






I/O虚拟化[是虚拟化技术的一个核心部分, 使得虚拟机[可以共享服务器I/O资源.目前, I/O虚拟化技术的发展仍然相对滞后, 出于安全性的考虑, 虚拟机监控器[会干预虚拟机的I/O操作, 同时, 虚拟机之间的资源竞争均对I/O性能有负面影响, 降低了虚拟化平台的整体性能.
早期的虚拟化通过软件方式实现, 分别是软件模拟方式和半虚拟化方式.前者用软件方式模拟设备的接口, 这种方式下, 虚拟机的所有I/O操作都被虚拟机监控器截获, 性能损失比较严重.后者通过前后端驱动交互的方式与真实的硬件设备进行通信.由于后端和前端是一对多的关系, 当虚拟机数目较多时, 后端会成为系统的瓶颈.近年来随着越来越多对I/O性能有严苛要求的应用被迁移到虚拟化环境中, 软件方式实现的虚拟化已无法满足应用需求.为了满足虚拟机的I/O性能需求, 硬件辅助I/O虚拟化[被提出来, 设备直接分配技术将一个物理I/O设备直接分配给一台虚拟机, 使得虚拟机可以直接访问设备, I/O性能得到了极大的提升.但一个物理设备只能分配给一台虚拟机, 无法支持多台虚拟机共享.SR-IOV (single root I/O virtualization)[技术则通过虚拟功能(virtual function, 简称VF)支持资源共享, 它可以创建多个VF, 直接分配给每台虚拟机, 兼顾了性能与扩展性.然而, SR-IOV的I/O处理仍然需要虚拟机监控器的干预, 物理设备产生的中断需要由虚拟机监控器注入到虚拟机之中, 产生上下文切换, 导致其性能与原生系统相比仍有一定的差距.
目前已有很多针对I/O虚拟化性能优化的研究, 其中优化虚拟CPU (virtual CPU, 简称VCPU)调度算法是主要途径之一, 但现有的方法仍存在一些问题, 如缺乏灵活性[、应用场景单一[、破坏系统公平性[等.
虚拟机操作系统管理和访问的系统资源都是由虚拟机监控器提供的虚拟硬件资源, 包括虚拟CPU、虚拟内存和虚拟I/O.当分配给虚拟机的虚拟CPU被调度到物理CPU上运行时, 虚拟机操作系统才能运行虚拟机中的各个进程, 因此, 虚拟机性能与虚拟CPU调度密切相关.根据目前主流的虚拟机监控器可以将虚拟CPU调度算法分为两类, 一类直接使用内核中的调度器并将虚拟CPU作为线程调度, 如KVM[使用的O(n), O(1), CFS算法; 另一类虚拟机监控器专门设计了一套调度算法, 如Xen[使用的BVT, SEDF, Credit算法[, 其中CFS算法和Credit算法是目前的主流.
CFS调度算法的核心思想是围绕着虚拟时间展开调度, 每个进程有自己的虚拟时间, 其增长速度与进程权重成反比, 进程的权重对应进程的优先级.CFS调度器为每个CPU分配一个按虚拟时间从小到大排序的红黑树结构, 所有可运行进程都被插入红黑树之中, 红黑树最左边的节点表示下一个被调度的进程.CFS调度器在原生Linux环境中表现良好, 但是在虚拟化环境中存在不足.(1)在与计算型负载虚拟机共存的环境下, I/O型负载虚拟机的I/O性能受损.因为红黑树根据虚拟时间排序, 而运行I/O负载的进程被唤醒时所获得的虚拟时间往往不足以抢占当前运行的进程[.(2)多处理器虚拟机可能引发锁占用的问题[.由于虚拟CPU是否正在持有锁对调度器是不可见的, 如果一个正在持有自旋锁的虚拟CPU进入休眠, 正在等待这个自旋锁的其他虚拟CPU则会因此需要等待更长的时间.
Credit调度算法按照虚拟机权重共享CPU时间.Credit调度算法的参数主要包括表示权重的weight和表示CPU时间上限的cap.Credit调度器根据每个虚拟机的weight值计算其应获得的信用值.cap值限定其所能获得的信用值值上限.其CPU时间片分配由指定定时器完成, 该定时器触发周期为30ms.首先根据物理CPU个数计算系统总信用值, 然后再根据每个虚拟机的权重和虚拟CPU个数计算虚拟机应获得的信用值, 继而取信用值和cap中较小的一个作为虚拟机的信用值, 再将虚拟机的信用值平均分配到每个虚拟CPU.在Credit算法中, 映射到每个物理CPU上的虚拟CPU会加入该物理CPU的运行队列中, 并按照其优先级由高到低顺序排列.虚拟CPU的优先级共有4种, 分别是IDLE, OVER, UNDER以及BOOST.其中, IDLE状态表示该虚拟CPU仅用于空闲时占位, 具有最低的优先级; OVER状态表示该虚拟CPU已消耗完Credit值并且无法被调度; UNDER状态下的虚拟CPU按照队列中的先后顺序周期性地被调度; 当虚拟CPU因事件到来被唤醒后会进入BOOST状态, BOOST状态的虚拟CPU具有最高优先级, 会被优先调度.当一个虚拟CPU消耗完其时间片时, 会被重新插回运行队列中同等优先级虚拟CPU尾部.当一个运行队列空闲时, 会从其余运行队列中寻找非IDLE的虚拟CPU并迁移调度.
与直接使用内核的调度算法相比, Credit调度算法具有如下优势:(1)它是一种能够通过设置虚拟机权重来按比例分享CPU时间的调度算法, 特别适用于按需分配的云计算环境; (2)其Boost机制支持及时抢占.这也是选择其作为研究对象的原因.
1 虚拟CPU调度器面临的挑战
虚拟机在竞争CPU资源时, 运行I/O型负载的虚拟机性能明显下降, 其原因如下:首先, 每次处理I/O请求仅消耗极短的CPU时间, 使得虚拟机实际获得的CPU时间远远少于分配的时间, 同时其调度延时取决于虚拟CPU数目以及时间片长短; 其次, 尽管负载均衡有利于充分利用CPU资源, 但是负载均衡过程中频繁的虚拟CPU迁移所引入的缓存污染、上下文切换等额外开销会在很大程度上抵消负载均衡所带来的好处.
1.1 调度延时高且不稳定
虚拟CPU调度延时对虚拟机的I/O性能具有重要影响.目前的虚拟CPU调度器注重公平共享CPU时间, 对所有的虚拟CPU采用简单的循环轮转算法, 每次从可运行的运行队列中选取队列头, 然后运行一定的时间, 再插入到运行队列.因此, 虚拟CPU的调度延时与运行队列中的可运行虚拟CPU数目以及时间片长短密切相关.
图 1
Fig. 1
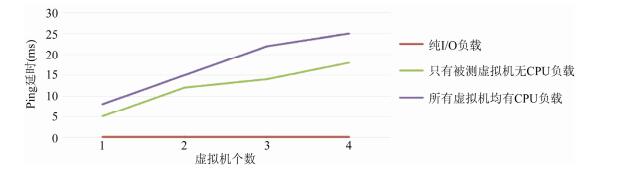
Fig. 1 Latency of VM 1 changes with the number of VMs
图 1 虚拟机1的延时随虚拟机个数变化
1.2 负载均衡带来的性能损失
为了充分利用CPU资源, 虚拟CPU调度器会在物理CPU空闲时从其他忙碌的物理CPU上迁移虚拟CPU来实现负载均衡.现在的计算机通常是多处理器架构.物理机通常具有多个物理封装(socket), 一个物理封装具有多个物理核(core), 在支持超线程的服务器中, 一个物理核可以模拟两个逻辑处理器(logic processor).在多处理器系统中, 虚拟CPU迁移的开销取决于源和目的物理CPU的相对位置.对于在同一物理核上的逻辑处理器之间的虚拟CPU迁移, 由于源和目的物理CPU共享L1缓存, 所以迁移开销较小; 而对于不同物理封装之间的虚拟CPU迁移, 高速缓存污染的开销则很大.因此, 为了降低虚拟CPU迁移所带来的额外开销, 一方面应尽量消除不必要的迁移, 另外一方面必须要考虑多处理器架构对迁移开销的影响.自4.3版本开始, Credit调度器加入了针对多处理器架构优化的负载均衡机制, 大幅度消除了跨物理封装的虚拟CPU迁移.但其负载均衡策略仍有不足:(1)粒度还不够细, 物理封装内部仍然有物理核结构, 如果能够尽量在同一个物理核中进行虚拟CPU迁移, 其开销会更小; (2)没有考虑目标虚拟CPU上运行的负载对迁移的影响.这也是很多研究工作都忽视的一个问题.
2 虚拟CPU调度算法优化相关工作
虚拟CPU调度算法一直是广受关注的研究热点, 同时也是影响I/O虚拟化性能的一个重要因素.早期的虚拟CPU调度器没有考虑I/O负载的需求.2008年, Ongaro等人在虚拟CPU调度器中引入BOOST优先级和抢占机制来提高延时敏感型虚拟机的性能[, 当有剩余信用值的虚拟CPU从挂起状态被I/O事件唤醒时, 则标记为BOOST优先级, 并抢占物理CPU, 更快地进行I/O处理.但当虚拟机中运行的是计算密集型负载或者混合负载时, 虚拟CPU往往会耗尽时间片, 不会达到触发BOOST优先级的条件.针对BOOST优先级的局限性, Ding等人在2013年提出了ECredit模型[:一种通过统计I/O请求数目来设置I/O优先级的改进算法.I/O优先级根据虚拟机的I/O请求的数目来进行设定, 数目越大, I/O优先级越高, 会排在运行队列前面.这种方案解决了BOOST的局限性问题, 但是需要虚拟机监控器与虚拟机的通信合作, 仅适用于半虚拟化环境.2013年, Zeng等人[考虑到I/O执行时间通常很短, 将BOOST优先级的执行时间改为2ms, 这样也避免了非I/O进程在BOOST优先级的虚拟CPU上执行时间过长.该方案针对BOOST优先级进行了优化, 但是并未解决计算密集型负载与I/O密集型负载共存时的I/O性能问题.
另一种解决I/O响应延时的方案是修改时间片.最直观的方式就是缩短所有虚拟CPU的运行时间片长度[, 每一个虚拟CPU的调度延时都可以降低, I/O性能提升明显, 但该方案同时也增加了上下文切换的发生频率.2012年, Xu等人提出了vSlicer方案[, 设计两类时间片来满足负载的特性:对运行I/O密集型负载的虚拟CPU设定很短的时间片; 运行计算密集型负载的虚拟CPU仍然使用正常的时间片.如此就降低了整个系统的I/O响应时间, 并且没有影响计算密集型负载的性能.但是, 由于该方案没有考虑负载的隔离, 当I/O密集型负载和计算密集型负载共享相同物理CPU时, I/O密集型负载仍需较长的排队时间, 因此, 该方案不适合混合型负载的虚拟机.作为对vSlicer模型的改进, Xu等人在2013年提出了多处理器环境下的vTurbo方案[.该方案基于负载隔离与专用I/O核心的思想, 预留1个或多个物理核作为运行时间片很短的专用I/O核心, 并为每个虚拟机额外分配一个I/O型虚拟CPU来处理I/O中断, 将I/O型虚拟CPU绑定到I/O核心上调度, 其余的虚拟CPU不在I/O核心上调度并拥有正常的运行时间片.该方案解决了vSlicer不适合混合型负载的问题.但是, 其I/O核心资源是静态预留的, 不会随着I/O负载的变化而灵活分配, 并且该方案需要修改虚拟机操作系统, 仅适用于半虚拟化环境.
优化Credit调度器中的负载均衡策略也能实现I/O性能的提升.Rao等人在2013年提出了(bias random VCPU migration, 简称BRM)算法[.该方案对影响NUMA性能的因素, 包括数据局部性、三级缓存竞争、数据共享这3个方面进行了综合测试和分析, 据此设定每个虚拟CPU的迁移开销.然后根据迁移开销来决定虚拟CPU如何迁移.达到整个系统的迁移开销最小, 以此提升I/O性能.但该方案需要修改虚拟机操作系统, 仅适用于半虚拟化环境.2013年, Cheng等人[也指出, 虚拟机访问远程NUMA节点比本地NUMA节点延时更高, 影响I/O性能, 但虚拟CPU调度器的负载均衡策略并未考虑NUMA架构的影响, 针对该问题, Cheng等人提出了“最佳NUMA节点”方案, 确保虚拟CPU被迁移到最合适的NUMA节点中调度.该方案有较高的缓存命中率, 但是粒度还不够细.
针对目前的优化方案存在上述问题, 本文实现了一种兼容软硬件虚拟化方式、低延时、灵活性好并且能保证系统公平性的虚拟CPU调度算法.
3 FLMS (flexible I/O latency and multi-processor sensitive scheduler)设计与实现
本文提出了一种灵活、高效的虚拟CPU调度算法(FLMS).FLMS通过采用虚拟机分类、虚拟CPU绑定、多类时间片等技术降低了虚拟机的响应延时, 同时, 基于多处理器架构重新设计了负载均衡策略, 考虑了目标虚拟CPU上运行的负载对迁移的影响, 优化了虚拟CPU迁移.FLMS不需要修改操作系统, 通用于软硬件虚拟化方式, 在软件虚拟化方式下与近年来提出的vTurbo方案相比, 效果提升明显, 在使用硬件辅助虚拟化的系统中, 通过FLMS能够获得接近本地环境的I/O性能, 并且保证虚拟机公平共享系统资源.
3.1 动态负载隔离
针对I/O延时敏感型的负载和计算密集型负载相互影响的问题, 本文提出一种动态负载隔离方案.FLMS调度架构如
图 2
Fig. 2
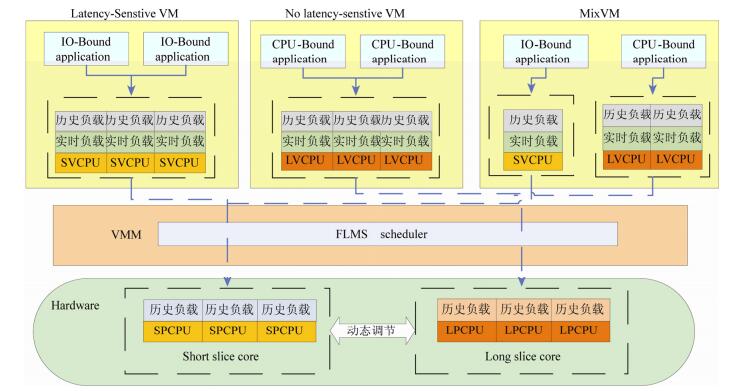
Fig. 2 FLMS scheduling framework
图 2 FLMS调度框架
FLMS根据整个系统中的I/O密集型负载以及计算型负载的比重来动态分配SPs以及LPs的比例.其中, I/O密集型负载统计量为一个周期内系统所有运行I/O型负载的虚拟CPU的运行时间之和, 即LSVM和MixVM中运行I/O密集型负载的虚拟CPU的运行时间总和, 而计算密集型负载统计量为NLSVM和MixVM中运行计算密集型负载的虚拟CPU的运行时间总和.由于要在当前周期内确定下一周期的LPs和SPs的数目, FLMS需要根据历史负载信息来预测下一周期的负载状况.
假设物理CPU的个数为PNum, SPs和LPs的数目分别为SPNum和LPNum, 系统中的I//O密集型负载量和计算密集型负载量分别为EstimatedIO和EstimatedCPU, 当前周期内I/O密集型负载统计量和计算密集型负载统计量定义为SampleIO和SampleCPU.可以通过以下公式计算SPs和LPs的数目, 其中, a代表当前周期内的负载统计值对下一周期负载的影响因子, 0≤a≤1.
$
EstimatedIO = (1-\alpha ) \cdot EstimatedIO + \alpha \cdot SampleIO
$
(1)
$
EstimatedCPU = (1-\alpha ) \cdot EstimatedCPU + \alpha \cdot SampleCPU
$
(2)
$
SPNum = EstimatedIO \cdot PNum/(EstimatedIO + EstimatedCPU)
$
(3)
$
LPNum = PNum-SPNum
$
(4)
为了标识SPs以及LPs的物理CPU, FLMS使用了两个互补的CPU位图:ForIO和ForCPU.虽然也可以仅用1个位图, 但由于调度器会频繁查询位图, 将产生大量取反操作.而且只有在执行CPU分组动态调整时会同时更新两个物理CPU位图.系统初始化时, ForIO设置为全0, ForCPU设置为全1, 表示系统初始默认运行计算密集型负载.在系统运行过程中, 通过用户设定虚拟机类型, 系统中I/O型负载与计算型负载的比重来更新两个物理CPU位图.
采用这种调度结构的优点有如下两点.
(1)性能改善.FLMS实现了负载隔离, I/O密集型负载获得了更高的调度频率与更少的排队等待时间, 对于计算密集型负载, 也保证了较少的上下文切换与较高的缓存命中率.
(2)灵活性好.相对于专门分配一定数目的物理CPU作为I/O核心的方法而言, FLMS根据系统负载比重对物理CPU分组, 并定时根据负载变化调节两组物理CPU的数目, 保证了系统的灵活性以及更高的资源利用率.
3.2 增强I/O优先级
在Credit算法中引入Boost机制的目的在于期望I/O事件到来时, 目标VCPU可以及时抢占物理CPU资源.但是在FLMS的调度架构中, 因为实现了负载的隔离, 原有的抢占机制已不再适用, 因此考虑采用一个新的变量来表示I/O任务繁重程度.对于运行I/O型负载的虚拟CPU而言, I/O任务越重, 被调度的次数就越多, 其信用值消耗速度也越快; 而I/O任务很轻的虚拟CPU会长期挂起, 信用值的消耗很慢, 因此, 消耗信用值的多少可以作为衡量虚拟CPU的I/O任务繁重程度的指标.FLMS在虚拟CPU调度结构增设一个字段IO_Boost来标识虚拟CPU的I/O繁重程度.IO_Boost对于NLSVM的虚拟机是毫无意义的, 可以忽略其虚拟CPU的IO_Boost值.IO_Boost值值越小, 表示该虚拟CPU的I/O任务越繁重, 系统启动时初始值为0, 当动态负载隔离计时器触发, 发生了SPs以及LPs类型的物理CPU数目调节时, 也重新修改IO_BOOST的值, 取值的依据也是各个虚拟CPU的历史负载.每当虚拟CPU被调度1次时, 也适当增加其IO_Boost值, 计算公式如下:
$
IO\_Boost = IO\_Boost + 1/(totalCredit-remainCredit)
$
(5)
$
historyLoad = historyLoad + (totalCredit-remainCredit)
$
(6)
$
IO\_Boost = 1/historyLoad
$
(7)
其中, totalCredit表示在当前周期内虚拟CPU被分配的信用值以及上一周期剩余信用值之和, remainCredit表示当前周期结束后剩余的信用值, 当前周期到期后, 通过将totalCredit减去虚拟CPU剩余信用值即可得到当前周期虚拟CPU消耗掉的信用值; historyLoad字段用于表示虚拟CPU的历史负载, 其值根据当前周期内消耗的信用值进行计算.
当虚拟CPU运行完成, 重新插入运行队列时, 也需要按照IO_Boost值从小到大的顺序, 引入IO_Boost机制后, 调度系统中SPs的物理CPU运行队列如
图 3
Fig. 3
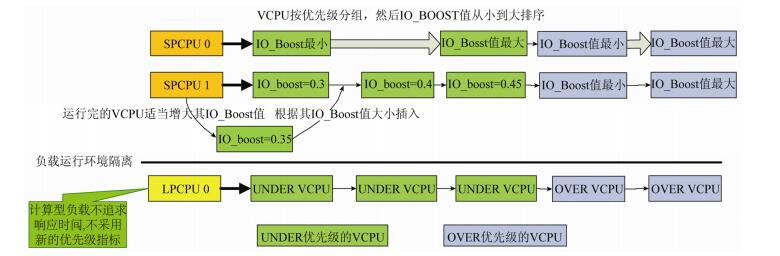
Fig. 3 IO_Boost mechanism
图 3 IO_Boost机制
3.3 高效负载均衡
目前负载均衡的优化方案大多关注目标物理CPU的选择, 而忽略了目标虚拟CPU的选择对整个系统的影响.在FLMS中除了考虑到多处理器架构之外, 还设计了目标虚拟CPU选择策略.
对于目标物理CPU的选择依然考虑多处理器架构的特点, 同时还需要保证当SPs中的物理CPU触发负载均衡时不会影响到LPs中的物理CPU, 以避免计算密集型负载与I/O密集型负载之间相互干扰.当物理CPU空闲时, FLMS根据下述迁移策略选择目标物理CPU.
(1)判断触发负载均衡的源物理CPU属于SPs还是LPs, 如果属于SPs, 则将SPs的其他所有物理CPU作为目标集合; 否则将LPs中的所有物理CPU作为目标集合.
(2)调度器遍历物理CPU目标集合中的物理CPU, 寻找是否存在与源物理CPU在同一个物理核中的物理CPU, 若存在, 则将该物理CPU作为目标物理CPU并转(7);否则转(3).
(3)调度器遍历物理CPU目标集合中的物理CPU, 寻找是否存在与源物理CPU在同一个物理封装上的物理CPU, 若存在, 则找到该物理封装中负载最重的物理CPU作为待选物理CPU, 转(4);否则转(5).
(4)若待选物理CPU负载减去源物理CPU负载超过阈值A, 则说明两者负载相差较大, 此时将待选物理CPU作为目标物理CPU, 转步骤(7);否则, 该物理封装上的所有物理CPU均不能作为目标物理CPU, 转(5).
(5)调度器遍历物理CPU目标集合中剩余的物理CPU, 寻找负载最重的物理CPU, 作为待选物理CPU.
(6)若待选物理CPU的负载减去源物理CPU负载超过阈值B, 则说明两者负载相差较大, 此时将待选物理CPU设置为目标物理CPU, 转(7);否则转(8).
(7)在目标物理CPU上寻找合适的虚拟CPU并迁移, 迁移结束.
(8)若未找到合适的目标物理CPU, 则迁移结束.
其中, A和B分别代表了在不同物理核与在不同物理封装之间进行虚拟CPU迁移的阈值.为了实现对物理CPU负载的统计, FLMS需要在物理CPU调度数据结构中添加相关字段historyBusy, currentBusy以及一个定时器.currentBusy用于表示一个计时器周期内产生的负载, 由该物理CPU正在调度的虚拟CPU消耗的信用值累加而得, historyBusy用于表示物理CPU的历史负载, 其值根据当前周期内的历史负载和相对于当前周期的负载currentBusy进行计算.定时器用于每隔一定周期进行一次物理CPU历史负载记录historyBusy的更新.计算方法参考如下公式, 其中, b表示历史负载权重因子, 0≤b≤1.
$
historyBusy = historyBusy \cdot b + currentBusy \cdot (1-\beta )
$
(8)
选定了目标物理CPU之后还需要进一步选择目标虚拟CPU.Credit算法每次从运行队列头开始依次遍历, 只要队列元素的优先级大于源物理CPU队首虚拟CPU的优先级就将其作为目标虚拟CPU.这种策略未顾及到负载的特性, 虽然简单但并不高效.FLMS针对上述问题提出了目标虚拟CPU的选择策略.
FLMS负载均衡机制如
图 4
Fig. 4
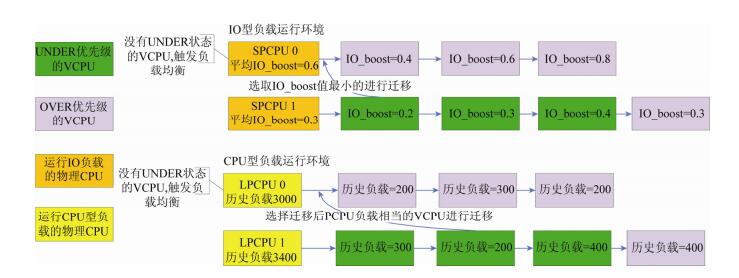
Fig. 4 FLMS load balance strategy
图 4 FLMS负载均衡策略
$
historyBus{y_{源物理{\rm{CPU}}}} + historyLoa{d_{目标虚拟{\rm{CPU}}}} \\
= historyBus{y_{目标物理{\rm{CPU}}}}-historyLoa{d_{目标虚拟{\rm{CPU}}}}
$
(9)
FLMS在Xen-4.4.2中实现, 在物理CPU调度数据结构中增加实时负载与历史负载变量, 并增加一个定时器来更新物理CPU的历史负载; 在虚拟CPU调度数据结构中增加历史负载变量、统计信用值变化的变量以及表示虚拟CPU优先级的变量; 在虚拟域调度数据结构中增加一个变量, 表示其虚拟机类别; 增加两个全局位图, 表示两组物理CPU, 两个栈保存绑定在两组物理CPU位图上的虚拟CPU; 两个负载变量保存一个周期内系统中的总I/O型负载统计值与计算型负载统计值; 一个全局定时器, 设定动态调整的周期.FLMS与默认的Credit调度器相比, 增加的代码行数为1 171行.
4 测试
本节主要是针对FLMS调度算法进行性能评价.测试环境为两台使用万兆网卡连接在同一局域网的主机, 其中一台搭建虚拟化环境, 运行测试虚拟机; 另一台主机使用原生系统配合测试.测试中开启处理器的超线程.系统负载统计值影响因子a、物理CPU历史负载权重因子b、在不同物理核与不同物理封装之间进行虚拟CPU迁移的阈值A, B分别设定为0.125, 0.875, 40, 80.这是在本文的测试环境中经过多次实验, 考虑到系统稳定性以及实时负载对系统的影响而进行的取值.在不同软硬件环境下, 这些因子应该随之变化.在本文的后续工作中, 将会考虑动态设定这些因子的值.目前这些因子的值都是静态预设的.
4.1 I/O性能测试
如第1.1节所述, 当主机的所有虚拟机都没有计算型负载时, 虚拟机的I/O延时普遍很低, 并且也不符合实际的应用场景, 所以在本节测试中使用lookbusy[来为每台虚拟机产生计算型负载, 并配置同等数量的LSVM, NLSVM以及MixVM.如果未作特殊声明, 虚拟机的CPU使用率参数均为50%.
4.1.1 I/O读写测试
本节主要测试FLMS在I/O读写方面的性能, 测试工具为I/O Zone[.I/O Zone是一个文件系统的benchmark工具, 可以测试文件系统的读写性能.测试中运行6台虚拟机.对比LSVM与默认Credit调度器虚拟机的I/O读写性能, 读写文件大小为2GB; Record大小分别为1M, 2M, 4M, 8M;吞吐量单位为KBps.测试结果如
图 5
Fig. 5
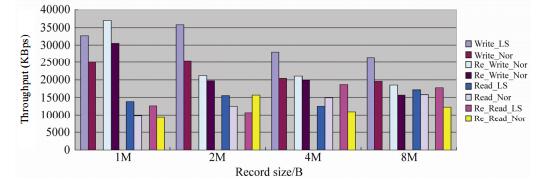
Fig. 5 I/O read-write test
图 5 I/O读写测试
4.1.2 I/O延时和带宽测试
本测试主要对比FLMS的LSVM与默认Credit调度器、I/O bounding方案、vTurbo以及KVM使用virtio环境下虚拟机的I/O延时和带宽性能.测试工具为Ping和Netperf[.Netperf是一种网络性能测量工具, 主要针对基于TCP或UDP的传输.测试结果如
图 6
Fig. 6
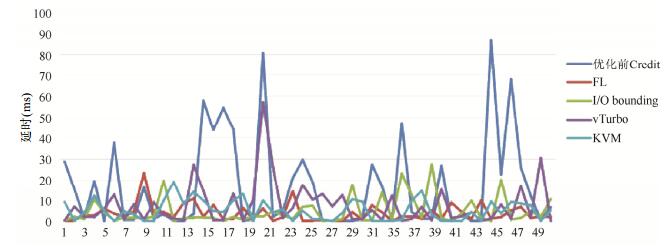
Fig. 6 I/O latency test
图 6 I/O延时测试
图 7
Fig. 7
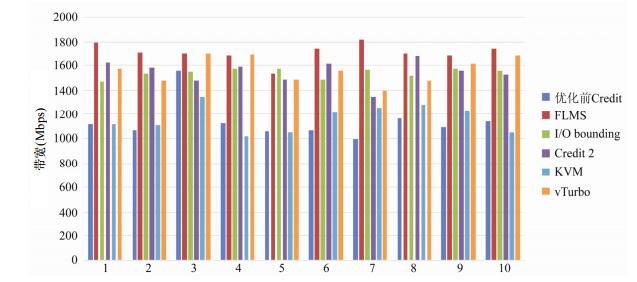
Fig. 7 Throughput test
图 7 带宽测试
表 1(Table 1)
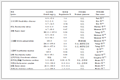
Table 1 Average latency and bandwidth comparison between the schedulers
表 1 调度器之间平均延时和带宽对比
Credit
FLMS
IO bounding
KVM
vTurbo
平均延时(ms)
16.853
3.939
4.794
5.283
7.762
平均带宽(Mbps)
1 135.554
1 708.92
1 535.858
1 165.149
1 561.675
Table 1 Average latency and bandwidth comparison between the schedulers
表 1 调度器之间平均延时和带宽对比
4.1.3 Web压力测试
本节测试使用Webbench[进行虚拟机的Web压力测试.Webbench是一款网站压力测试工具, 可以模拟并发请求, 通过每分钟响应请求数和每秒传输数据量来对比性能.测试中运行8台虚拟机, 在目标虚拟机中搭建Web服务, 并在同一个子网中另一台主机上利用Webbench来产生压力, 测试LSVM与默认Credit调度器的Web压力性能, 测试结果如
图 8
Fig. 8
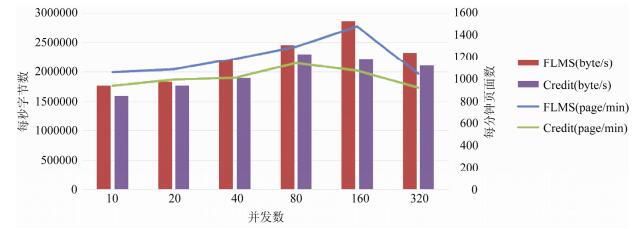
Fig. 8 Web pressure test
图 8 Web压力测试
4.2 负载均衡测试
Xen虽然在4.3版本之后加入了对负载均衡的优化, 但仍然不够完善.本节主要测试FLMS在负载均衡中所带来的改善, 包括在非NUMA和NUMA架构的机器上的测试对比.测试中运行8台虚拟机, 其中4台虚拟机作为空闲虚拟机.另外4台虚拟机作为忙碌的虚拟机, 利用Lookbusy产生系统负载, 在CPU利用率分别为50%, 65%, 80%以及95%的情况下, 进行整个系统中优化前后10s内负载均衡触发次数对比.测试结果如
图 9
Fig. 9
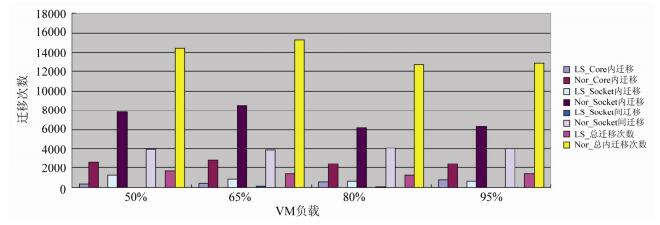
Fig. 9 Load balance test on a non-NUMA machine
图 9 非NUMA结构机器负载均衡测试
图 10
Fig. 10
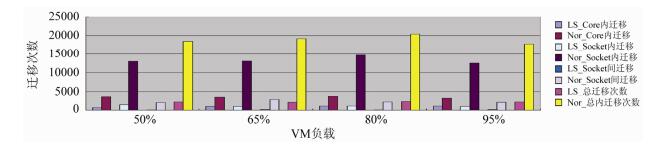
Fig. 10 Load balance test on a NUMA machine
图 10 NUMA结构机器负载均衡测试
FLMS减少了不必要的负载均衡以及远距离的VCPU迁移, 同时带来了性能的提升.如[, 保持100%的CPU使用率, 测试其中一台虚拟机获取最大素数的时间.从测试中发现, 优化后的负载均衡机制相对于默认的Credit算法有17%的提升.
图 11
Fig. 11
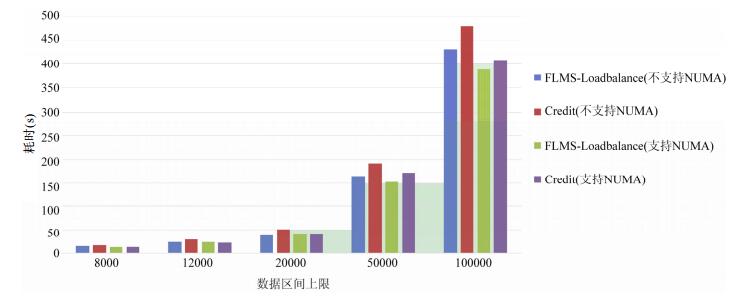
Fig. 11 Load balance test
图 11 负载均衡测试
4.3 计算性能测试
FLMS不仅在I/O性能方面优于默认的Credit调度器, 而且由于负载均衡带来性能的提升, 其计算性能也有一定的提高, 本测试主要对比测试FLMS中NLSVM类型的虚拟机与默认Credit调度器的计算性能.为了保证测试全面, 设计了只有NLSVM以及同时有3类虚拟机情况下的对比.测试中运行8台虚拟机, 在目标虚拟机中运行sysbench达到满负荷求最大素数, 比较两者求出最大素数所用的时间.其余虚拟机运行Lookbusy.每个虚拟机均有4个虚拟CPU, sysbench测试时线程参数设置为4.测试结果如
图 12
Fig. 12
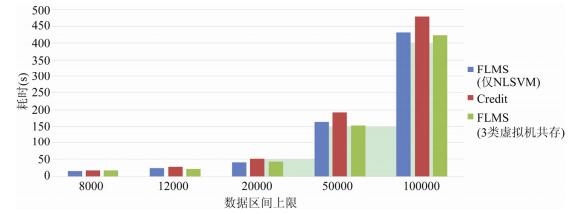
Fig. 12 Computing capability test
图 12 计算性能测试
4.4 公平性测试
FLMS同样继承Credit调度器公平性原则, 虽然对虚拟机进行了类别区分, 并修改了不同类别虚拟机的时间片机制, 但未改变信用值的分配, 因此, 虚拟机之间的公平性仍然可以得到保障.在测试中创建了6个虚拟机, 其中VM 1和VM 2类型为NLSVM, VM 3和VM 4类型为LSVM, VM 5和VM 6类型为MixVM, 每个虚拟机中运行Lookbusy作为虚拟机负载, 在5个不同的时间测试各个虚拟机的CPU使用率.测试结果如
图 13
Fig. 13
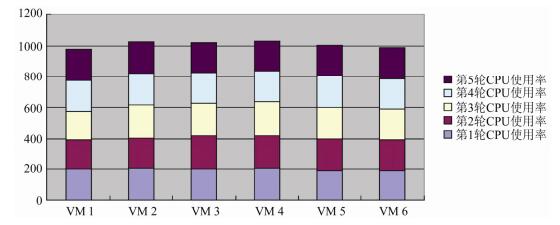
Fig. 13 Fairness test
图 13 公平性测试
5 总结
目前CPU虚拟化与内存虚拟化技术已日趋成熟, 而I/O虚拟化技术的发展却相对滞后, 成为制约虚拟化技术部署的一个瓶颈.现今已有不少研究通过对虚拟CPU的调度算法进行优化来提升I/O性能, 但这些方法大都存在一些局限性.本文针对I/O性能问题提出了一种灵活、高效的虚拟CPU调度算法(FLMS).FLMS通过将I/O型负载与计算型负载运行环境隔离, 为运行I/O负载的虚拟CPU提供了短时间片与高频率的调度, 并且不会影响计算型负载的性能.同时, 根据FLMS的调度架构重新设计了优先级机制, 让I/O任务能够以更高效率执行.此外也考虑到了目前主流的多处理器架构, 优化了负载均衡机制, 减少了远程虚拟CPU迁移, 择优选择目标虚拟CPU.FLMS保证了虚拟机资源公平共享, 具有很好的灵活性, 并且不需要修改操作系统, 有很好的兼容性.
致谢
在此, 我们向对本文的工作给予支持和建议的同行, 尤其是武汉光电国家实验室(华中科技大学)信息存储及应用实验室的老师和同学们表示感谢.














 613
613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









