






实验设备
用于mongodb集群节点的设备
主机:8台
CPU:8核Intel(R) Xeon(R) CPU E5-2650 v3 @ 2.30GHz
内存:32G
磁盘:SSD
系统:Linux 3.10.0-229.el7.x86_64 CentOS 7.1
运行环境
集群:使用mongodb-3.2.6,每台主机一个shard组成分片集群,每台主机一个路由(mongos)作为入口。
准备工作,参考官方文档:
关闭透明大页。
关闭atime。
增加mongodb运行用户的最大进程数。
实验数据和方法
数据库和集合开启分片后导入bson格式数据文件。
小文档数据:
data : 697.67MiB docs : 17013091 avg obj size :43B
大文档数据:
data : 64.33GiB docs : 22504206 avg obj size :3KiB
施压端程序用java语言编写,mongodb-java-driver使用3.2版本,源码见这里,支持操作如下:
find_first:根据主键id查询数据。
find_in:根据一批主键批量查询数据,批量大小为40。
find:根据主键id大于随机值的一批数据,限制返回100到10100条。
find_update:根据键id查询数据,并保持原状执行更新(即包含一次查询和一次更新)。
find_insert:根据键id查询数据,并插入到同结构的copy表(即包含一次查询和一次插入)。
find_delete:根据键id查询数据,并根据id从copy表删除数据(即包含一次查询和一次删除)。
实验用例
用例一
仅向一台主机的mongos施压,根据实际情况调整线程数为接近最优(即再增加施压主机或增大线程数,每秒并发完成数增加不明显甚至造成每次耗时增大)。
【操作】
【数据】
【线程数】
【每秒并发完成数】
【每次耗时(毫秒)】
【入网流量(MBit/s)】
【出网流量(MBit/s)】
【负载】
find_first
大
80
26000+
3
700+
700+
16+
find_update
大
80
13000+
6
700+
700+
16+
find_first
小
80
37000+
2
130+
130+
17+
find_update
小
80
21000+
3
130+
170+
19+
find
小
4
70+
50+
1010+ 占满
200+
3+
find_first
(4核主机部署的mongos)
小
80
25000+
3
100+
100+
15+
初步结论:
mongos的吞吐量直接与CPU性能、数据文档大小关联。CPU性能越高核数越多、文档越小,吞吐量越大。
集群环境下使用不能通过片键定位某个shard的条件查询时,mongos会向所有shard发起请求,汇总数据加工处理后再返回给客户端。此时如果符合条件的数据集较大,会造成mongos机的入网带宽压力变大,甚至成为瓶颈。
用例二
测试关闭tuned服务对集群性能的影响,施压过程中关闭tuned观察变化。
systemctl stop tuned
systemctl status tuned
调整后以find_first小文档数据为例,发现每秒并发完成数由37000下降到23000。
【操作】
【数据】
【线程数】
【每秒并发完成数】
【每次耗时(毫秒)】
【入网流量(MBit/s)】
【出网流量(MBit/s)】
【负载】
find_first
小
80
23000+
2
90+
90+
9+
对比前后的sysctl配置如下图:
# 输出sysctl配置到文件
sysctl -a > sysctl.002
# 对比文件差异
diff sysctl.001 sysctl.002
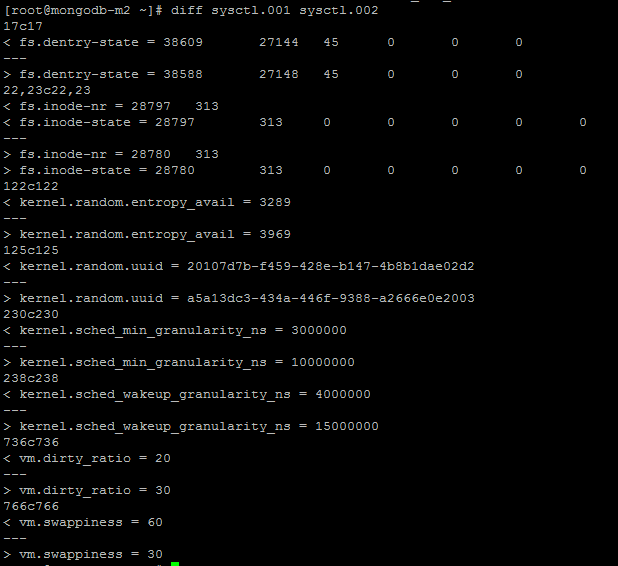
发现kernel.sched_min_granularity_ns和kernel.sched_wakeup_granularity_ns变化明显。实际上这两个参数是tuned进程在动态调优过程中自动调整到合适的值(10000000和15000000),关闭tuned后动态调整的参数恢复原样(3000000和4000000)。关闭tuned后如果手动调整者两个参数将起到同样调优效果。
sysctl -w kernel.sched_min_granularity_ns=10000000
sysctl -w kernel.sched_wakeup_granularity_ns=15000000
初步结论:
一般情况下借住tuned可以自动调优。
mongodb集群性能受kernel.sched_min_granularity_ns和kernel.sched_wakeup_granularity_ns影响。
用例三
测试均衡软中断对集群性能的提升。
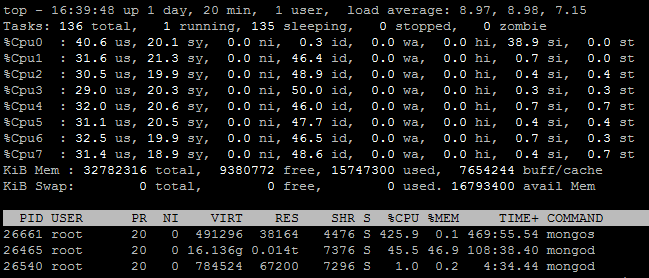
在未做调整前,观察到由于网络IO引起的CPU每秒中断次数较多。统计显示软中断集中由CPU的某一个核处理(通常是第0或者第1个),该核空闲率几乎为0造成瓶颈,而其他核空闲率相对较高,由此造成CPU资源没有充分利用。如下图:
top
# 然后输入1
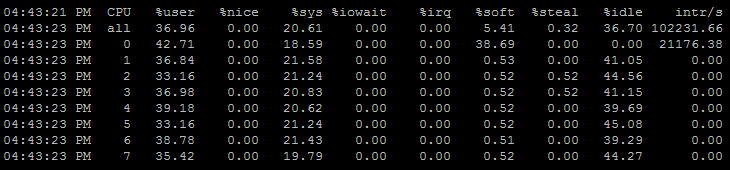
或者
mpstat -P ALL 2
CentOS从6.1开始支持RPS(Receive Packet Steering),通过修改RPS配置来调优。参考
查看/sys/class/net/eth0/queues/rx-0/rps_cpus的值为00,表示软中断由第一个核处理。该值计算方法如下:对于8核来讲,第一个是00000001,第二个是00000010,依次类推,第8个是10000000。如果要所有核负担则相加8个值,得到的数值为11111111,转十六进制是ff。如果要后7个核负担则得到数值11111110,转十六进制是fe。
#echo ff > /sys/class/net/eth0/queues/rx-0/rps_cpus
echo fe > /sys/class/net/eth0/queues/rx-0/rps_cpus
调整后如下图(尽管不是很均衡,但是优化后效果明显~):
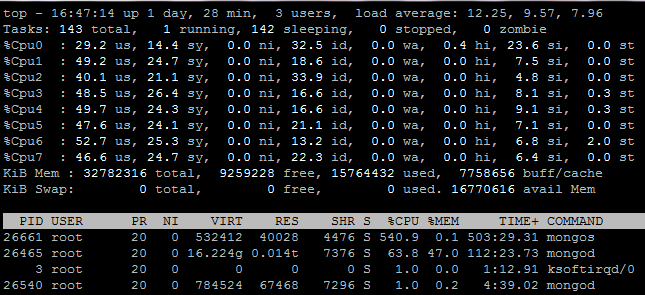
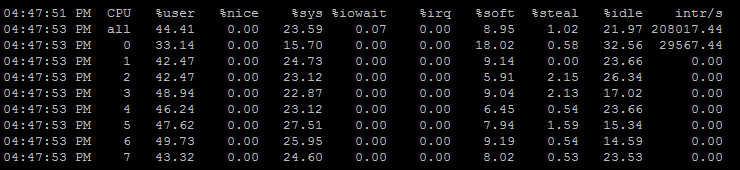
以find_first小文档数据为例,发现每秒并发完成数由37000提高到44000。
【操作】
【数据】
【线程数】
【每秒并发完成数】
【每次耗时(毫秒)】
【入网流量(MBit/s)】
【出网流量(MBit/s)】
【负载】
find_first
小
80
44000+
2
160+
160+
26+
初步结论:
多核CPU主机通过均衡软中断在核之间的分布可以有效提高CPU利用率,提升mongodb集群吞吐量。
用例四
使用多个施压主机分别向四个mongos施压,所有主机均已完成上述调优。
以小文档数据为例,四台主机的表现如下,整体带来乘以4的每秒并发完成数。
【操作】
【数据】
【线程数】
【每秒并发完成数】
【每次耗时(毫秒)】
【入网流量(MBit/s)】
【出网流量(MBit/s)】
【负载】
find_first
小
80
31000+
2
140+
140+
21+
find_update_one
小
80
17000+
4
140+
140+
20+
find_in
小
80
3000+
24
130+
170+
40+
初步结论:
mongodb集群环境的整体性能还是比较出色的。
mongos和shard都是多线程的方式处理请求的。mongos启动时会根据CPU核数启动相应个数的主线程,负责向各个shard发起数据请求并接收响应,而客户端进来的请求首先通过mongos创建的新线程接收,然后交给前面的主线程处理,完成后再由该新线程将结果返回给客服端。所以并发较高的时候通常都是向shard分发请求的那几个mongos线程比较繁忙。

本文基于署名-非商业性使用-相同方式共享 4.0许可协议发布,欢迎转载、使用、重新发布,但请保留文章署名wanghengbin(包含链接:https://wanghengbin.com),不得用于商业目的,基于本文修改后的作品请以相同的许可发布。















 485
485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









