






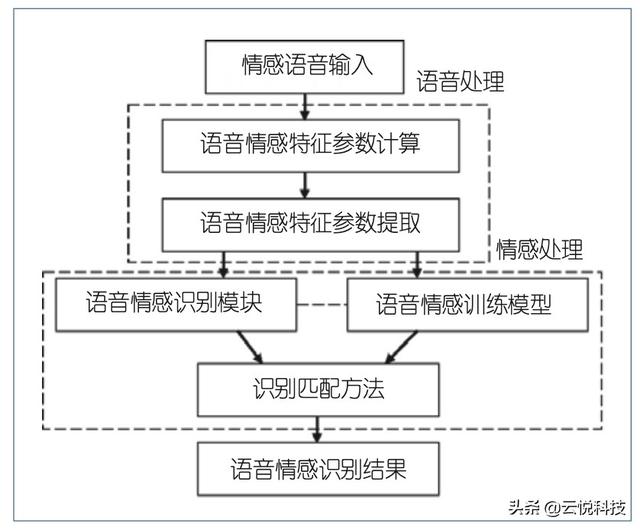
语音是人类最基本、最便捷的交流工具,承载了复杂信息的语音信号不仅可以反映语义内容,还能够传递说话人内在的情感状态。语音情感识别是 建立在对语音信号的产生机制深入研究与分析的基础上,对语音中反映个人情感信息的一些特征参数进行提取,并利用这些参数采用相应的模式识别方法确定语音情感状态的技术。这是人机交互领域的一个重要研究方向。语音情感识别系统主要包括语言处理和情感处理两个重要部分。语音处理是指对输入的语音信号进行处理并提取语音情感特征参数;情感处理是指对隐藏在语句中的情感信息进行识别。
语音情感识别本质上是一个典型的模式分类或回归问题,因此模式识别领域中的诸多算法都曾用于语音情感识别,包括混合高斯模型、支持向量机和隐马尔可夫模型等。虽然传统机器学习算法取得不少进展,但由于数据库的限制,以及这些方法对于大数据的拟合能力较弱,所以目前实现的情感认知水平离人们的期望还相距较远。深度学习在近几年蓬勃发展,各种不同的网络结构和算法被相继提出,并在包括情感识别在内的多个领域得到成熟应用。很大程度上,它们的成功归结于深度神经网络可以学到输入数据的一个层次非线性特征表示。常用的深度神经网络模型有深度信念网络、自动编码器、深度神经网络、卷积神经网络、循环神经网 络以及对抗网络等。基于深度学习的情感识别方法 具有更强的非线性建模能力,在一定程度上提升了情感识别的性能。近年来,基于注意力机制和记忆模型的情感识别方法也得到了广泛关注,这类方法能够通过全局上下文信息自动学习不同帧对于情感 识别的重要性得到相匹配的权重系数,更加符合情 感感知的规律,进一步提高了语音情感识别的性能。虽然语音情感识别在近年来不断取得突破,但是仍然存在着如下问题和挑战:(1)语音情感数据匮乏,如何在低资源情况下提升语音情感识别的性能,是一个比较具有挑战性的工作;(2)在人机交互过程中,情感表达往往具有时序性和个性化的特性,如何利用这些信息提升语音情感识别的性能,也是目前研究的热点问题之一。
针对语音情感数据匮乏的问题,先前很多方法采用无监督学习来提取有效的语音情感特征。无监督学习是指数据在没有情感标签的情况下,通过一些无监督学习算法自动去发现数据中的层次结构和内在分布,从而更好地对原有数据进行编码,以期获得对原有数据更好的模拟表征。许多典型的无监督学习网络被用来提取鲁棒的深层次语音情感特征,包括深度信念网络、自编码器、降噪编码器、变分自编码器和对抗自编码器等。
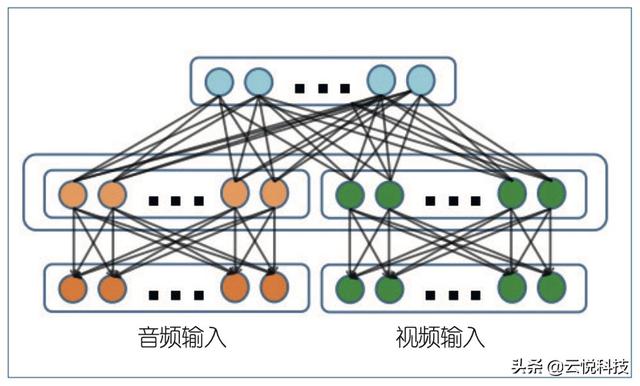
深度信念网络是一种概率生成的网络模型,通过训练其神经元间的权重,可以让整个神经网络按照最大概率来生成训练数据。深度信念网络的每一个隐含层都代表对输入模式的一种中间表示。一个神经元代表输入数据的一个特征,神经元与神经元之间的连接关系表示这些特征之间的联系,这些特征和连接关系的总和构成了对输入数据的一种抽象表示,采用这种方式把一个复杂的输入模式简单化,最终得到一个简单的输出。深度信念网络是由多层的限制玻尔兹曼机堆叠而成。限制玻尔兹曼机有一个可视层和一个隐层,层间存在连接,但层内的单元间没有连接。隐层单元被训练去捕捉在可视层表现出来的高阶数据的相关性。由于深度学习的优势首先在深度信念网络上体现出来,因此深度信念网络也最早被用来提取有效的情感特征。研究者将情感数据输入到深度信念网络的隐含层单元中训练学习,并将音频和视频信号分别输入到各自的隐含层中,组合其输出到下一层,学习到最终的多模态情感特征。
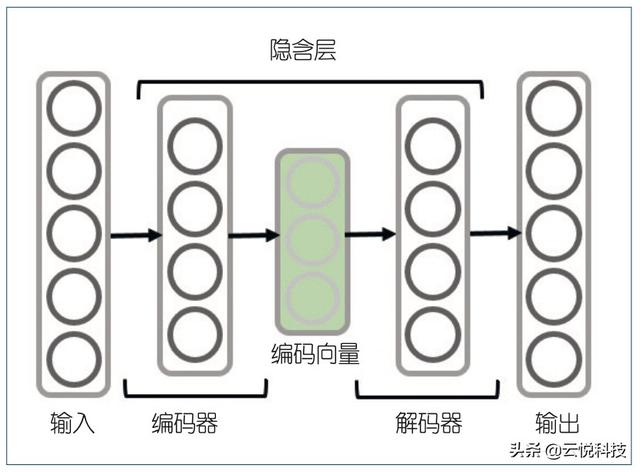
自动编码器是一种非常典型的无监督神经网络模型。它可以学习到输入数据的隐含特征,这个过程被称为编码。同时用学习到的新特征可以重构出原始输入数据,称为解码。从直观上看,自动编码器可以用于特征降维,类似主成分分析,但是比主成分分析的性能更强,这是由于神经网络模型可以提取更有效的特征表示。许多研究者利用自动编码器提取语音情感特征,通过将语音情 感数据输入到自编码器中,利用重建损失函数进行训练,目的是得到更低维度的编码向量,去除冗余信息,更好地对原始数据进行表征。
相比于自编码器,降噪自编码器在输入中加入了一定的噪声,具有更强的噪声鲁棒性。研究者基于降噪编码器构建了模型,强调获得情感相关的特征表示,去除情感无关的信息。模型的输入为干净的语音,在加入噪声后送到两个隐藏层,一个表示中性无情感信息,另一个表示情感相关的信息,将二者融合起来得到重建的输入。这个模型将情感信息从输入信号中剥离出来,以获得更好的特征表示。
自编码器的目的是生成中间隐层特征向量,从而更好地重建输入信号。另外一些更先进的算法是为了生成与输入数据具有相同分布的数据,如变分自编码器和对抗自编码器。研究者对这些网络结构进行了统一的分析,发现变分自编码器和对抗自编码器能取得比降噪编码器更好的性能,主要原因是在特征学习中,它们更强调对语音情感数据的内在结构进行建模。针对情感数据匮乏的问题,有研究者提出了基于无监督表征学习的语音情感识别框架。具体而言,传统方法采用无监督学习将其他领域的知识用于语音情感识别,从而缓解低资源的问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









