







 本文介绍了HiveServer2 Proxy,它是实现MaxCompute与Hive生态工具互通的代理,允许工具通过Hive接口与MaxCompute交互。通过两个示例,展示了如何使用Tableau通过Hive ODBC和Beeline通过Hive JDBC连接MaxCompute,实现数据查询和分析。
本文介绍了HiveServer2 Proxy,它是实现MaxCompute与Hive生态工具互通的代理,允许工具通过Hive接口与MaxCompute交互。通过两个示例,展示了如何使用Tableau通过Hive ODBC和Beeline通过Hive JDBC连接MaxCompute,实现数据查询和分析。
注:MaxCompute原名ODPS,是阿里云自研的大数据计算平台,文中出现的MaxCompute与ODPS都指代同一平台,不做区分
什么是Hive
Hive是一款经典的hadoop技术栈的数仓软件,可以让用户采用SQL来完成大数据量的计算分析。如果你对Hive还不熟悉,请移步Apache Hive官网获取进一步了解。MaxCompute在很多功能上与Hive相近,所以大部分MaxCompute的用户曾经也是Hive的用户。
什么是HiveServer2
既然提到HiveServer2,那得先介绍一下HiveServer1,我们通常也直接称之为HiveServer。HiveServer是基于Apache Thrift构建的一套服务,它支持远程客户端通过Thrift API向Hive提交请求。由于HiveServer1无法处理超过一个以上客户端的并发请求,所以社区对HiveServer1进行了重写,从而解决了HiveServer1中存在的诸多问题,该重写后的新版本我们称之HiveServer2。
由于HiveServer2本质上是一个Thrift Server,所以天然拥有跨语言的支持,而大量的Hive生态的工具也是基于HiveServer2的Thrift API实现的,比如最常见的Hive ODBC和Hive JDBC,以及基于这两套实现之上的其他工具。
什么是HiveServer2 Proxy
顾名思义,HiveServer2 Proxy是一个代理,它是在原有HiveServer2的基础之上定制开发后得到的。它完成的工作就是接受客户端提交的的Thrift请求,将其反序列化并转换成MaxCompute能够识别的请求,然后提交给MaxCompute处理,并在MaxCompute处理完后将响应再次转换成客户端能够识别的符合Hive接口规范的Thrift响应,从而实现Hive生态工具到MaxCompute的互通。简而言之,它的功能就是在用户无需修改Hive生态工具的情况下,为这些工具与MaxCompute的交互提供了一条通路,从而使我们能在复用已有的Hive工具的同时,也能使用上MaxCompute强大的计算引擎。 HiveServer2 Proxy的原理图如下所示:
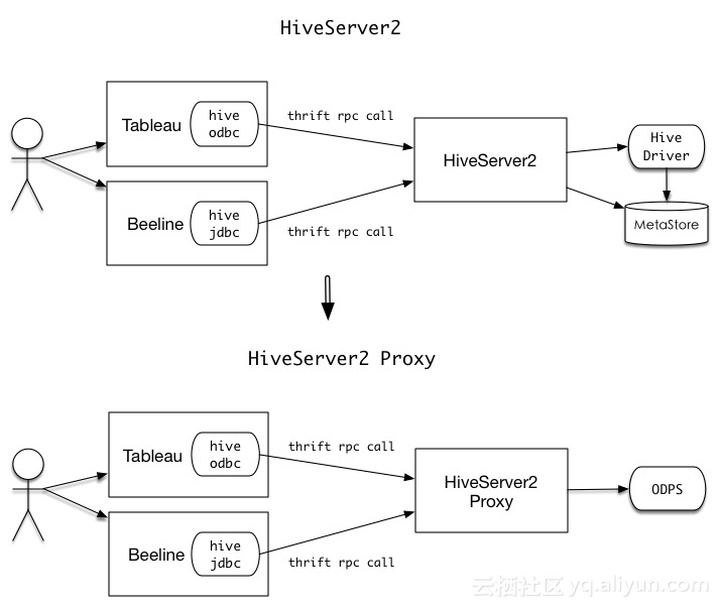
下面我们将通过两个实例来演示HiveServer2 Proxy的功效。
部署HiveServer2 Proxy
首先,部署HiveServer2 Proxy的前置条件是安装好Java1.7和hadoop2.x(如果你不想安装hadoop也可以跳过这一步),此处不做赘述,请参考这两者的官方文档。笔者在以下内容中将以MacBook PRO的OS X来作为演示系统。其他操作系统的用户在配置上大同小异。
确保前置条件满足后,请下载HiveServer2 Proxy的测试版。
将下载到的压缩包解压,得到名为apache-hive-2.1.0-odps-proxy的文件夹。设置好HIVE_HOME环境变量,如笔者的配置:
emerson@192.168.31.104 /Users/emerson/apache-hive-2.1.0-odps-proxy % export HIVE_HOME=$(pwd) emerson@192.168.31.104 /Users/emerson/apache-hive-2.1.0-odps-proxy % echo $HIVE_HOME /Users/emerson/apache-hive-2.1.0-odps-proxy
如果你安装了hadoop请配置环境变量HADOOP_HOME,如果跳过没有安装的,可以使用proxy自带的hadoop依赖,即根目录下的hadoop目录。可以在根目录下执行如下命令:
eme 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









