






原标题:用python实现截屏识别其中的文字
大家好,欢迎来到 Crossin的编程教室 !
你一定用过那种“OCR神器”,可以把图片中的文字提取出来,极大的提高工作效率。
下次,当你想要复制“百度文库”中的内容时,不妨试试这个程序。
效果预览
源码解析
1)等待用户截图
此处需要借助贴图神器( Snipaste)
其中“f1”是截图的快捷键 ,“ctrl+c”是把截图保存到剪贴板的快捷键。
如果使用qq截图的话,需要把快捷键改为对应的“ctrl+alt+c”和“enter”
顺便安利一波Snipaste,
必备效率神器
importkeyboard
# 利用截图软件(Snipaste)截图到剪贴板
# 输入键盘的触发事件
keyboard.wait(hotkey= "f1")
keyboard.wait(hotkey= "ctrl+c")
time.sleep( 0.1)
上面这段代码执行之后,现在已经有一张图片等待在剪贴板里了。
说明:这里的 keyboard.wait 是为了让程序等待用户进行截屏操作。如果在你的系统上无法识别组合键,你也可以自定义一个按键(比如 keyboard.wait(hotkey="q") )作为通知程序完成截屏的确认。
2)保存截图
利用PIL模块的ImageGrab,可以把剪贴板里的那张图片,保存到当前的目录下,并命名为“screen.png”
fromPIL importImageGrab
# 把图片从剪切板保存到当前路径
image = ImageGrab.grabclipboard
image.save( "screen.png")
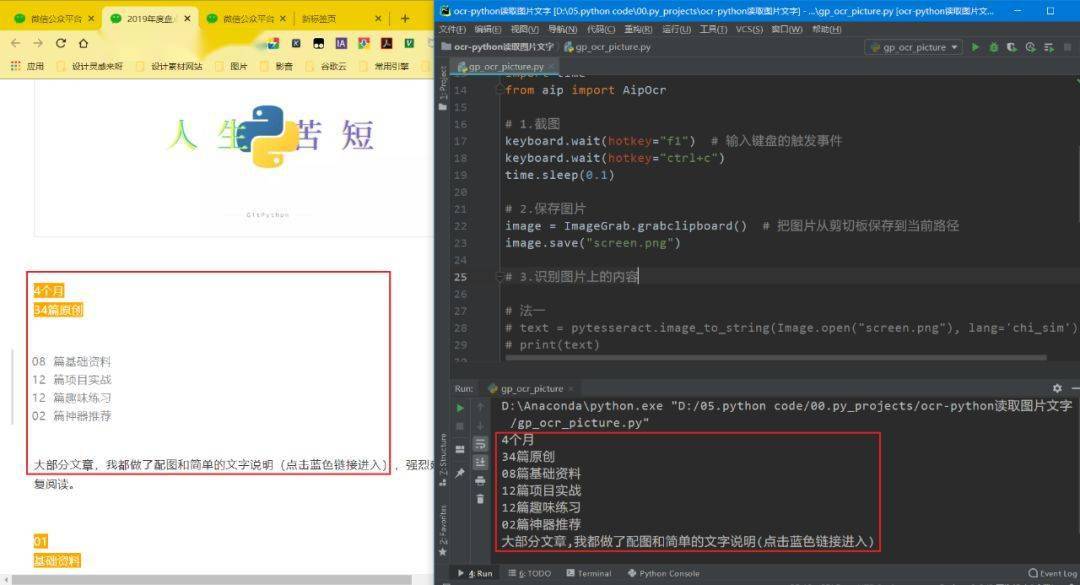
3)识别截图中的文本
法一
pytesseract模块
优点:免费,易用
缺点:识别效果很一般,准确率不高
使用方法介绍:
1) 安装 pytesseract库
pip install pytesseract
2) 安装 tesseract-ocr.exe 配置环境变量
3) 修改pytesseract.py文件,将tesseract_cmd指向Tesseract-OCR的tesseract.exe的绝对路径。
安装配置完成后,在代码中执行:
importpytesseract
fromPIL importImage
# 法一:利用pytesseract模块
# 参数一:图片
# 参数二:简体中文
text = pytesseract.image_to_string(Image.open( "screen.png"), lang= 'chi_sim')
print(text)
来看看效果:
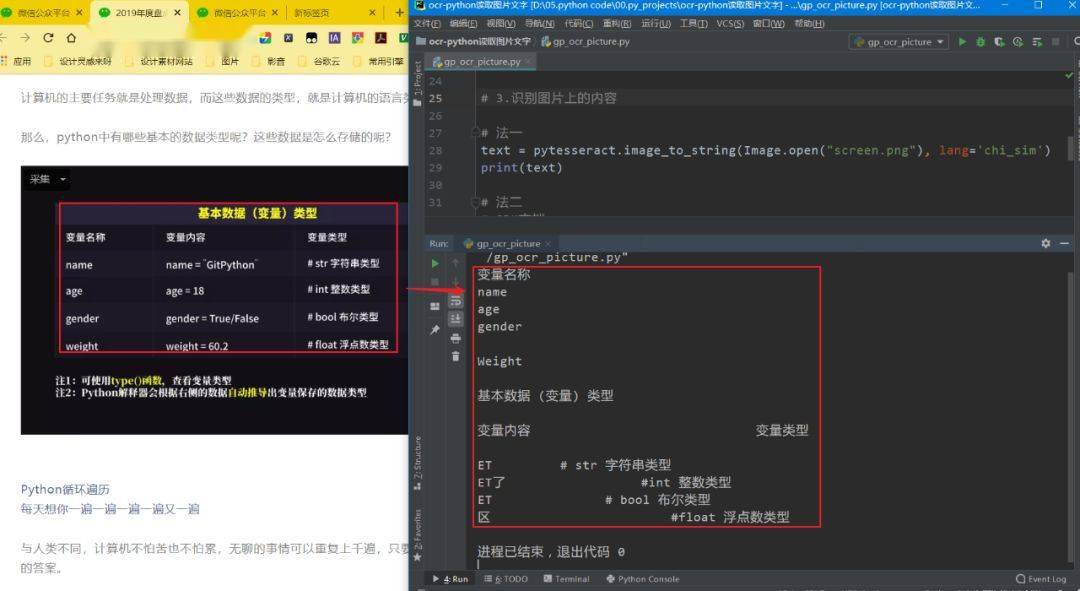
low的不行……(对于简单的标准字体还能凑合)
要想精度高,还得想别的办法。
法二
百度API接口
AI开放平台文档中心
https://ai.baidu.com/ai-doc
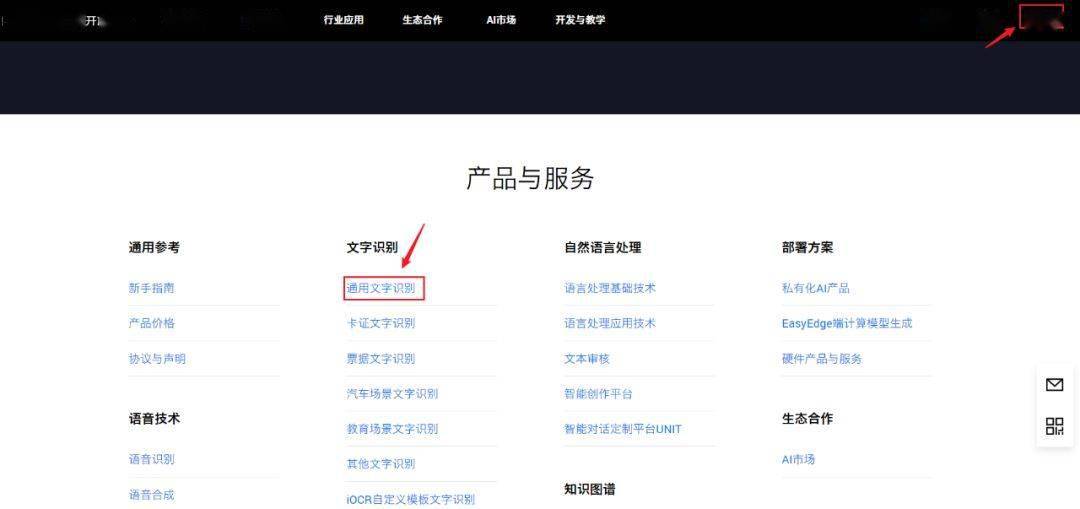
查看python语言的SDK文档
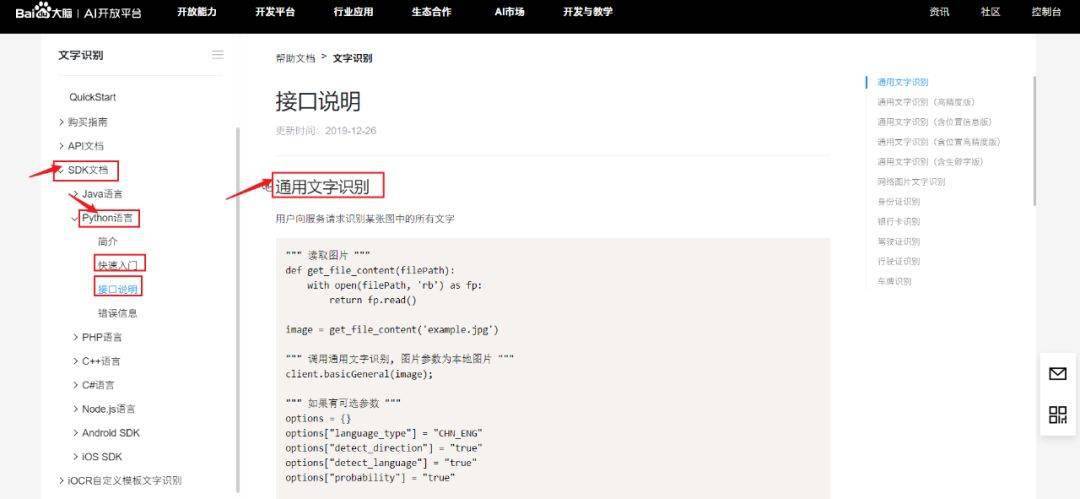
点击右上角(控制台),登录自己的百度账号,创建“文字识别”的应用
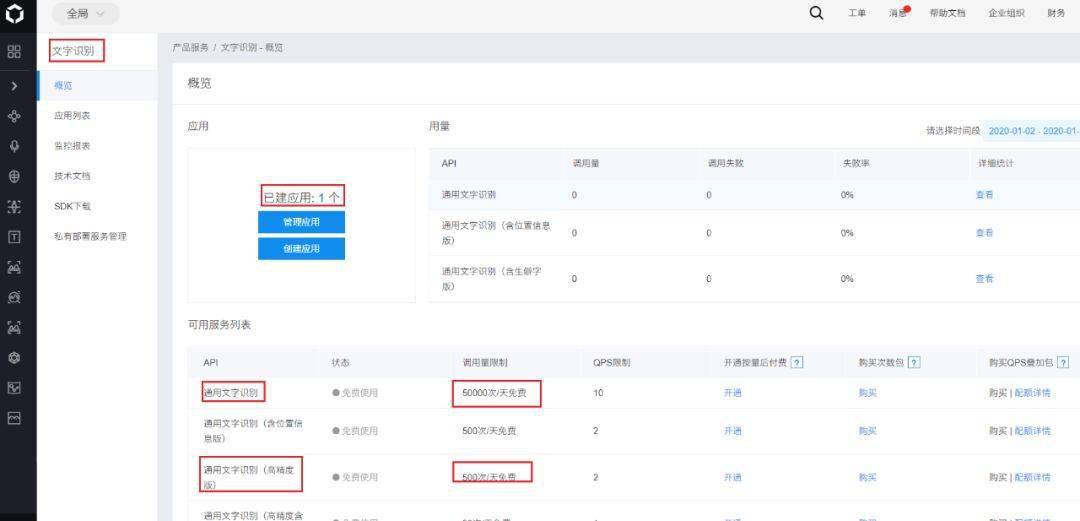
这里我们使用百度的AI库来简化调用。需安装:
pipinstall baidu_aip
importpytesseract
fromaip importAipOcr
fromPIL importImageGrab
# 法二:利用百度API
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
# 读取图片
withopen( "screen.png", 'rb') asf:
image = f.read
# 调用百度API通用文字识别(高精度版),提取图片中的内容
text = client.basicAccurate(image)
result = text[ "words_result"]
fori inresult:
print(i[ "words"])
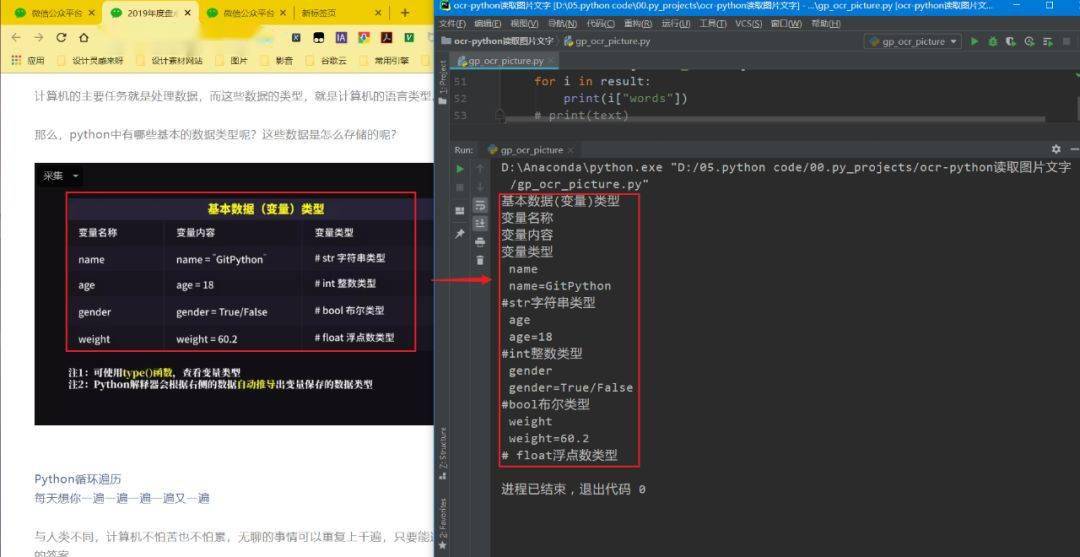
结果如文章首图:
我是总结
代码步骤:
1)等待用户截图
2)保存截图到当前目录
3)识别截图中的文本
其中识别截图文本,有两种方法:
1)利用 pytesseract 模块
2)利用百度API接口
参考代码地址:
https://github.com/wwtm/gitpython_examples/blob/master/实时截图识别OCR/gp_ocr_picture.py
作者:GitPython
来源:GitPython
一行代码扫出“敬业福” 返回搜狐,查看更多
责任编辑:

















 2397
2397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









