







 开始做简单的ORC,从昨天到今天总算有个小小的成绩了。图像的文字识别我拿验证码开刀,因为验证码稍微简单点,说说验证思路:一、获取验证图片二、程序加载要验证的字体库三、程序加载需匹配的文字库(字符数组即可)四、将验证码图片进行中值滤波处理,然后再将其锐化(也可进行取色彩最多的几个点进行采样再锐化)五、将验证码的字符进行拆字(扫描行、列的间隙,然后就可以将字找出来),然后将拆分之后的图像保存到内存中,...
开始做简单的ORC,从昨天到今天总算有个小小的成绩了。图像的文字识别我拿验证码开刀,因为验证码稍微简单点,说说验证思路:一、获取验证图片二、程序加载要验证的字体库三、程序加载需匹配的文字库(字符数组即可)四、将验证码图片进行中值滤波处理,然后再将其锐化(也可进行取色彩最多的几个点进行采样再锐化)五、将验证码的字符进行拆字(扫描行、列的间隙,然后就可以将字找出来),然后将拆分之后的图像保存到内存中,...
开始做简单的ORC,从昨天到今天总算有个小小的成绩了。
图像的文字识别我拿验证码开刀,因为验证码稍微简单点,说说验证思路:
一、获取验证图片
二、程序加载要验证的字体库
三、程序加载需匹配的文字库(字符数组即可)
四、将验证码图片进行中值滤波处理,然后再将其锐化(也可进行取色彩最多的几个点进行采样再锐化)
五、将验证码的字符进行拆字(扫描行、列的间隙,然后就可以将字找出来),然后将拆分之后的图像保存到内存中,为以后提供匹配
六、此步骤为循环
6.0依次取字体库中的字符
6.1将取出的字符的字体设置成需验证的字体
6.2图像化此字符
6.3将内存的字与验证的字放大至同样的大小(高或者宽取最小公倍数)
6.4然后开始记录源与目标的验证点(用数组保存值,如果在像素点上有待验证的点,值为1,否则为0)
6.5然后将验证点进行匹配像素块,记录块的匹配度(我这里拿4方格,4个像素做匹配块,一个像素0.25个匹配度)
6.6累加匹配度,匹配完成之后再计算均值
6.7当均值大于某个值时则匹配成功
七、退出循环
八、××程序上的业务逻辑××
当然,思路是这样的,中间有几个地方在今天的代码中没有体现出来:
1.中值滤波(现在暂时还没有搞懂图像的计算公式)
2.字体库(这个确实不晓得我的电脑今天是不是大姨夫来了,字体库居然加载不上)
3.拆字(从图片中我都能够把字取出来,扫描行、列的文字也暂时不用实现)
4.字体缩放(节约时间没有做)
测试的来源是两个bmp的图片,一个作为匹配,一个作为待验证的,字体、大小不要太过于差异了,位置可以随便放,只要目测能够看出来是那个字。
当然,验证的时候不可能把验证库保存为图片文件,这是不科学的……
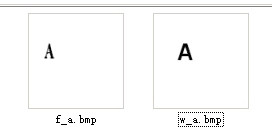
这两个字是不同的字体,匹配度只有那么多点了……

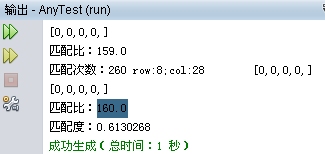
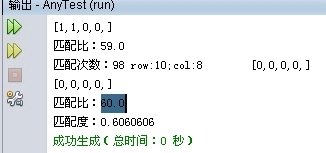
这个是当图形处理的。
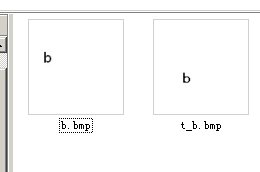
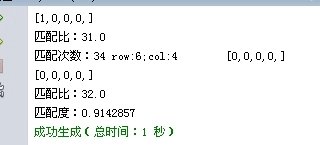
虽然字体不一样,但匹配度是很高的(这个好像……没有做锐化处理)
贴代码:
import java.awt.Color;
import java.awt.Point;
import java.awt.RenderingHints;
import java.io.File;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 读取验证码
* @author Administrator
*/
public class ReadSerCode {
public static final int east = 1;//东
public static final int south = 2;//南
public static final int west = 3;//西
public static final int north = 4;//北
public static final int northeast = 5;//东北
public static final int southwest = 6;//西南
public sta
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 436
436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









