






Oracle SQL分组集返回多行(Oracle SQL grouping set returning more than one row)
我正在开发一个Oracle sql脚本,它显示一个部门位置的平均值( location_id = 1700 ),与所有其他部门位置( location_id <> 1700 )相比 - 因为它正在比较两个值,我期待只有两行回。 我能够计算出这样的一个查询:
select d.LOCATION_ID, round(avg(e.salary),2) AS "AVG SALARY", count(d.LOCATION_ID) from departments d
join employees e on e.DEPARTMENT_ID = d.DEPARTMENT_ID
where d.location_id = 1700
group by grouping sets(d.LOCATION_ID);
这会为我返回一行:

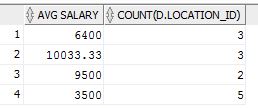
我的第二个查询返回四行而不是一行(就像我想的那样):
select round(avg(e.salary),2) AS "AVG SALARY", count(d.LOCATION_ID) from departments d
join employees e on e.DEPARTMENT_ID = d.DEPARTMENT_ID
where d.location_id <> 1700
group by grouping sets(d.LOCATION_ID);
这将返回4行,但我希望它只返回1:
我的希望是找出两个查询,然后将它们组合在一起 - 显然我需要在将它们放在一起之前克服第二个查询的障碍。
有任何想法吗?
I am working on an Oracle sql script that displays the average for one department location(location_id = 1700) in comparison to all other department locations (location_id <> 1700)--since it's comparing two values, I am looking to only have two rows returned. I was able to work out one query like this:
select d.LOCATION_ID, round(avg(e.salary),2) AS "AVG SALARY", count(d.LOCATION_ID) from departments d
join employees e on e.DEPARTMENT_ID = d.DEPARTMENT_ID
where d.location_id = 1700
group by grouping sets(d.LOCATION_ID);
This returns a single row for me as such:
My second query returns four rows instead of a single one (like I thought it would):
select round(avg(e.salary),2) AS "AVG SALARY", count(d.LOCATION_ID) from departments d
join employees e on e.DEPARTMENT_ID = d.DEPARTMENT_ID
where d.location_id <> 1700
group by grouping sets(d.LOCATION_ID);
This returns 4 rows, but I am looking to have it return only 1:
My hope was to work out both queries, then union them together--obviously I need to get over the hurdle of the second query before putting them together.
Any ideas?
原文:https://stackoverflow.com/questions/34123560
更新时间:2020-09-02 12:09
最满意答案
尝试完全删除组。 听起来你只想要其中location_id = 1700和location_id <> 1700的平均值,然后是UNION这两个结果。
select '1700' as "LOCATION", round(avg(e.salary),2) AS "AVG SALARY", count(d.LOCATION_ID) as "COUNT"
from departments d
join employees e on e.DEPARTMENT_ID = d.DEPARTMENT_ID
where d.location_id = 1700
union
select '<>1700' as "LOCATION", round(avg(e.salary),2) AS "AVG SALARY", count(d.LOCATION_ID) as "COUNT"
from departments d
join employees e on e.DEPARTMENT_ID = d.DEPARTMENT_ID
where d.location_id <> 1700
Try remove the group bys altogether. It sounds like you just want the average where location_id = 1700 and where location_id <> 1700 then UNION the two results.
select '1700' as "LOCATION", round(avg(e.salary),2) AS "AVG SALARY", count(d.LOCATION_ID) as "COUNT"
from departments d
join employees e on e.DEPARTMENT_ID = d.DEPARTMENT_ID
where d.location_id = 1700
union
select '<>1700' as "LOCATION", round(avg(e.salary),2) AS "AVG SALARY", count(d.LOCATION_ID) as "COUNT"
from departments d
join employees e on e.DEPARTMENT_ID = d.DEPARTMENT_ID
where d.location_id <> 1700
2015-12-06
相关问答
在SELECT中使用case语句: SELECT EMP_ID, STATE, CASE WHEN COUNTRY IS NULL THEN STATE ELSE COUNTRY END AS COUNTRY_STATE
FROM [TABLE]
然后,您可以使用LISTAGG()汇总值,具体取决于您的Oracle版本 SELECT LISTAGG(EMP_ID, ',') WITHIN GROUP,
LISTAGG(STATE, ',') WITHIN GROUP,
COUNT
...
这似乎与bug 19461687和之前的问题有关 。 如果从11gR2或12cR1中的查询转储聚合值,您会看到: LISTAGG_OUTPUT
--------------------------------------------------------------------------------------------------
Typ=1 Len=25 CharacterSet=AL32UTF8: 0,41,0,52,0,34,0,30,0,30,0,31,2c,0,41,0,52,0
...
你的代码比你链接的例子复杂得多。 驱动查询不仅非常复杂,而且您的动态语句与生成的表名称的联合。 “这肯定是某种语法错误,或者我正在尝试一些在Oracle中不可能实现的东西。” 动态SQL很难,因为它会将编译错误转化为运行时错误。 “我可以确保你的表格EDW_HPM.DYNAMIC_TEMP确实存在” 在这种情况下,它可能是正在抛出ORA-00942 的生成表名 。 这很容易调试:而不是执行语句显示它。 dbms_output.put_line(finalsql);
现在,您可以通过在SQL客户端
...
它是INSERT ALL的语法 INSERT ALL
INTO VALUES
INTO VALUES
...
;
如果插入后没有任何要选择的内容,则select * from dual 否则你通常选择你想确认插入成功的选项 参考 it the syntax for INSERT ALL INSERT ALL
INTO
...
嗯,伙计们我做到了! 我改变了我的查询,它的工作原理: SELECT TO_CHAR(TRUNC(scheme.table.reg_date,'dd'),'DD.MM.YYYY') AS "DATE", COUNT(*)
FROM scheme.table
WHERE scheme.table.reg_date
BETWEEN TO_DATE('01.08.2013','dd.mm.yyyy') AND TO_DATE('28.08.2013','dd.mm.yyyy')
GROUP BY TRU
...
输入 - CREATE TABLE tabl1
(COL1 varchar2(7))
;
INSERT ALL
INTO tabl1 (COL1)
VALUES ('XEM5454')
INTO tabl1 (COL1)
VALUES ('XEM7646')
SELECT * FROM dual
;
查询 - select listagg(col1,',')WITHIN GROUP (ORDER BY col1) as value
...
你可以通过先导和滞后分析功能来做到这一点 - 在一个子查询中,然后你可以将它分组,这可能是你错过的 - 但你也可以用分析的“技巧”来做到这一点。 如果你查看每个日期和最低日期之间的差异,你得到一个破碎的序列,在你的情况下,0,1,2,3,5,..., attndate - min(attndate) over () 。你可以看到与attndate - min(attndate) over () 。 您还可以从row_number() over (order by attndate)获得另一个连续的
...
通常,HAVING子句需要包含由group生成的列。 实际上,您可以将HAVING子句视为组中的WHERE。 也就是查询: select
from t
group by
having
相当于: select
from (select
from t
group by
) t
where
如
...
这是一个差距和岛屿问题。 使用以下代码: select location,
dense_rank() over (partition by SUBSTR(location,1,1) order by grp)
from
(
select (row_number() over (order by time)) -
(row_number() over (partition by SUBSTR(location,1,1) order by time))
...
尝试完全删除组。 听起来你只想要其中location_id = 1700和location_id <> 1700的平均值,然后是UNION这两个结果。 select '1700' as "LOCATION", round(avg(e.salary),2) AS "AVG SALARY", count(d.LOCATION_ID) as "COUNT"
from departments d
join employees e on e.DEPARTMENT_ID = d.DEPARTMENT_ID
w
...















 1570
1570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









