






在我们使用Python来和数据库打交道中,SQLAlchemy是一个非常不错的ORM工具,通过它我们可以很好的实现多种数据库的统一模型接入,而且它提供了非常多的特性,通过结合不同的数据库驱动,我们可以实现同步或者异步的处理封装。
1、SQLAlchemy介绍
SQLAlchemy 是一个功能强大且灵活的 Python SQL 工具包和对象关系映射(ORM)库。它被广泛用于在 Python 项目中处理关系型数据库的场景,既提供了高级的 ORM 功能,又保留了对底层 SQL 语句的强大控制力。SQLAlchemy 允许开发者通过 Python 代码与数据库进行交互,而无需直接编写 SQL 语句,同时也支持直接使用原生 SQL 进行复杂查询。下面是SQLAlchemy和我们常规数据库对象的对应关系说明。
Engine 连接对象 驱动引擎
Session 连接池 事务 由此开始查询
Model 表 类定义
Column 列
Query 若干行 可以链式添加多个条件
在使用SQLAlchemy时,通常会将其与数据库对象对应起来。以下是SQLAlchemy和常规数据库对象的对应关系说明:
1)数据库表 (Database Table)
- SQLAlchemy: 使用
Table对象或Declarative Base中的类来表示。 - 对应关系: 数据库中的每一个表对应于SQLAlchemy中的一个类,该类继承自
declarative_base()。
2)数据库列 (Database Column)
- SQLAlchemy: 使用
Column对象来表示。 - 对应关系: 每个数据库表中的列在SQLAlchemy中表示为
Column对象,并作为类的属性定义。
3)数据库行 (Database Row)
- SQLAlchemy: 每个数据库表的一个实例(对象)代表数据库表中的一行。
- 对应关系: 在SQLAlchemy中,通过实例化模型类来表示数据库表中的一行。
4)主键 (Primary Key)
- SQLAlchemy: 使用
primary_key=True参数定义主键。 - 对应关系: 在数据库表中定义主键列,这列在SQLAlchemy中也需要明确标注。
5)外键 (Foreign Key)
- SQLAlchemy: 使用
ForeignKey对象来表示。 - 对应关系: 在SQLAlchemy中使用
ForeignKey指定关系,指向另一个表的主键列。
6)关系 (Relationships)
- SQLAlchemy: 使用
relationship对象来表示。 - 对应关系: 数据库中表与表之间的关系在SQLAlchemy中通过
relationship来定义。
7)会话 (Session)
- SQLAlchemy: 使用
Session对象进行事务性操作(如查询、插入、更新、删除)。 - 对应关系:
Session对象类似于数据库连接对象,用于与数据库进行交互。
通过以上对应关系,SQLAlchemy允许开发者以面向对象的方式与数据库交互,提供了一个Pythonic的接口来操作数据库。
2、SQLAlchemy 的同步操作
SQLAlchemy 提供了同步和异步两种操作方式,分别适用于不同的应用场景。以下是如何封装 SQLAlchemy 的同步和异步操作的方法说明:
在同步操作中,SQLAlchemy 使用传统的阻塞方式进行数据库操作。首先,定义一个基础的 Session 和 Engine 对象:
前面说了,使用SQLAlchemy可以实现不同数据库的统一模型的处理,我们可以对应创建不同数据库的连接(engine),如下是常规几种关系型数据库的连接处理。
我们可以根据数据库的CRUD操作方式,封装一些操作,如下所示。
使用时,构建数据访问类进行操作,如下测试代码所示。
3、SQLAlchemy 的异步操作封装
对于异步操作,SQLAlchemy 使用 AsyncSession 来管理异步事务。
首先,定义一个异步的 Session 和 Engine 对象:
和同步的处理类似,不过是换了一个对象来实现,并且函数使用了async await的组合来实现异步操作。
为了实现我的SQLSugar开发框架类似的封装模式,我们参考SQLSugar开发框架中基类CRUD的定义方式来实现多种接口的封装处理。
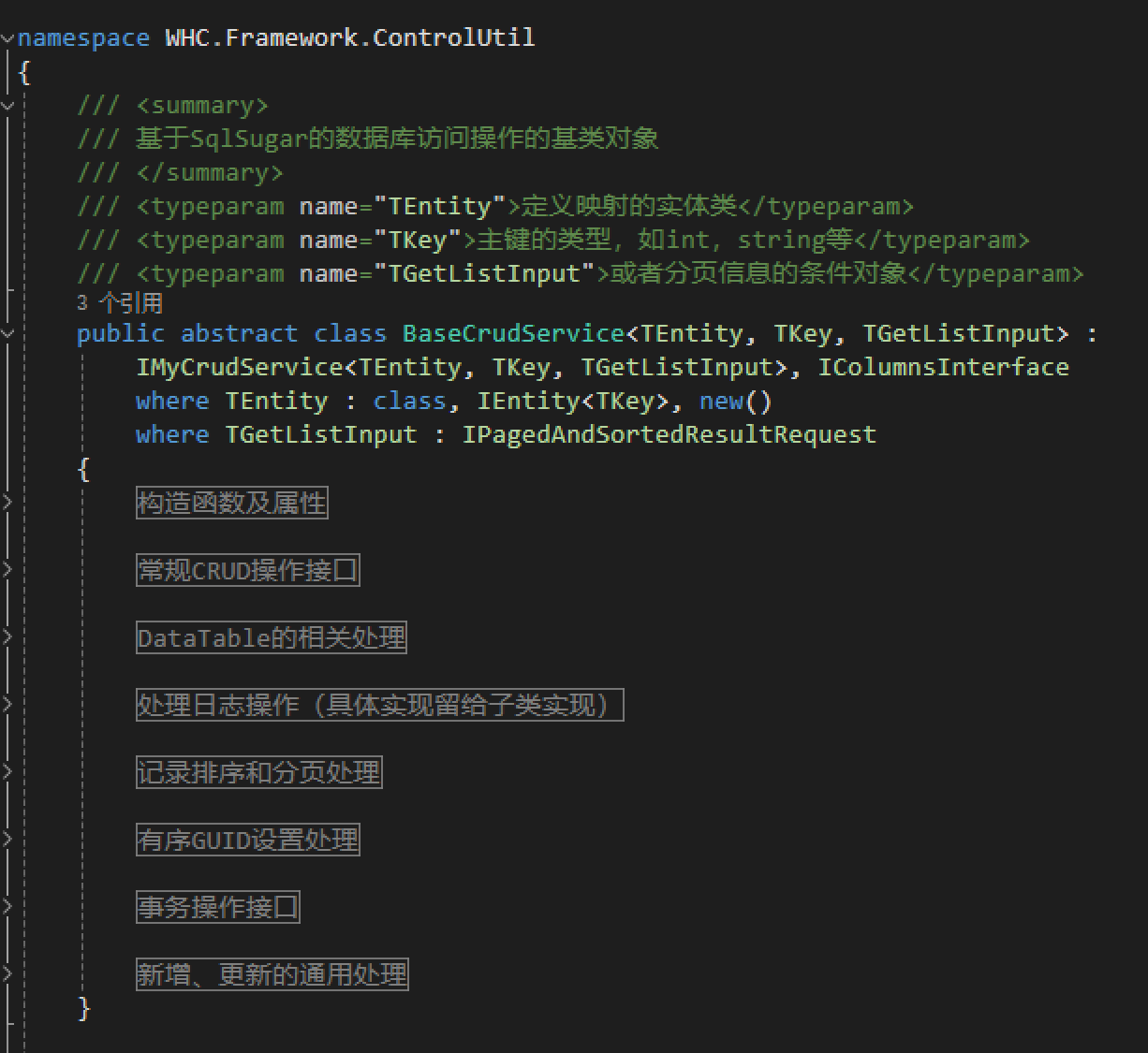
参照上面的实现方式,我们来看看Python中使用泛型的处理封装类的代码。
这样,我们就可以通过泛型定义不同的类型,以及相关的处理类的信息。
该基类函数中,异步定义get_all的返回所有的数据接口如下所示。
而对应获得单个对象的操作函数,如下所示。
而创建对象的操作函数,如下所示。
这个异步函数 create 旨在通过 SQLAlchemy 在数据库中创建一个对象,同时允许通过 kwargs 参数动态扩展创建对象时的字段。
-
async def: 表明这是一个异步函数,可以与await一起使用。 -
self: 这是一个类的方法,因此self引用类的实例。 -
obj_in: DtoType:obj_in是一个数据传输对象(DTO),它包含了需要插入到数据库中的数据。DtoType是一个泛型类型,用于表示 DTO 对象。 -
db: AsyncSession:db是一个 SQLAlchemy 的异步会话(AsyncSession),用于与数据库进行交互。 -
**kwargs: 接受任意数量的关键字参数,允许在对象创建时动态传入额外的字段。 -
obj_in.model_dump(): 假设obj_in是一个 Pydantic 模型或类似结构,它可以通过model_dump()方法转换为字典格式,用于创建 SQLAlchemy 模型实例。 -
self.model(**obj_in.model_dump(), **kwargs): 使用obj_in中的字段以及通过kwargs传入的扩展字段来实例化 SQLAlchemy 模型对象。如果kwargs非空,它们会被解包并作为额外的字段传入模型构造函数。 -
db.add(instance): 将新创建的对象添加到当前的数据库会话中。 -
await db.commit(): 提交事务,将新对象保存到数据库。 -
SQLAlchemyError: 捕获所有 SQLAlchemy 相关的错误。 -
await db.rollback(): 在发生异常时,回滚事务,以防止不完整或错误的数据被提交。
通过上面的封装,我们可以测试调用的处理例子
同步和异步处理的差异:
- 同步操作 适用于传统的阻塞式应用场景,比如命令行工具或简单的脚本。
- 异步操作 更适合异步框架如
FastAPI,可以提高高并发场景下的性能。
通过封装数据库操作,可以让代码更具复用性和可维护性,支持不同类型的操作场景。















 1264
1264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









