






这篇文章主要简单的了解MySQL union all与union的区别,文中通过示例代码介绍的还是非常详细的,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下。
union 是对数据进行并集操作,不包括重复行,同时进行默认排序
union all 也是对数据进行并集操作,包括重复行,并且不进行排序
以下进行举例说明,创建两张表demo1和demo2,然后通过union和union all关联,查看获取的数据情况。
创建demo1表:
CREATE TABLE `demo1` (
`id` int(32) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`age` int(2) DEFAULT NULL,
`num` int(3) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
创建demo2表:
CREATE TABLE `demo2` (
`id` int(32) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`age` int(2) DEFAULT NULL,
`num` int(3) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
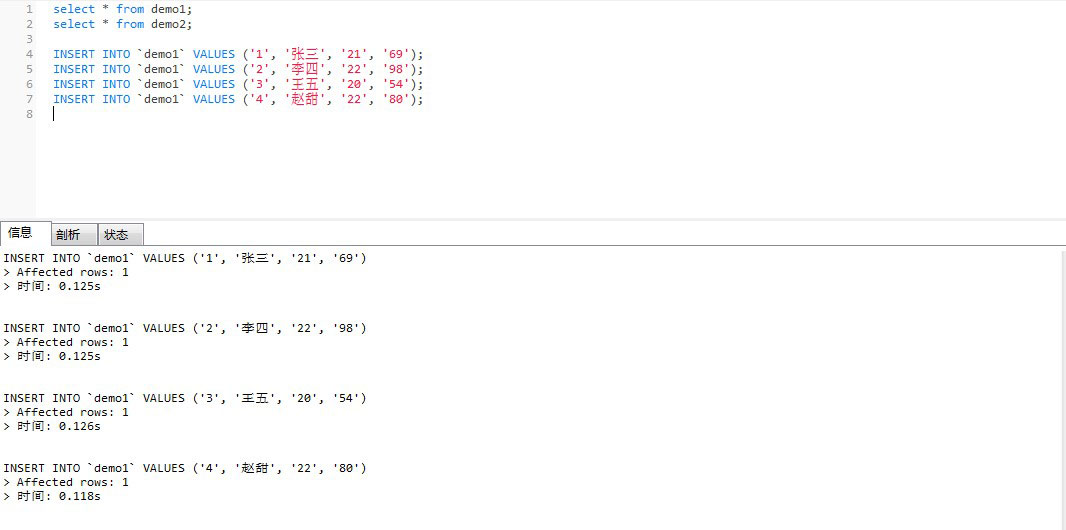
向demo1中插入数据:
INSERT INTO `demo1` VALUES ('1', '张三', '21', '69');
INSERT INTO `demo1` VALUES ('2', '李四', '22', '98');
INSERT INTO `demo1` VALUES ('3', '王五', '20', '54');
INSERT INTO `demo1` VALUES ('4', '赵甜', '22', '80');
如图所示:
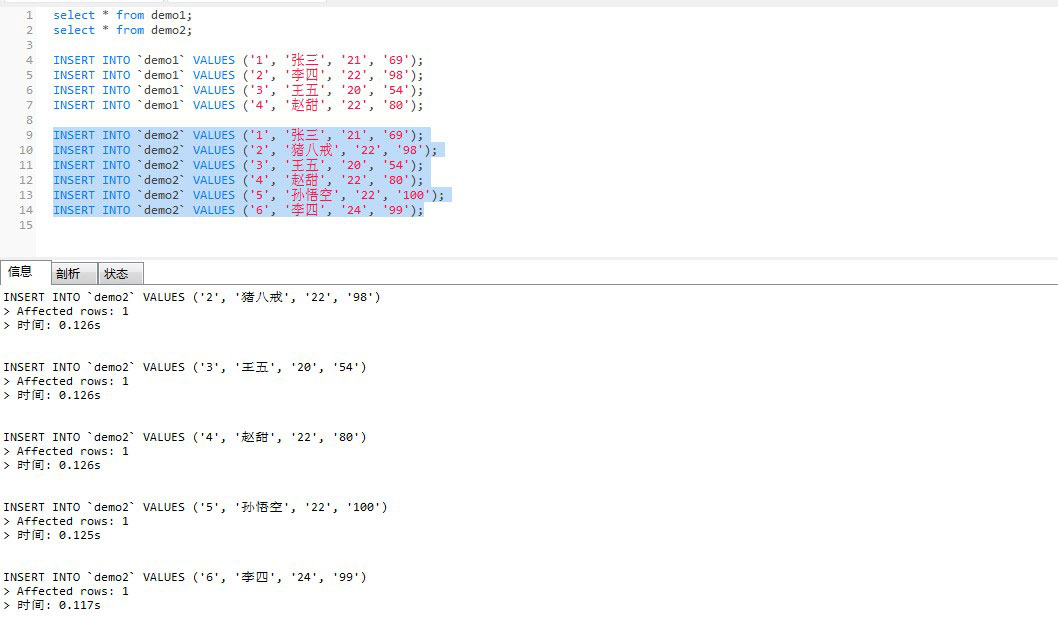
向demo2中插入数据:
INSERT INTO `demo2` VALUES ('1', '张三', '21', '69');
INSERT INTO `demo2` VALUES ('2', '猪八戒', '22', '98');
INSERT INTO `demo2` VALUES ('3', '王五', '20', '54');
INSERT INTO `demo2` VALUES ('4', '赵甜', '22', '80');
INSERT INTO `demo2` VALUES ('5', '孙悟空', '22', '100');
INSERT INTO `demo2` VALUES ('6', '李四', '24', '99');
如图所示:
通过union关联的数据
SELECT * FROM demo1
UNION
SELECT * FROM demo2;
查询结果:
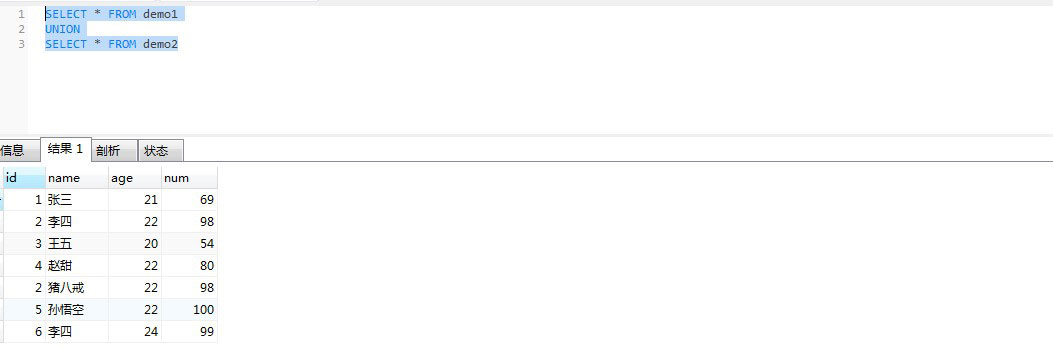
我们从上面的查询数据可以发现:
UNION在进行表链接后会筛选掉重复的记录,对所产生的结果集进行排序运算,删除重复的记录再返回结果。
通过union all关联的数据
SELECT * FROM demo1
UNION ALL
SELECT * FROM demo2;
查询结果:

从上面数据我们可以看到:
UNION ALL只是简单的将两个结果合并后就返回。如果返回的两个结果集中有重复的数据,那么返回的结果集就会包含重复的数据了。
对于效率上说,UNION ALL 要比UNION快很多,因为不进行排序,同时不会检查重复数据,所以,如果可以确认合并的两个结果集中不包含重复数据且不需要排序时的话,那么就使用UNION ALL。
以上就是提灯小生介绍的全部内容,希望对大家的学习有所帮助,也希望大家多多支持提灯小生。















 449
449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









