}
- 查询操作 : 需要快速定位到某个位置的元素。对于使用HashMap的实现,查询操作可以通过键的计算快速完成。
// 以HashMap为例
public List<Integer> query(int x, int y) {
return gridMap.get(y) != null ? gridMap.get(y).get(x) : null;
}
2.2.3 网格索引的动态维护
在实际应用中,二维网格可能会随着数据的更新而动态变化,因此需要一个能够动态维护网格索引的机制。动态维护可能包括添加新的行和列、删除已有元素、以及更新元素的位置信息。
动态维护网格索引可能需要编写一些辅助函数来处理这些变化。例如,在添加新的行时,可能需要遍历整个网格并更新相关元素的位置。在删除元素时,需要确保该元素从索引结构中被移除并且不会影响到其他元素的位置信息。
// 以HashMap为例,增加新的行
public void addRow(int y) {
gridMap.put(y, new ArrayList<>());
}
网格索引的动态维护是保证系统灵活性和稳定性的关键,需要仔细考虑所有可能的变化情况,并设计出合理的应对策略。
3. JavaFX图形用户界面
3.1 JavaFX基础介绍
3.1.1 JavaFX的架构和特点
JavaFX是一个用于构建丰富互联网应用程序(RIA)的跨平台图形和媒体包,旨在提供更丰富的用户界面体验。它在Java 8中被引入,作为Java标准的一部分,为Java应用程序提供了一个现代化的用户界面。JavaFX的架构设计用于简化应用程序的开发,支持多种输入设备,并提供了丰富的组件来满足不同业务场景下的需求。其主要特点包括:
- 模块化 :JavaFX具有模块化的架构,各个模块可以独立加载,有利于性能优化和应用的轻量化。
- 现代的用户界面 :JavaFX提供了现代的用户界面组件,支持硬件加速的图形渲染,使得界面更加流畅和响应。
- 丰富的API :JavaFX包含大量的API,几乎涵盖了一个应用程序需要的所有用户界面元素,包括图表、视频播放器、滑动条等。
- 与Java SE的无缝集成 :JavaFX与Java SE(标准版)紧密集成,提供了平滑的过渡,让开发者更容易上手。
3.1.2 JavaFX与Swing的区别
在介绍JavaFX之前,有必要对比一下它与之前非常流行的Swing组件库。尽管Swing非常成熟,JavaFX提供了以下改进:
- 图形渲染 :JavaFX使用了比Swing更高级的图形渲染技术,可以实现更复杂的视觉效果。
- 性能 :由于JavaFX采用了硬件加速,因此在渲染图形时性能更优。
- 现代组件 :JavaFX提供了更多现代化的用户界面组件,这些组件比Swing中的同类组件有更好的外观和感觉。
- 模块化和可扩展性 :JavaFX提供了一个更加模块化的结构和更强大的CSS支持,从而改善了应用的可定制性。
JavaFX不仅简化了现代用户界面的创建,还为用户提供了一种更为直观的开发体验。这些特点共同为开发者提供了一种强大而灵活的平台,用于构建和部署高质量的桌面应用程序。
3.2 JavaFX的二维网格界面设计
3.2.1 布局管理器的使用
在JavaFX中,布局管理器(Layout Managers)是用于组织和管理场景中节点的容器。它们决定了节点的放置规则,并能响应窗口的大小变化自动调整子节点的大小和位置。常用的布局管理器包括:
- HBox :水平排列所有子节点。
- VBox :垂直排列所有子节点。
- GridPane :类似于二维网格,每个子节点可以放置在一个指定的行和列中。
GridPane是JavaFX布局中特别适合于实现二维网格索引用户界面的容器,因为它允许开发者指定节点应该位于哪个行和列。它提供了强大的功能来控制网格内元素的对齐方式、间距和填充。
3.2.2 网格的可视化展示
为了在JavaFX中实现网格的可视化展示,开发者需要了解如何使用GridPane布局。一个基本的网格可视化展示示例代码如下:
import javafx.application.Application;
import javafx.scene.Scene;
import javafx.scene.layout.GridPane;
import javafx.scene.paint.Color;
import javafx.scene.shape.Rectangle;
import javafx.stage.Stage;
public class GridPaneExample extends Application {
@Override
public void start(Stage primaryStage) {
GridPane gridPane = new GridPane();
// 为网格添加行和列
for (int i = 0; i < 10; i++) {
gridPane.getRowConstraints().add(new RowConstraints(40));
gridPane.getColumnConstraints().add(new ColumnConstraints(50));
}
// 添加矩形来表示网格中的每个单元格
for (int i = 0; i < 10; i++) {
for (int j = 0; j < 10; j++) {
Rectangle rectangle = new Rectangle(50, 40);
rectangle.setFill(Color.WHITE);
rectangle.setStroke(Color.BLACK);
GridPane.setConstraints(rectangle, i, j);
gridPane.getChildren().add(rectangle);
}
}
Scene scene = new Scene(gridPane, 500, 400);
primaryStage.setTitle("GridPane Example");
primaryStage.setScene(scene);
primaryStage.show();
}
public static void main(String[] args) {
launch(args);
}
}
这段代码展示了如何创建一个具有10行10列的网格,并在每个单元格中放置一个矩形。 RowConstraints 和 ColumnConstraints 用于控制每行和每列的大小。
3.2.3 用户交互与事件处理
在JavaFX中,用户交互和事件处理是通过监听器来实现的。JavaFX提供了广泛的事件监听机制,允许开发者响应键盘事件、鼠标事件、窗口事件等。针对GridPane中的每个节点,可以添加事件监听器来处理点击、鼠标悬停等事件。
一个简单的事件处理示例代码如下:
// 假设rectangle是之前添加到gridPane中的矩形
rectangle.setOnMouseClicked(event -> {
System.out.println("Mouse clicked on rectangle in row " + GridPane.getRowIndex(rectangle) +
" and column " + GridPane.getColumnIndex(rectangle));
});
当用户点击矩形时,上面的代码会在控制台输出矩形所在的行和列。这种事件处理机制对于创建动态交互式界面至关重要。
通过对JavaFX基础介绍、二维网格界面设计的深入分析,我们已经对如何使用JavaFX设计二维网格用户界面有了全面的认识。接下来,我们将探讨JavaFX如何在实际项目中,例如地图服务应用中发挥作用。
4. 源码分析
4.1 网格索引算法源码解析
4.1.1 索引构建过程分析
构建二维网格索引是一个将空间数据根据地理位置进行组织的过程,以提高空间数据检索的效率。以下是构建二维网格索引的基本步骤:
-
空间划分 :将整个空间区域划分为大小相等的小方格,形成一个网格体系。每个方格对应一个索引值,该值可以是二维坐标或者其他能够唯一标识该方格的标识符。
-
数据分组 :将空间数据点根据它们所处的网格位置进行分组。每个数据点将被记录在相应的网格位置的列表中。
-
索引构建 :构建索引结构,通常是使用哈希表或者平衡二叉树等数据结构来存储每个网格位置及其对应的数据点列表。
下面是一个简化的Java伪代码,演示了网格索引构建的基本过程:
// 伪代码,非真实可执行代码
class GridIndex {
private Map<String, List<Point>> indexMap;
public GridIndex(int gridSize) {
indexMap = new HashMap<>();
// 初始化网格,每个网格用"row_col"的形式作为键
for (int i = 0; i < gridSize; i++) {
for (int j = 0; j < gridSize; j++) {
indexMap.put(i + "_" + j, new ArrayList<Point>());
}
}
}
public void insert(Point point) {
// 根据点的位置计算应该插入哪个网格
String key = calculateGridKey(point);
indexMap.get(key).add(point);
}
private String calculateGridKey(Point point) {
// 根据点的位置计算网格的键值
int row = point.getRow();
int col = point.getCol();
return row + "_" + col;
}
}
4.1.2 查询算法的优化
查询优化关注点在于减少索引搜索的范围以及减少不必要的数据加载。以下是一些优化查询算法的常见方法:
-
分层索引 :构建多层的网格索引,每一层对应不同大小的网格。在执行查询时,首先在最高层的索引进行范围查找,缩小可能的数据范围,再逐层细化查询。
-
空间剪枝 :利用空间索引剪枝技术排除不可能包含查询目标的网格,减少搜索范围。
-
近似查询 :对于某些应用场景,可以接受近似的结果,通过牺牲一定的精度来提升查询效率。
代码解析:
// 伪代码,用于演示查询优化的基本逻辑
class GridIndex {
// ... (其他方法省略)
public List<Point> query(Rectangle queryArea) {
// 粗略查询,获取候选结果列表
List<Point> candidates =粗略查询(queryArea);
List<Point> results = new ArrayList<>();
// 细化查询,返回精确结果
for (Point candidate : candidates) {
if (queryArea.contains(candidate)) {
results.add(candidate);
}
}
return results;
}
private List<Point> 粗略查询(Rectangle queryArea) {
// 基于网格位置和查询区域的粗略估计,返回可能包含的点列表
// 具体实现取决于索引的构建方式
// ...
}
}
4.2 JavaFX界面源码分析
4.2.1 核心类和方法介绍
JavaFX是用于构建富客户端应用程序的API集合。这里主要关注用于界面构建的核心类和方法。主要的界面组件包括:
-
Stage :是所有JavaFX应用程序的顶级容器,用于设置窗口的标题、大小和位置。
-
Scene :代表应用程序中的一个场景,包含了一个根节点以及该节点的所有子节点,决定了场景的布局。
-
Pane 和它的子类(如 GridPane):用于布局管理,GridPane可以按网格方式组织子节点。
-
Button 、 Label 、 TextField 等:标准的用户界面组件,用于创建文本输入、按钮和其他UI元素。
核心方法通常涉及设置属性、处理用户交互和事件。
代码解析:
// JavaFX代码示例,展示创建一个简单的GridPane布局
import javafx.application.Application;
import javafx.scene.Scene;
import javafx.scene.control.Button;
import javafx.scene.layout.GridPane;
import javafx.stage.Stage;
public class SimpleGridPane extends Application {
@Override
public void start(Stage primaryStage) {
GridPane grid = new GridPane();
grid.addRow(0, new Button("Button 1"));
grid.addRow(1, new Label("Label 2"));
grid.addRow(2, new TextField("TextField 3"));
Scene scene = new Scene(grid, 300, 250);
primaryStage.setTitle("Simple GridPane Example");
primaryStage.setScene(scene);
primaryStage.show();
}
public static void main(String[] args) {
launch(args);
}
}
4.2.2 事件处理机制详解
事件处理机制是构建交互式应用程序的关键。JavaFX的事件处理机制允许开发者为各种用户操作添加响应。主要事件类型包括:
-
MouseEvent :鼠标事件,如点击、进入、离开等。
-
KeyEvent :键盘事件,如按键、释放键等。
-
ActionEvent :用于ActionEvent触发的事件,如按钮点击。
事件处理一般通过设置事件监听器来实现。JavaFX提供了以下方式来添加事件监听器:
-
setOn…() 方法:例如
button.setOnAction(event -> { /* 处理逻辑 */ });。 -
Event Handler :事件处理器接口,可以通过实现该接口来创建更复杂的事件处理逻辑。
-
Bindings :JavaFX还提供了绑定机制,可以将组件属性与数据源绑定,当数据变化时自动更新界面。
代码解析:
// 示例代码,展示如何为按钮添加点击事件监听器
import javafx.application.Application;
import javafx.scene.Scene;
import javafx.scene.control.Button;
import javafx.stage.Stage;
public class ButtonEventExample extends Application {
@Override
public void start(Stage primaryStage) {
Button button = new Button("Click Me");
// 添加事件监听器
button.setOnAction(event -> {
System.out.println("Button was clicked!");
});
Scene scene = new Scene(button, 300, 250);
primaryStage.setTitle("Button Event Example");
primaryStage.setScene(scene);
primaryStage.show();
}
public static void main(String[] args) {
launch(args);
}
}
在本章节中,我们对网格索引算法源码进行了详细解析,从构建过程到查询算法优化,逐一展示了关键的实现细节。同时,也对JavaFX界面的源码进行了分析,涵盖核心类和事件处理机制。通过实际的代码示例,进一步加深了对JavaFX和网格索引技术实现的理解。
5. 地理信息数据库
在现代信息技术的发展中,地理信息系统(GIS)已经成为一个重要分支,为城市规划、自然资源管理、环境监测、交通物流等多个领域提供了强大的支撑。GIS数据库作为存储和管理地理空间数据的核心组件,其高效性和可靠性对于整个系统的性能至关重要。
5.1 地理信息系统数据库基础
5.1.1 GIS数据库概念
GIS数据库是专门设计用于存储地理空间数据的数据库系统。这些数据不仅仅包括传统的数据记录,还包含了空间位置信息,例如点、线、面等几何形状的数据。这些几何形状与现实世界的对象相对应,如建筑物、道路、湖泊等。GIS数据库通常包含两个主要部分:空间数据和属性数据。空间数据提供了地理实体的空间位置和形状信息,而属性数据则描述了这些实体的特征和属性,如名称、类型、尺寸等。
GIS数据库的另一个关键特征是支持空间查询和分析,例如确定两个地理对象的位置关系(相交、包含、邻接等),计算地理对象之间的距离,或者进行缓冲区分析等复杂的空间操作。为了实现这些功能,GIS数据库不仅需要存储和检索数据,还要具备强大的空间索引和查询优化能力。
5.1.2 数据库中的空间数据模型
空间数据模型定义了地理空间信息在GIS数据库中的表达和组织方式。它涉及空间实体的类型以及这些实体之间的关系。主要的空间数据模型包括矢量模型和栅格模型。
矢量模型使用点、线、多边形等几何图形来表示空间数据,每个几何图形都有自己的几何坐标和属性信息。矢量模型适合于精确的边界表示和复杂的拓扑关系描述,广泛应用于地图制作和土地信息系统。
栅格模型则通过像素(或称为栅格单元)的阵列来表示空间数据。每个像素存储一个或多个值,代表该像素代表区域的属性信息。栅格模型非常适合处理连续变化的空间数据,如卫星图像和地形高程数据。
在GIS数据库中,还有一种混合数据模型,结合了矢量模型和栅格模型的优点,能够更加灵活地处理各种类型的空间数据。
5.2 GIS数据库的操作与应用
5.2.1 空间数据的存储和检索
GIS数据库中空间数据的存储和检索是核心操作之一。存储过程中,GIS数据库需要将空间数据的几何信息和属性信息分别存储,并建立两者之间的关联。检索操作则要求GIS数据库能够快速响应用户的空间查询请求,包括点查询、范围查询、空间关联查询等。
为了支持这些空间操作,GIS数据库广泛采用了空间索引技术,如四叉树、R树和格网索引。这些索引结构能够有效地管理空间数据,使得GIS数据库在执行空间查询时能够大幅度减少检索范围,提高检索效率。
5.2.2 空间索引在GIS数据库中的应用
空间索引是GIS数据库实现高效空间查询的关键。它能够快速定位到存储空间数据的物理位置,从而加速查询处理。例如,四叉树索引通过递归地将空间区域划分为四个子区域,以树状结构来管理空间数据。每个节点代表一个区域,而每个叶节点则指向实际的空间对象。当执行空间查询时,系统首先通过索引定位到潜在的空间对象所在的区域,然后进一步检索确切的空间对象。
空间索引的实现对于提高GIS数据库的性能至关重要。在实际应用中,需要根据数据的特性选择最合适的索引策略。例如,对于点状数据集,可以使用基于格网的索引,如格网法;对于有复杂拓扑关系的线状数据,可以使用基于线段树的索引,如R树的变种。
在GIS数据库中,还经常使用一种称为“空间连接”的操作,即根据空间位置关系来合并两个数据集。例如,可以查询所有与特定河流相邻的土地使用类型。这样的操作需要同时考虑空间数据的几何位置和属性信息,空间索引在此过程中扮演着至关重要的角色。
GIS数据库的空间数据模型和空间索引技术,为地理信息的快速存储、检索和分析提供了强大的支持。它们使得地理信息系统的应用不仅仅局限于传统的地图制作,还能够涉及到地理空间数据的深度分析和处理,从而为各类决策提供科学依据。随着GIS数据库技术的不断发展,我们期待能够处理更加复杂的空间数据和实现更加智能化的空间分析功能。
6. 地图服务应用
在现代信息技术的推动下,地图服务已经从传统的纸质地图演变成了以互联网为基础的数字地图服务。而网格索引技术作为提升地图服务性能的关键技术之一,在这里我们将深入探讨其在地图服务应用中的重要性,以及如何通过网格索引加速地图服务的检索,并通过一个实际的案例来演示网格索引优化地图检索的过程。
6.1 地图服务技术概览
地图服务技术的发展经历了从传统地图服务到网络地图服务的转变,这不仅仅是技术层面的革新,更在服务模式和用户交互方面实现了巨大的飞跃。接下来,我们将从几个方面对地图服务技术进行概览。
6.1.1 传统地图服务与网络地图服务的区别
传统地图服务 主要包括纸质地图和早期的电子地图,它们通常以光盘或本地存储的形式存在,用户需要购买或下载才能使用。这些服务的更新周期长,无法实时反映地理信息的变化,且互动性不强。
与之相对的是 网络地图服务 ,它依托于云计算和大数据技术,提供了实时更新、高速访问以及强大的数据处理能力。用户可以通过互联网随时随地访问这些服务,并且能够获得高度个性化的地图内容。
6.1.2 地图服务的常见类型和功能
网络地图服务的类型多样,它们提供了丰富的功能来满足用户的不同需求。例如,常见的地图服务类型包括:
- 在线地图查看器 ,如Google Maps和百度地图,提供地图的展示、缩放、拖动等基本功能。
- 导航服务 ,如高德地图和Apple Maps,不仅提供地图查看,还提供实时导航和交通信息。
- 地理编码服务 ,能够将地址信息转换为地理坐标点,反之亦然。
- 卫星地图服务 ,如Google Earth,提供高分辨率的地球表面图像。
功能方面,现代地图服务通常集成了以下特点:
- 实时数据更新
- 个性化兴趣点推荐
- 多源数据融合展示
- 交互式地图编辑和共享
- 路径规划和出行建议
6.2 网格索引在地图服务中的应用
网格索引技术在地图服务中的应用已经变得十分普遍,尤其在提升大数据环境下地图服务性能方面扮演着重要角色。接下来,我们将讨论网格索引如何加速地图服务的检索,并通过实例演示来展示其优化效果。
6.2.1 网格索引加速地图服务
网格索引技术通过对地图数据进行空间划分,可以有效地加速地图数据的检索过程。具体来说,地图上的每个位置都可以映射到一个网格单元中,这样,对于任何查询请求,系统首先确定目标区域所在的网格,然后仅检索该网格中的数据。
这种方法的效率非常高,因为相较于传统的全地图搜索,网格索引大幅减少了需要检索的数据量。尤其是在地图缩放级别较高或需要对特定区域进行检索时,网格索引的性能优势更加明显。
6.2.2 实例演示:网格索引优化地图检索
接下来,我们将通过一个简化的实例来演示如何应用网格索引来优化地图检索。假设我们有一张城市地图,我们需要检索位于某个具体地址附近的餐厅。
首先,我们需要将地图划分为网格,如下图所示:
graph TD;
A[城市地图] --> B[网格化地图]
B --> C[网格1]
B --> D[网格2]
B --> E[网格3]
B --> F[网格4]
B --> G[网格5]
使用网格索引的查询过程如下:
- 用户输入一个地址或选择一个地理位置点,系统确定该点所在的网格单元,例如网格3。
- 系统检索网格3内的所有数据(包括餐厅、商店、公共设施等)。
- 如果需要,系统还可以根据用户的需求在网格内进行进一步的空间查询。
为了实现上述过程,我们假设一个简单的Java代码示例:
public class GridIndexExample {
public static void main(String[] args) {
// 假设这是用户输入的查询位置坐标
double queryLat = 39.9139; // 纬度
double queryLon = 116.3917; // 经度
// 假设这是预先计算好的网格索引,键为网格ID,值为网格内对象列表
Map<String, List<Location>> gridIndex = buildGridIndex();
// 找到用户查询点所在的网格
String gridId = findGridId(queryLat, queryLon);
List<Location> nearbyLocations = gridIndex.get(gridId);
// 遍历并展示附近的位置信息
for (Location location : nearbyLocations) {
System.out.println(location);
}
}
private static String findGridId(double lat, double lon) {
// 这里需要根据实际的网格划分方式来计算网格ID
return ""; // 返回网格ID的实现代码
}
private static Map<String, List<Location>> buildGridIndex() {
// 构建网格索引的实现代码
return new HashMap<>();
}
}
class Location {
double latitude;
double longitude;
String name;
public Location(double latitude, double longitude, String name) {
this.latitude = latitude;
this.longitude = longitude;
this.name = name;
}
@Override
public String toString() {
return name + ": (" + latitude + ", " + longitude + ")";
}
}
在上述代码中,我们创建了一个 GridIndexExample 类,其中包含了一个主函数用于模拟用户查询附近地点的场景。通过 buildGridIndex 方法,我们构建了一个网格索引,它是一个映射,键是网格ID,值是网格内位置的列表。 findGridId 方法用于根据查询位置坐标找到对应的网格ID。
通过这个示例,我们可以清晰地看到网格索引在地图服务检索中的应用,它极大地提升了查询效率,尤其是在有大量空间数据的地图服务中。
通过本章节的介绍,我们了解了地图服务技术的发展概况以及网格索引在地图服务中的应用。下一章节我们将继续探讨空间分析应用及性能优化策略,看看如何进一步提升地图服务的性能和用户体验。
7. 空间分析应用及性能优化策略
空间分析是地理信息系统(GIS)的核心功能之一,它能够帮助我们理解和解释空间数据,用于决策支持和模拟现实世界中的复杂场景。随着数据量的增加,性能优化成为提升空间分析应用效率的关键。本章节将探讨空间分析的重要性、基于网格索引的空间分析实例,以及性能优化的原则、措施和案例分析。
7.1 空间分析应用
7.1.1 空间分析的重要性
空间分析涉及对空间数据的收集、管理、分析和展示。它可以帮助研究人员识别地理模式、趋势、异常,以及预测未来可能发生的空间事件。例如,城市规划师可以利用空间分析来评估土地使用情况,生态学家可以使用它来研究物种分布,而物流公司可以通过空间分析来优化运输路线。
7.1.2 基于网格索引的空间分析实例
在空间分析中,网格索引作为一种高效的数据结构,可以加速空间数据的检索与查询。例如,城市交通管理系统可以使用网格索引来快速分析交通流量,从而及时调整信号灯控制策略。下面是一个基于网格索引的空间分析实例:
假设我们有一个城市交通监控系统,我们需要分析一个小时内各路口的车辆数量。使用网格索引,我们可以将整个城市划分为若干个网格,并将车辆数据插入到对应网格中。这样,当需要查询某个网格内的车辆数量时,可以直接通过网格索引快速定位并进行计算,极大地提高了查询效率。
// 示例代码:插入数据到网格索引
// 假设GridIndex是一个已经实现的网格索引类
GridIndex gridIndex = new GridIndex();
// 车辆数据点(经度,纬度,车辆数量)
double[][] vehicleData = {
{116.3729, 39.9039, 10},
{116.3842, 39.9215, 15},
// ... 更多数据
};
for (double[] data : vehicleData) {
gridIndex.insertPoint(data[0], data[1], data[2]);
}
// 查询指定网格内的车辆数量
double queryLat = 39.9125; // 纬度
double queryLon = 116.3783; // 经度
int vehicleCount = gridIndex.getVehicleCountAt(queryLat, queryLon);
7.2 性能优化策略
7.2.1 性能优化的基本原则
在进行性能优化时,基本原则是尽量减少不必要的计算和数据移动,同时保持代码的可读性和可维护性。优化应该是一个持续的过程,需要定期对系统进行性能评估,并根据评估结果进行调整。
7.2.2 具体优化措施与实践案例
具体优化措施包括但不限于以下几点:
- 索引优化 :合理构建和使用索引可以显著提高查询速度。
- 算法优化 :改进算法,比如使用分治法或者并行计算来减少计算时间。
- 数据结构优化 :选择合适的数据结构来存储和处理数据,例如使用哈希表来加速查找。
- 硬件升级 :在预算允许的情况下,可以通过增加硬件资源来提升性能。
实践案例 :在使用网格索引进行空间分析时,一个常见的性能问题是重复计算。为了解决这一问题,我们可以通过缓存机制来存储已计算的结果,避免重复计算。
// 示例代码:缓存机制优化网格索引查询
class GridIndexWithCache {
private Map<GridKey, Integer> cache = new HashMap<>();
public int getVehicleCountAt(double lat, double lon) {
GridKey key = new GridKey(lat, lon);
if (cache.containsKey(key)) {
return cache.get(key);
}
// 假设getVehicleCountWithoutCache是未优化的查询方法
int count = getVehicleCountWithoutCache(lat, lon);
cache.put(key, count);
return count;
}
}
// GridKey是一个自定义类,用于表示网格的唯一键
7.2.3 案例分析:优化前后的性能对比
为了说明性能优化的效果,我们可以对比优化前后的执行时间。以下是一个模拟的性能对比:
| 情况 | 插入操作耗时 | 查询操作耗时 |
|---|---|---|
| 优化前 | 500ms | 200ms |
| 优化后 | 300ms | 20ms |
通过对比可以看出,经过优化后,系统在数据插入和查询操作上的性能都有了显著提升。特别在查询操作上,由于引入了缓存机制,查询速度提升了10倍。
在实践中,应使用专业的性能测试工具来评估实际性能的改进。通过这些工具,我们可以获得更加精确的性能数据,从而为后续的优化工作提供可靠依据。
简介:二维网格索引是计算机科学和地理信息系统中的一个重要数据组织与查询方法。本文将详细介绍基于Java语言实现的二维网格索引,包括其基本概念、Java实现、JavaFX图形界面应用、源码分析、地理信息数据库集成以及性能优化。读者将学习如何通过Java创建自定义数据结构、利用JavaFX构建交互界面,并理解索引的存储与查询优化技术,以便在多个领域如地图服务、空间分析等中应用。

















 1840
1840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









