







概要:
0. 问题背景
1. Stream Job的切分
2. 计算资源的调度 & 任务的执行
3. 最后的总结
0. 问题背景:
开始用flink处理流式作业的时候,用yarn-cluster模式提交作业的时候,脚本如下:
$FLINK_BIN run -m yarn-cluster -yqu root.profile -yn 20 -yjm 4096 -ytm 8192 -ynm RecentViewApp -ys 5 ./profileStreaming-0.1.jar
(程序中设置的并行度都是5)
脚本参数的解释:
-yn 要分配的YARN container数(Task Managers个数)
-yjm JobManager内存
-ytm 每个TaskManager内存
-ys 每个TaskManager的slot数
比较奇怪的是,作业webUI的资源配置跟脚本上的资源分配不符合,而且启动的时候会有动态变化,下面两个截图,一个是最大资源的时候(图1.),一个是最终稳定资源的时候(图2.),而且经过测试调整yn参数,发现并没有发生变化,这里TaskManager和Task Slots是根据什么进行分配的似乎让人捉摸不定。
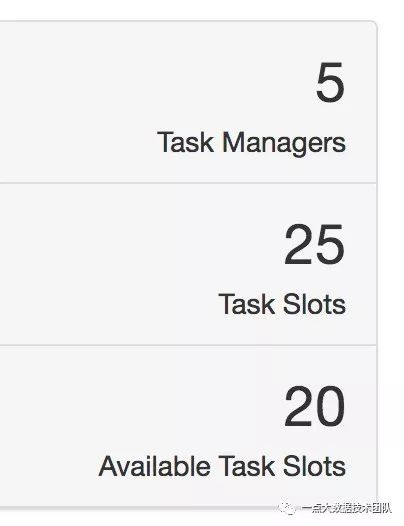
图1
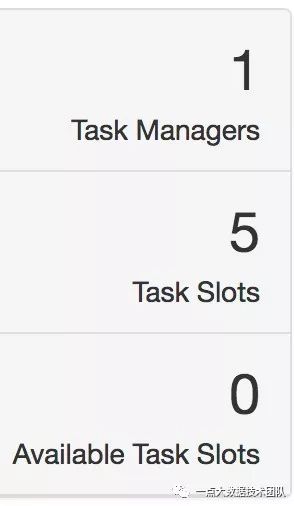
图2
1. Stream Job的切分
跟了下源码,分析这现象的原因(基于1.6.0版本的)
首先,要知道flink on yarn是怎么做资源分配之前,必须先要了解一个Stream job提交到flink是怎么进行job的切分的。首先程序构建成StreamGraph --> JobGraph,在生成JobGraph的时候,有几个重要的地方,见图4红色标记部分,然后提交到flink集群上,flink再对JobGraph转换ExecutionGraph,其实到ExecutionGraph这步就是为了后续的调度任务存在的,可以发现,ExecutionGraph(准确来说是有ExecutionJobVertex这个结构,而ExecutionJobVertex下又套有ExecutionVertex, Execution)下有这几种数据结构(图3):
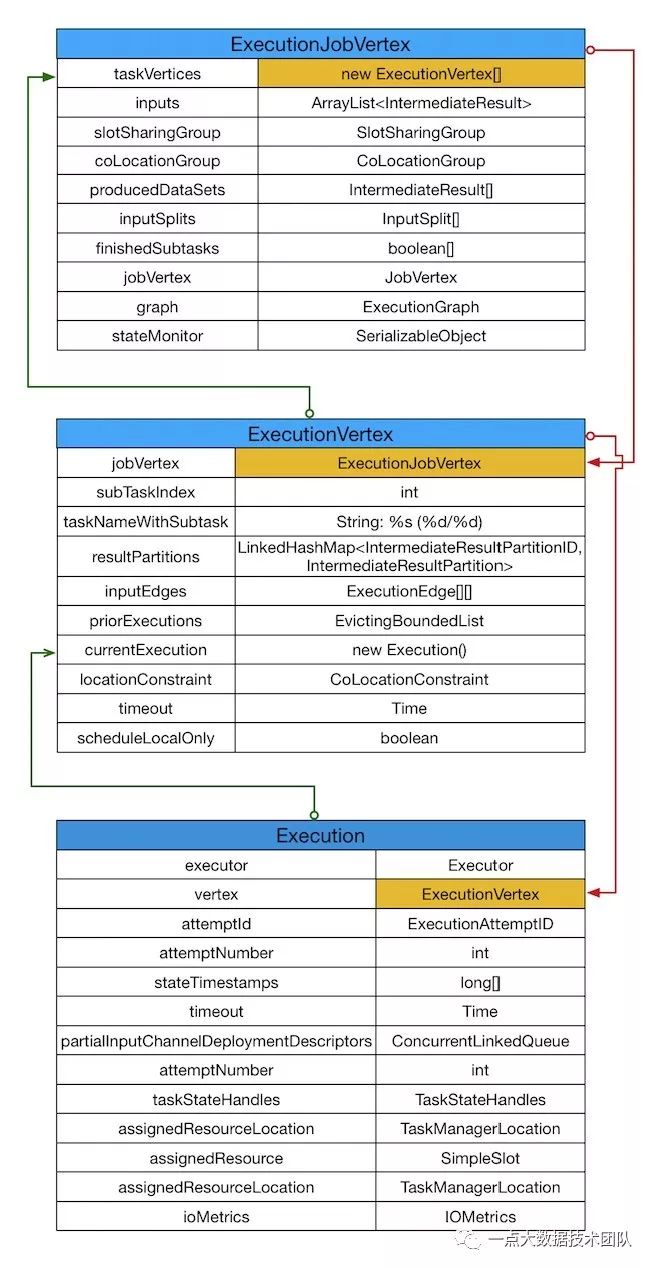
图3
ExecutionGraph这里就已经可以进行任务调度了:
1. 一个task任务对应一个executor,后面会看到execution调用deploy就起一个任务;
2.IntermediateResultPartition对应ResultPartition,这两个本质上是相等的,只不过IntermediateResultPartition是ExecutionGraph调度阶段的概念,而ResultPar
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3513
3513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









