






原标题:Linux性能检测常用的10个基本命令
来源:Linux学习
ID:LoveLinux1024
本文的内容主要来自对Netflix的一篇技术博客( Linux Performance Analysis in 60,000 Milliseconds (https://medium.com/netflix-techblog/linux-performance-analysis-in-60-000-milliseconds-accc10403c55),并添加了一些自己的理解,仅供参考。
1. uptime$ uptime
23:51:26 up 21:31, 1 user, load average: 30.02, 26.43, 19.0212
该命令可以大致的看出计算机的整体负载情况,load average后的数字分别表示计算机在1min、5min、15min内的平均负载。
2. dmesg | tail$ dmesg | tail
[ 1880957.563150] perl invoked oom-killer: gfp_mask= 0x280da, order= 0, oom_score_adj= 0
[ ...]
[ 1880957.563400] Out of memory: Kill process 18694(perl) score 246or sacrifice child
[ 1880957.563408] Killed process 18694(perl) total-vm: 1972392kB, anon-rss: 1953348kB, file-rss: 0kB
[ 2320864.954447] TCP: Possible SYN flooding onport 7001.Dropping request. Check SNMP counters .123456
打印内核环形缓存区中的内容,可以用来查看一些错误;
上面的例子中,显示进程18694 因引内存越界被kill掉以及TCP request被丢弃的错误。通过dmesg可以快速判断是否有导致系统性能异常的问题。
3. vmstat 1$ vmstat 1
procs ---------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cachesi so bi bo incs us sy idwa st
3400200889792737085918280005610961300
320020088992073708591860000592132844282981100
320020089011273708591860000095012154991000
32002008895687371259185600048119002459990000
3200200890208737125918600000158984840981100
^C123456789
打印进程、内存、交换分区、IO和CPU等的统计信息;
vmstat的格式如下
> vmstat[options][delay [count]]
vmstat第一次输出表示从开机到vmstat运行时的平均值;剩余输出的都是在指定的时间间隔内的平均值,上述例子中delay的值设置为1,除第一次以外,剩余的都是1秒统计一次,count未设置,将会一直循环打印。
$ vmstat 10 3
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cachesi so bi bo incs us sy idwa st
10025271121086888137202280011421119900
000252715610868881371985600010430034901009900
00025264121086888137199040001033454870019900123456
上述的例子中delay设置为10,count设置为3,表示每行打印10秒内的平均值,只打印3次。
需要检查的列
r:表示正在运行或者等待CPU调度的进程数。因为该列数据不包含I/O的统计信息,因此可以用来检测CPU是否饱和。若r列中的数字大于CPU的核数,表示CPU已经处于饱和状态。
free:当前剩余的内存;
si, so:交换分区换入和换出的个数,若换入换出个数大于0,表示内存不足;
us, sy, id, wa:CPU的统计信息,分别表示user time、system time(kernel)、idle、wait I/O。I/O处理所用的时间包含在system time中,因此若system time超过20%,则I/O可能存在瓶颈或异常;
4. mpstat -P ALL 1$ mpstat -P ALL
Linux 3.10. 0- 229.el7.x86_64 (localhost.localdomain) 05/ 30/ 2018_x86_64 _( 16CPU)
04: 03: 55PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
04: 03: 55PM all 3.670. 000. 610. 710. 000. 000. 000. 000. 0095.02
04: 03: 55PM 03.520. 000. 570. 760. 000. 000. 000. 000. 0095.15
04: 03: 55PM 13.830. 000. 610. 710. 000. 000. 000. 000. 0094.85
04: 03: 55PM 23.800. 000. 610. 600. 000. 000. 000. 000. 0094.99
04: 03: 55PM 33.680. 000. 580. 600. 000. 000. 000. 000. 0095.13
04: 03: 55PM 43.540. 000. 570. 600. 000. 000. 000. 000. 0095.30
[...] 1234567891011
该命令用于每秒打印一次每个CPU的统计信息,可用于查看CPU的调度是否均匀。
5. pidstat 1$ pidstat 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
07:41:02 PM UID PID %usr %system %guest %CPU CPU Command
07:41:03 PM 0 9 0.00 0.94 0.00 0.94 1 rcuos/0
07:41:03 PM 0 4214 5.66 5.66 0.00 11.32 15 mesos-slave
07:41:03 PM 0 4354 0.94 0.94 0.00 1.89 8 java
07:41:03 PM 0 6521 1596.23 1.89 0.00 1598.11 27 java
07:41:03 PM 0 6564 1571.70 7.55 0.00 1579.25 28 java
07:41:03 PM 60004 60154 0.94 4.72 0.00 5.66 9 pidstat
07:41:03 PM UID PID %usr %system %guest %CPU CPU Command
07:41:04 PM 0 4214 6.00 2.00 0.00 8.00 15 mesos-slave
07:41:04 PM 0 6521 1590.00 1.00 0.00 1591.00 27 java
07:41:04 PM 0 6564 1573.00 10.00 0.00 1583.00 28 java
07:41:04 PM 108 6718 1.00 0.00 0.00 1.00 0 snmp-pass
07:41:04 PM 60004 60154 1.00 4.00 0.00 5.00 9 pidstat
^C123456789101112131415161718
该命令用于打印各个进程对CPU的占用情况,类似top命令中显示的内容。pidstat的优势在于,可以滚动的打印进程运行情况,而不像top那样会清屏。
上述例子中,%CPU中两个java进程的cpu利用率分别达到了1590%和1573%,表示java进程占用了16颗CPU。
6. iostat -xz 1
类似vmstat,第一次输出的是从系统开机到统计这段时间的采样数据;
$ iostat -xz 1
Linux 3.13. 0- 49-generic (titanclusters-xxxxx) 07/ 14/ 2015_x86_64 _( 32CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
73.960. 003.730. 030. 0622.21
Device: rrqm/ swrqm/ sr/ sw/ srkB/ swkB/ savgrq-sz avgqu-sz await r_await w_await svctm %util
xvda 0. 000. 230. 210. 184.522.0834.370. 009.9813.805.422.440.09
xvdb 0. 010. 001.028.94127.97598.53145.790. 000. 431.780. 280. 250. 25
xvdc 0. 010. 001.028.86127.79595.94146.500. 000. 451.820. 300. 270. 26
dm- 00. 000. 000. 692.3210.4731.6928.010. 013.230. 713.980. 130. 04
dm- 10. 000. 000. 000. 940. 013.788.000. 33345.840. 04346.810. 010. 00
dm- 20. 000. 000.09 0. 071.350. 3622.500. 002.550. 235.621.780. 03
[...]
^C123456789101112131415
检查列
r/s, w/s, rkB/s, wkB/s,表示每秒向I/O设备发出的reads、writes、read Kbytes、write Kbytes的数量。
await,表示应用程序排队等待和被服务的平均I/O时间,该值若大于预期的时间,这表示I/O设备处于饱和状态或者异常。
avgqu-sz,表示请求被发送给I/O设备的平均时间,若该值大于1,则表示I/O设备可能已经饱和;
%util,每秒设备的利用率;若该利用率超过60%,则表示设备出现性能异常;
7. free -m$ free-m
total used freeshared buffers cached
Mem: 245998245452214538359541
-/+ buffers/cache: 23944222053
Swap: 00012345
检查的列:
buffers: For the buffer cache, used for block device I/O.
cached: For the page cache, used by file systems.
若buffers和cached接近0,说明I/O的使用率过高,系统存在性能问题。
Linux中会用free内存作为cache,若应用程序需要分配内存,系统能够快速的将cache占用的内存回收,因此free的内存包含cache占用的部分。
8. sar -n DEV 1
sar是System Activity Reporter的缩写,系统活动状态报告。
-n { keyword [,…] | ALL },用于报告网络统计数据。keyword可以是以下的一个或者多个: DEV, EDEV, NFS, NFSD, SOCK, IP, EIP, ICMP, EICMP, TCP, ETCP, UDP, SOCK6, IP6, EIP6, ICMP6, EICMP6 和UDP6。
-n DEV 1, 每秒统计一次网络的使用情况;
-n EDEV 1,每秒统计一次错误的网络信息;
$ sar -n DEV 1
Linux 3.10.0-229.el7.x86_64 (localhost.localdomain) 05/31/2018 _x86_64_ (16 CPU)
03:54:57 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
03:54:58 PM ens32 3286.00 7207.00 283.34 18333.90 0.00 0.00 0.00
03:54:58 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
03:54:58 PM vethe915e51 0.00 0.00 0.00 0.00 0.00 0.00 0.00
03:54:58 PM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00
03:54:58 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
03:54:59 PM ens32 3304.00 7362.00 276.89 18898.51 0.00 0.00 0.00
03:54:59 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
03:54:59 PM vethe915e51 0.00 0.00 0.00 0.00 0.00 0.00 0.00
03:54:59 PM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00
^C123456789101112131415
IFACE ,网络接口名称;
rxpck/s ,每秒接收到包数;
txpck/s ,每秒传输的报数;(transmit packages)
rxkB/s ,每秒接收的千字节数;
txkB/s ,每秒发送的千字节数;
rxcmp/s ,每秒接收的压缩包的数量;
txcmp/s ,每秒发送的压缩包的数量;
rxmcst/s,每秒接收的组数据包数量;
9. sar -n TCP,ETCP 1
该命令可以用于粗略的判断网络的吞吐量,如发起的网络连接数量和接收的网络连接数量;
TCP, 报告关于TCPv4网络流量的统计信息;
ETCP, 报告有关TCPv4网络错误的统计信息;$ sar -n TCP,ETCP 1
Linux 3.10.0-514.26.2.el7.x86_64 (aushop) 05/31/2018 _x86_64_ (2 CPU)
04:16:27 PM active/s passive/s iseg/s oseg/s
04:16:44 PM 0.00 2.00 15.00 13.00
04:16:45 PM 0.00 3.00 126.00 203.00
04:16:46 PM 0.00 0.00 99.00 99.00
04:16:47 PM 0.00 0.00 18.00 9.00
04:16:48 PM 0.00 0.00 5.00 6.00
04:16:49 PM 0.00 0.00 1.00 1.00
04:16:50 PM 0.00 1.00 4.00 4.00
04:16:51 PM 0.00 3.00 171.00 243.00
^C12345678910111213
检测的列:
active/s: Number of locally-initiated TCP connections per second (e.g., via connect()),发起的网络连接数量;
passive/s: Number of remotely-initiated TCP connections per second (e.g., via accept()),接收的网络连接数量;
retrans/s: Number of TCP retransmits per second,重传的数量;
10. top
top命令包含更多的指标统计,相当于一个综合命令。
$ top
top - 00:15:40 up 21:56, 1 user, loadaverage: 31.09, 29.87, 29.92
Tasks: 871total, 1running, 868sleeping, 0stopped, 2zombie
%Cpu(s): 96.8us, 0.4sy, 0.0ni, 2.7id, 0.1wa, 0.0hi, 0.0si, 0.0st
KiB Mem: 25190241+total, 24921688used, 22698073+free, 60448buffers
KiB Swap: 0total, 0used, 0free. 554208cached Mem
PID USERPR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
20248root 2000.227t 0.012t 18748S 30905.229812: 58java
4213root 20027225446464044232S 23.50.0233: 35.37mesos- slave
66128titancl+ 2002434423321172R 1.00.00: 00.07top
5235root 20038.227g 54700449996S 0.70.22: 02.74java
4299root 20020.015g 2.682g 16836S 0.31.133: 14.42java
1root 2003362029201496S 0.00.00: 03.82init
2root 200000S 0.00.00: 00.02kthreadd
3root 200000S 0.00.00: 05.35ksoftirqd/ 0
5root 0-20000S 0.00.00: 00.00kworker/ 0: 0H
6root 200000S 0.00.00: 06.94kworker/u256: 0
8root 200000S 0.00.02: 38.05rcu_sched12345678910111213141516171819
11. 总结
下面的图片很好的展示了各个命令的主要作用,如使用vmstat查看系统的整体性能,mpstat用于查看cpu的性能,pidstat用于查看进程的状态,iostat用于查看io的状态,free用于产看内存的状态,sar用于产看网络的状态等。

image.png Linux常用性能工具一览
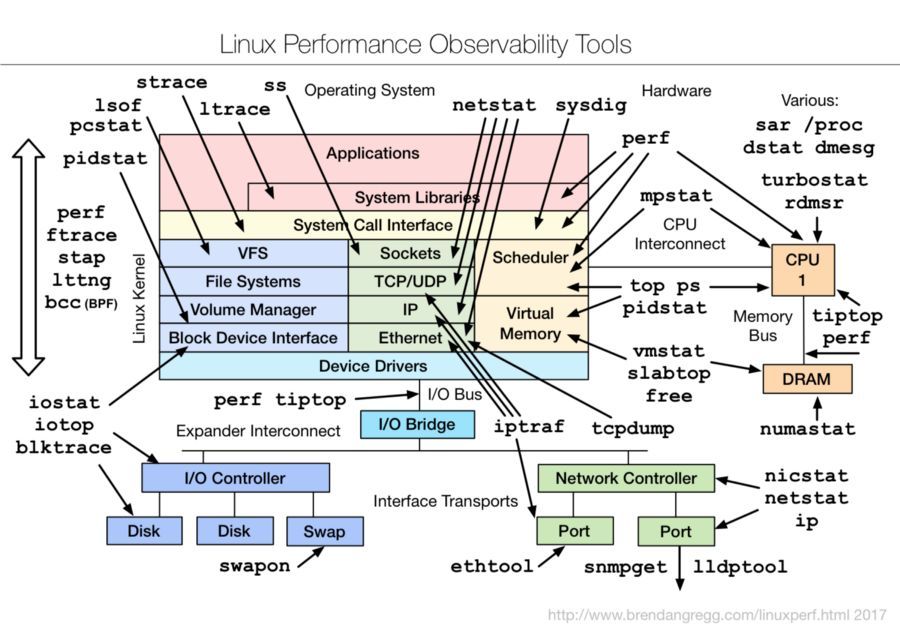
Linux Performance Tools 参考
性能不好怎么办?对着清单撸一遍
Linux Performance Analysis in 60,000 Milliseconds
Netflix常用性能测试工具视频教程
作者:guoxiaojie_415
来自:https://blog.csdn.net/guoxiaojie_415/article/details/80526667
*声明:推送内容及图片来源于网络,部分内容会有所改动,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜。
责任编辑:















 353
353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









