









在Mac电脑下利用parallel desktop 创建4台虚拟机master、data1、data2、data3进行hadoop完全分布式的安装以及环境配置
我的主机系统是macOS,虚拟机的系统是CentOS.
(可以先配置伪分布式Hadoop试一试,然后再在这个基础上部署完全分布式Hadoop)
一、把single Node cluster 复制到data1
1,克隆主机data1
右击主机–>点击克隆–>设置虚拟机名称为data1


二、设置Mutli Node Cluster 服务器,配置设置文件共同的部分
固定ip、hostname、core-site.xml、yarn-site.xml、mapred-site.xml、hdfs-site.xml
1,编辑网络配置文件设置静态ip
1)sudo vi /etc/udev/rules.d/70-persistent-net.rules
将eth2改为eth0,并复制地址00:1c:42:f6:c7:5c,为什么只留下这个呢,可以在网络->高级设置->查看mac地址,验证设备上找到的MAC地址是否与设备中的MAC地址相同,留下那个相同的mac地址.

2)sudo vi /etc/sysconfig/network-scripts/ifcfg-eth0,其中内容含义如下
DEVICE=eth0 //使用的网卡标识
TYPE=Ethernet //表示为以太网
ONBOOT=yes //表示是否开机启动
BOOTPROTO=static //这里表示开机协议,有三种(dhcp,static,none)dhcp表示自动获取ip,static自然就是静态分配ip,none表示不使用任何协议
IPADDR=10.211.55.11 //这里就是你所要设定的IP
GATEWAY=10.211.55.1 //网关
比如我的虚拟机
修改前:
修改后:

这个地址前三段(10.211.55)与虚拟机子网IP前三段一致,这样才能保证虚拟机与宿主机通信。
比如我mac电脑虚拟网卡ip可以利用ifconfig查到:
配置完之后,需要重启网络配置。
service network restart
reboot重启设备,查看ip是否修改成功ifconfig eth0
再用ping命令,验证能否ping 通宿主机,ping通外网(比如ping www.baidu.com)。
2,修改主机名
首先用hostname查看主机名
修改主机名(如果觉得主机名不合适,为了更好的分辨,可以进行修改)
sudo vi /etc/sysconfig/network
我的主机名之前是hh,现在改为data1
修改前:
修改后:

3,设置hosts文件
sudo vi /etc/hosts
修改前:
添加各节点的主机名以及对应ip地址
修改后:
 reboot重启设备,查看主机名是否修改成功.
reboot重启设备,查看主机名是否修改成功.
(注意:所有主机防火墙要关闭)
4,编辑core-site.xml文件
切换到目录 cd /opt/module/hadoop-3.2.0/etc/hadoop下
(其中/opt/module/hadoop-3.2.0是我hadoop的安装路径)
在core-site.xml中,必须设置HDFS的默认名称,使用命令或者程序来存取HDFS时,可以使用此名称,有多台计算机时必须指定主机名.
vi core-site.xml
改为master.

5,编辑yarn-site.xml文件
1). 设置ResourceManager主机与NodeManager的连接地址
Nodemanager通过这个地址向ResourceManager汇报运行情况
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8025</value>
</property>
2).设置Resourcemanager与ApplicationMaster的连接地址
Application通过这个地址向ResourceeManager申请资源、释放资源等
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
3).设置ResourceManager与客户端的连接地址
客户端通过该地址ResourceManager注册应用程序,删除应用程序等.
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8050</value>
</property>
添加修改如下:

6,编辑修改mapred-site.xml
vi mapred-site.xml
修改设置map reduce job tracker 的连接地址为master:54311
<property>
<name>mapred.job.tracker</name>
<value>master:54311</value>
</property>

7,编辑修改hdfs-site.xml
hdfs-site.xml用于设置HDFS分布式文件系统的相关配置
在data1中只是扮演datanode角色,只需要保留datanode设置即可.
vi hdfs-site.xml

ok,data1配置完成.接下来data2,data3,master.
三、克隆data1到data2、data3、master
data1已经设置Hadoop Mutli Node Cluster共同的部分,可以复制data1到data2、data3、master.

改名后进行存储,即进行克隆.同理,将data1克隆data3、master,克隆完成就如下图所示

四,设置data2、data3服务器
对data2、data3进行静态ip设置以及主机名编辑
以data2为例.
1 ,编辑网络配置文件设置静态ip、修改主机名
1)sudo vi /etc/udev/rules.d/70-persistent-net.rules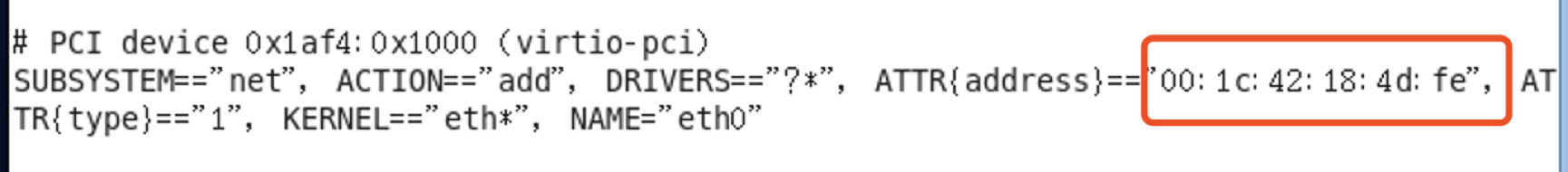 2)
2) sudo vi /etc/sysconfig/network-scripts/ifcfg-eth0
3) sudo vi /etc/sysconfig/network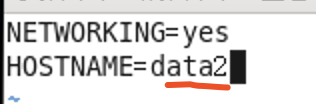
把Mac地址,ip地址,hostname改一下,步骤基本与data1设置相同,
五、设置master服务器
1,前面步骤同四.
2,编辑hdfs-site.xml
切换到hadoop路径的etc/hadoop下cd /opt/module/hadoop-3.2.0/etc/hadoop
编辑修改vi hdfs-site.xml

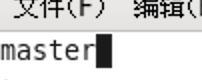
3,编辑master文件
编辑 vi masters
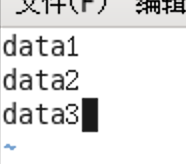
编辑vi slaves
六,master连接data1、data2、data3创建HDFS目录
1,启动所有虚拟机data1.data2.data3.master
2,切换到master,开启终端
ssh data1
可以看的主机名变为data1,说明已经连接上data1.
3,在data1上创建HDFS目录
1)删除hdfs所有目录
rm -rf /opt/module/hadoop-3.2.0/hadoop_data/hdfs
2)创建datanode存储目录
mkdir -p /opt/module/hadoop-3.2.0/hadoop_data/hdfs/datanode
3)中断data1的连接,回到master
exit
4)重复1)~3)步骤,设置data2、data3
(不知道有没有说错,欢迎指点^ ^)
基本步骤大概就是这样,最后再测试一下
参考资料:
Linux CentOS虚拟机网卡配置
Mac上配置Linux网络适配器(NAT模式),无法ping通
Creating a Virtual Network















 677
677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









