前言
在之前我们的实战环节中,曾用到
Pandas的
groupby函数来统计一些数据,但在使用过程中,还是显得很笨拙,这一篇文章我们来重新认真梳理一下与
groupby有关的知识,以便于在数据分析中更好的使用。
groupby的实质是将数据按选定的列进行分类合并后再形成一个大的“数据框架”,但这个新形成的“数据框架”却具备了很多统计功能,下面我们来详细说明。
数据准备
学习
Pandas最好的方式即是使用合适的数据,为了更好地研究
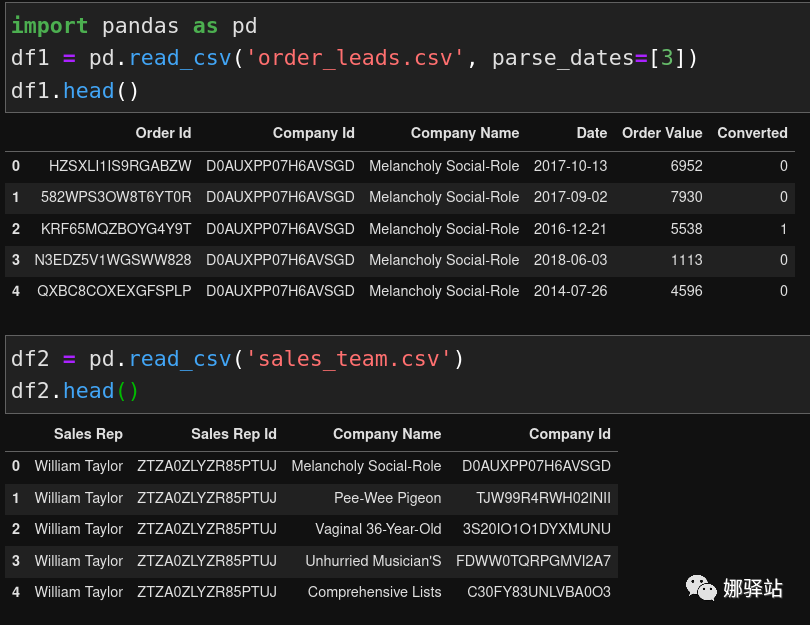
groupby,我们采用一些订单数据,这些数据从
https://github.com/FBosler/Medium-Data-Exploration网站下载,主要下载
order_leads.csv和
sales_team.csv,然后用
Pandas读取:
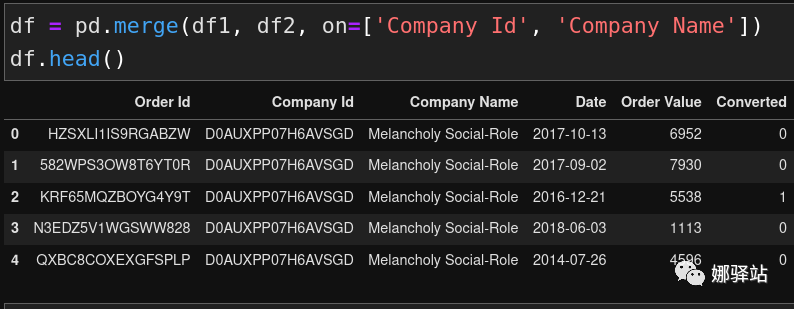
由于两个数据框架都有
Company Name
和
Company Id
列,为了处理数据方便起见,将上面两个数据集进行合并:
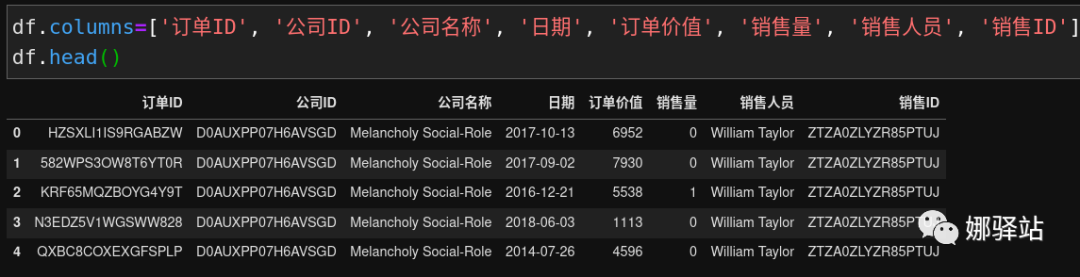
为了对上述数据的列名称方便引用,现将其列名称修改如下:
至此,数据准备完毕。
销售人员分类统计
为了对销售人员的销售记录进行统计,需要将上述数据按
销售人员进行分组:

从上述输出来看,
groupby
返回的是一个
DataFrameGroupBy
对象,在之前我们有提到过,所谓的
groupby
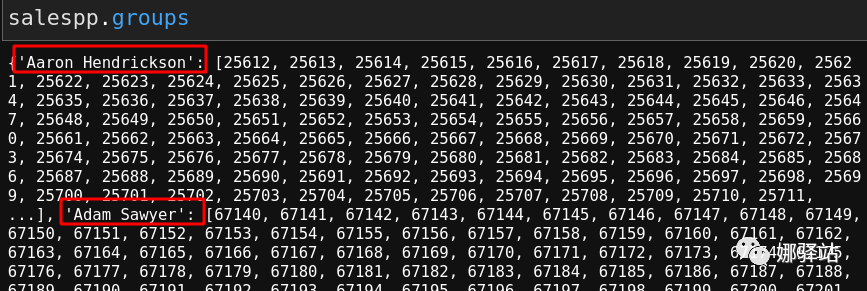
其实就是对某一特定的列分类汇总,如果想看一下刚创建的这个对象中的群组分类,则只需要输入
salespp.groups
即可,显示截图如下:
我们来选择分类群组中的一个特定的人,比如上面的
William Taylor
,可以这样来查询:
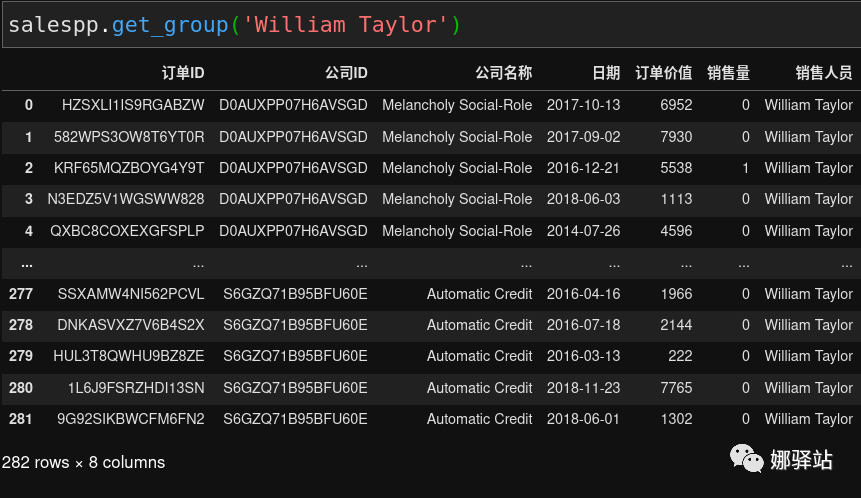
从上面可以看出,名叫
William Taylor
的这个人一共有
282
条记录。
现在我们来查看一下这个群组中各人的销售记录总数:
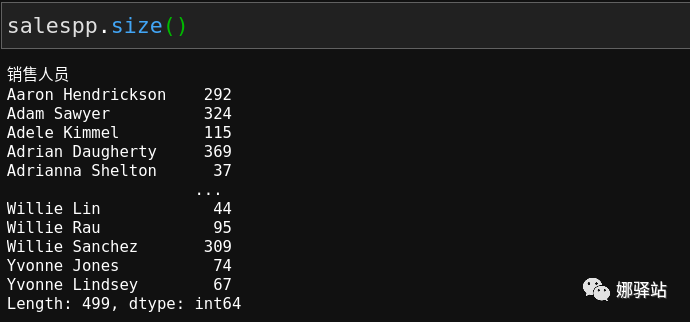
从上述结果可以看出,一共有
499
个人,他们每个人的记录都被汇总在其名字后面。
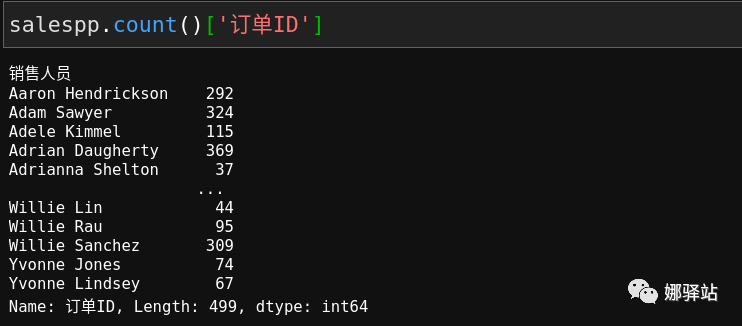
注意: 这一点就比我们之前实战时所用的方法要好得多,当时我们是这样子处理的:
如果我们想按这些销售人员名字的第一部分来进行统计,也是可以的,对于中国人姓名而言,相当于只对其
名字
进行统计,方法如下:

从这个统计与上一个统计相比,可发现,在按名字第一部分进行统计的时候,将名字一样的人进行了合并。
如果我们只想查找叫
William的人的销售记录,可以这样:

由此可见,这个统计是将所有名为
William
的人的名字所销售的记录合在一起了。
将销售额进行分类
在之前介绍
itertools模块的文章中,我们介绍过可以应用它里面的
groupby函数来对数据进行分类,这需要自定义函数。其实在
Pandas中的
groupby功能也是相当强大,它甚至可以自动进行分类,比如现在我们将上述数据集中订单价值自动分为
高、中、低三个档次,可以这样表示:

如果想得到和
itertools
中的
groupby
输出相同,可以用
.groups
属性来得到。
当然,我们可以不用
pd.qcut来自动分类,可以自定义分组的大小,比如:

按时间分组
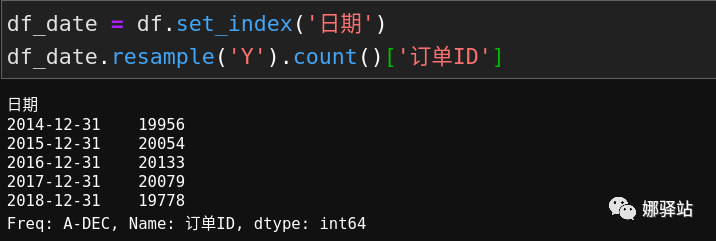
如果按之前我的方法,比如要对上述数据中按
年来汇总的话,是这样处理的:
在
Pandas
中,其实还有一种方法,它用到了
pd.Grouper
函数:
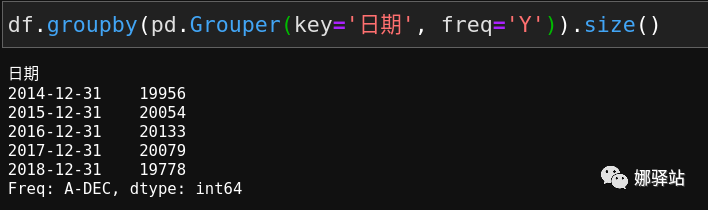
从代码组成来看,第二种方法会感觉更好一点,这里可以做统计周期的参数分别是
Y
、
M
、
D
、
W
和
Q
,它们分别对应
年、月、日、星期、季
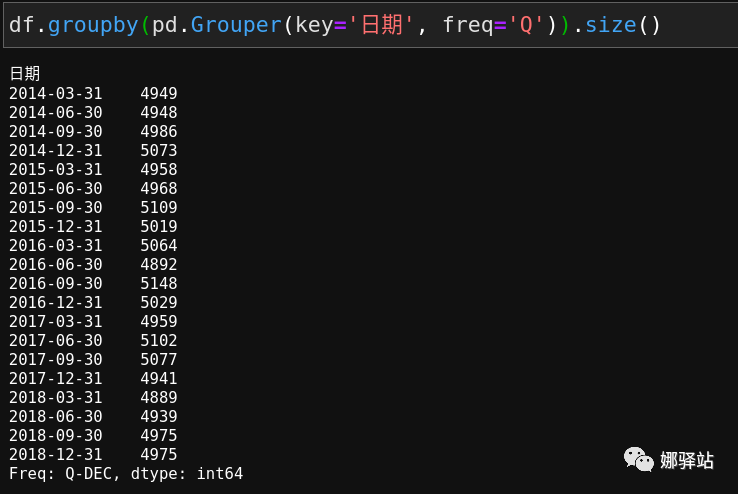
,如果我们按
季
来统计,则代码如下:
按多列的分类汇总与上述相差不多,只不过要注意,当有多个列时,需要将多个列用
[]
括起来作为一个参数。
高级应用
下面我们来研究经常和
groupby相关联的四个函数,这四个函数非常重要,掌握了它们,基本上就掌握了
groupby的高级用法。
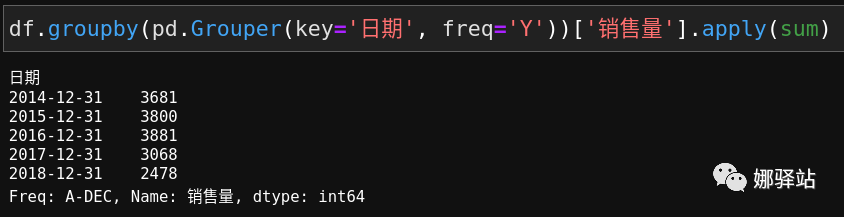
apply
下面我们来对
销售量进行求和,这里用的是
apply函数:
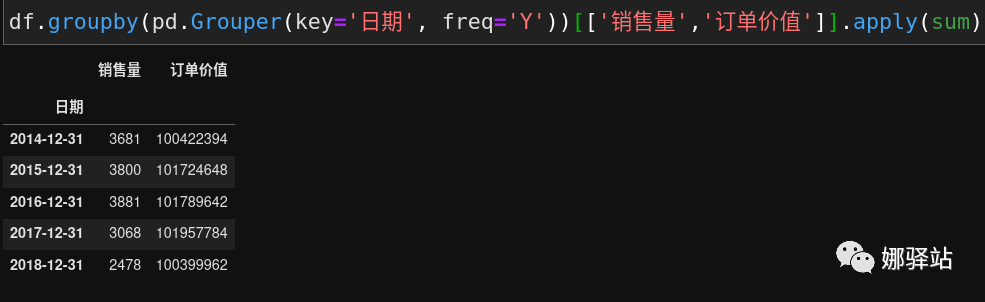
如果对两个量分别进行求和,则可以这样:
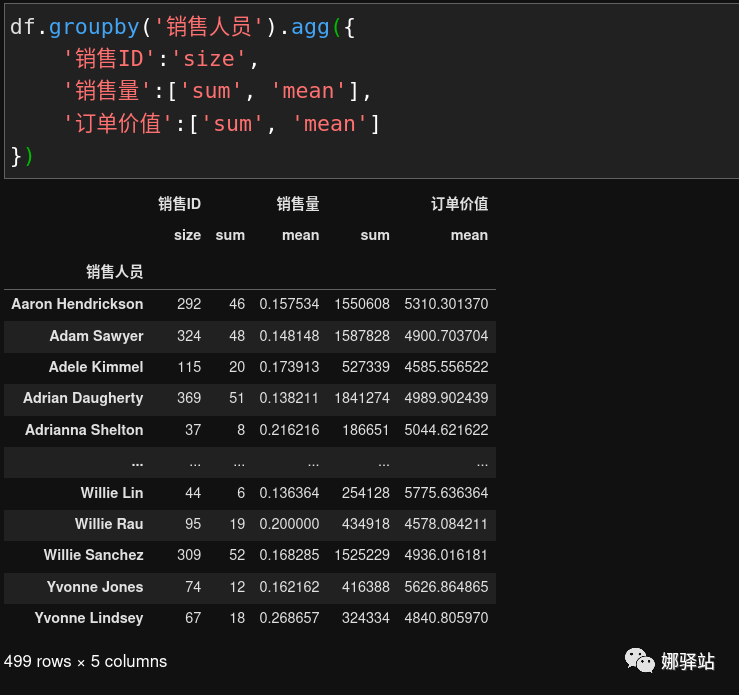
agg
这是聚合函数,它是
aggregate的缩写形式,该函数一般结合求和、求平均或计数等函数一起使用,演示如下:
transform
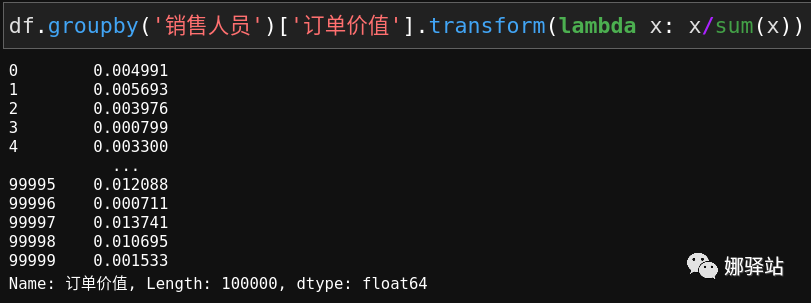
在计算某列值中的每一个占整列和的百分比时,
transform就派上了用场:
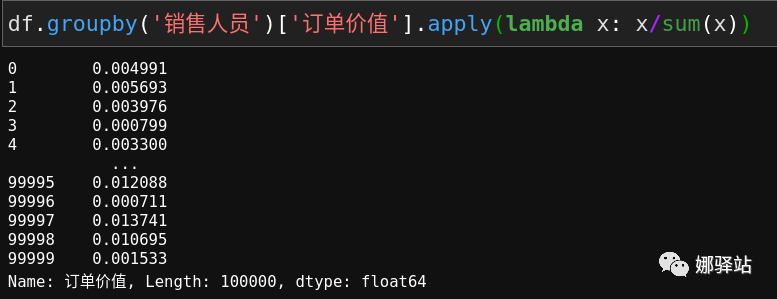
注意,上述代码中的
transform
也可以用
apply
代替:
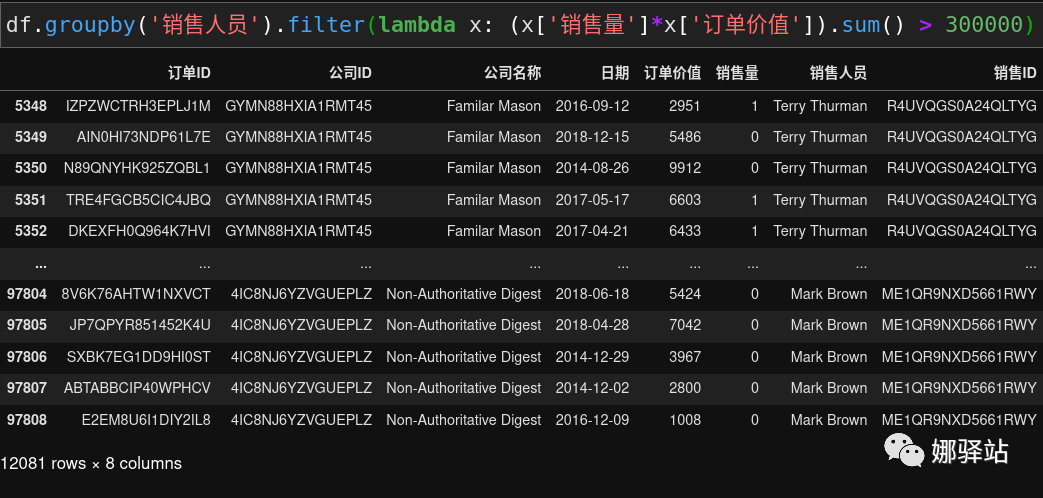
filter
在过滤一些值时我们考虑使用
filter,比如要查看
销售量乘以
订单价值大于
300000的销售人员,可以这样:
在这种情况下,无法用
apply
替代
filter
,再来看一下人均销售量大于
0.3
的人:
小结
本文对
Pandas的
groupby函数进行了详细举例说明,熟练掌握分类汇总,对于我们的日常工作将有极大助益。





















 1658
1658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









