







【导语】:最近在“复现”一篇论文的结果。在实现的过程中,使用了Tensorflow+Keras和PyTorch分别构建模型,本文不做主观的评价,仅分别展示其代码和网络结构。
论文链接:https://ieeexplore.ieee.org/document/9079219
论文中根据具体需求构建了两个网络:Magnitude Network 和 Phase Network。本文分别以这两个网络为例展示使用不同框架构建的模型。
1、 Magnitude Network 结构图:
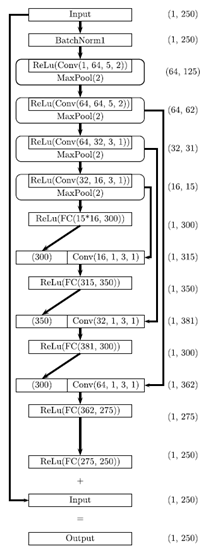
(1)Tensorflow+Keras实现:
def Magnitude_model(input_shape):
inputs = keras.layers.Input(shape=input_shape, name="input")
x = layers.BatchNormalization()(inputs)
x = layers.Conv1D(filters=64, kernel_size=5, padding="same", strides=2, activation="relu")(x)
x = layers.MaxPool1D(pool_size=2, padding="same")(x)
x = layers.Conv1D(filters=64, kernel_size=5, padding="same", strides=2, activation="relu")(x)
x = layers.MaxPool1D(pool_size=2, padding="same")(x)
b1 = x
x = layers.Conv1D(filters=32, kernel_size=3, padding="same", strides=1, activation="relu")(x)
x = layers.MaxPool1D(pool_size=2, padding="same")(x)
b2 = x
x = layers.Conv1D(filters=16, kernel_size=3, padding="same", strides=1, activation="relu")(x)
x = layers.MaxPool1D(pool_size=2, padding="same")(x)
b3 = x
x = layers.Dense(300, input_shape=(16, 15))(x)
x1 = layers.Conv1D(filters=15, kernel_size=3, padding="same", strides=1, activation="relu")(b3)
# x1 = layers.MaxPool1D(pool_size=2)(x)
concatted = layers.Concatenate()([x, x1]) # (1,315)
x = layers.Dense(350, activation="relu", input_shape=(1, 315))(concatted)
x2 = layers.Conv1D(filters=31, kernel_size=3, padding="same", strides=1, activation="relu")(b2)
concatted2 = layers.Concatenate()([x, x2]) # (1,381)
x = layers.Dense(300, activation="relu", input_shape=(1, 381))(concatted2) # (1,300)
x3 = layers.Conv1D(filters=62, kernel_size=3, padding="same", strides=1, activation="relu")(b1)
concatted3 = layers.Concatenate()([x, x3]) # (1,362)
x = layers.Dense(275, activation="relu", input_shape=(1, 362))(concatted3) # (1,275)
x = layers.Dense(250, activation="relu", input_shape=(1, 275))(x) # (1,250)
output = layers.Add()([x, inputs])
return keras.models.Model(inputs=inputs, outputs=output)输出网络结构:
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input (InputLayer) [(None, 1, 250)] 0
__________________________________________________________________________________________________
batch_normalization (BatchNorma (None, 1, 250) 1000 input[0][0]
__________________________________________________________________________________________________
conv1d (Conv1D) (None, 1, 64) 80064 batch_normalization[0][0]
__________________________________________________________________________________________________
max_pooling1d (MaxPooling1D) (None, 1, 64) 0 conv1d[0][0]
__________________________________________________________________________________________________
conv1d_1 (Conv1D) (None, 1, 64) 20544 max_pooling1d[0][0]
__________________________________________________________________________________________________
max_pooling1d_1 (MaxPooling1D) (None, 1, 64) 0 conv1d_1[0][0]
__________________________________________________________________________________________________
conv1d_2 (Conv1D) (None, 1, 32) 6176 max_pooling1d_1[0][0]
__________________________________________________________________________________________________
max_pooling1d_2 (MaxPooling1D) (None, 1, 32) 0 conv1d_2[0][0]
__________________________________________________________________________________________________
conv1d_3 (Conv1D) (None, 1, 16) 1552 max_pooling1d_2[0][0]
__________________________________________________________________________________________________
max_pooling1d_3 (MaxPooling1D) (None, 1, 16) 0 conv1d_3[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 1, 300) 5100 max_pooling1d_3[0][0]
__________________________________________________________________________________________________
conv1d_4 (Conv1D) (None, 1, 15) 735 max_pooling1d_3[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 1, 315) 0 dense[0][0]
conv1d_4[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 1, 350) 110600 concatenate[0][0]
__________________________________________________________________________________________________
conv1d_5 (Conv1D) (None, 1, 31) 3007 max_pooling1d_2[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 1, 381) 0 dense_1[0][0]
conv1d_5[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 1, 300) 114600 concatenate_1[0][0]
__________________________________________________________________________________________________
conv1d_6 (Conv1D) (None, 1, 62) 11966 max_pooling1d_1[0][0]
__________________________________________________________________________________________________
concatenate_2 (Concatenate) (None, 1, 362) 0 dense_2[0][0]
conv1d_6[0][0]
__________________________________________________________________________________________________
dense_3 (Dense) (None, 1, 275) 99825 concatenate_2[0][0]
__________________________________________________________________________________________________
dense_4 (Dense) (None, 1, 250) 69000 dense_3[0][0]
__________________________________________________________________________________________________
add (Add) (None, 1, 250) 0 dense_4[0][0]
input[0][0]
==================================================================================================
Total params: 524,169
Trainable params: 523,669
Non-trainable params: 500
__________________________________________________________________________________________________
Train on 2571 samples, validate on 733 samples(2)PyTorch实现:
class Magnitude(nn.Module):
def __init__(self, **kwargs):
super(Magnitude, self).__init__(**kwargs)
self.bn = nn.BatchNorm1d(1)
self.conv1 = nn.Conv1d(1, 64, 5, padding=2) # 1代表输入通道,64代表输出通道,5代表卷积核大小,2代表padding size
self.conv2 = nn.Conv1d(64, 64, 5, padding=2)
self.conv3 = nn.Conv1d(64, 32, 3, padding=1)
self.conv4 = nn.Conv1d(32, 16, 3, padding=1)
self.conv5 = nn.Conv1d(16, 1, 3, padding=1)
self.conv6 = nn.Conv1d(32, 1, 3, padding=1)
self.conv7 = nn.Conv1d(64, 1, 3, padding=1)
self.fc1 = nn.Linear(240, 300)
self.fc2 = nn.Linear(315, 350)
self.fc3 = nn.Linear(381, 300)
self.fc4 = nn.Linear(362, 275)
self.fc5 = nn.Linear(275, 250)
self.relu = nn.ReLU()
self.pool = nn.MaxPool1d(2)
def forward(self, x):
# print('in forward, 传入参数类型是:{} 值为: {}'.format(type(x), x))
self.x = self.bn(x)
self.x = self.relu(self.conv1(self.x))
self.x = self.pool(self.x)
self.x = self.relu(self.conv2(self.x))
self.x = self.pool(self.x)
self.t1 = self.x
self.x = self.relu(self.conv3(self.x))
self.x = self.pool(self.x)
self.t2 = self.x
self.x = self.relu(self.conv4(self.x))
self.x = self.pool(self.x)
self.t3 = self.x
self.x = self.x.view(self.x.shape[0], 1, -1) # shape 获取Tensor的形状 view 改变Tensor的形状
self.x = self.relu(self.fc1(self.x))
self.t3 = self.conv5(self.t3)
self.x = torch.cat((self.x, self.t3), -1) # cat: concatnate拼接在一起
self.x = self.relu(self.fc2(self.x))
#
self.t2 = self.conv6(self.t2)
self.x = torch.cat((self.x, self.t2), -1)
# print(self.x.shape)
self.x = self.relu(self.fc3(self.x))
#
self.t1 = self.conv7(self.t1)
self.x = torch.cat((self.x, self.t1), -1)
self.x = self.relu(self.fc4(self.x))
self.x = self.relu(self.fc5(self.x))
y = self.x + x
return y输出网络结构图:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
BatchNorm1d-1 [-1, 1, 250] 2
Conv1d-2 [-1, 64, 250] 384
ReLU-3 [-1, 64, 250] 0
MaxPool1d-4 [-1, 64, 125] 0
Conv1d-5 [-1, 64, 125] 20,544
ReLU-6 [-1, 64, 125] 0
MaxPool1d-7 [-1, 64, 62] 0
Conv1d-8 [-1, 32, 62] 6,176
ReLU-9 [-1, 32, 62] 0
MaxPool1d-10 [-1, 32, 31] 0
Conv1d-11 [-1, 16, 31] 1,552
ReLU-12 [-1, 16, 31] 0
MaxPool1d-13 [-1, 16, 15] 0
Linear-14 [-1, 1, 300] 72,300
ReLU-15 [-1, 1, 300] 0
Conv1d-16 [-1, 1, 15] 49
Linear-17 [-1, 1, 350] 110,600
ReLU-18 [-1, 1, 350] 0
Conv1d-19 [-1, 1, 31] 97
Linear-20 [-1, 1, 300] 114,600
ReLU-21 [-1, 1, 300] 0
Conv1d-22 [-1, 1, 62] 193
Linear-23 [-1, 1, 275] 99,825
ReLU-24 [-1, 1, 275] 0
Linear-25 [-1, 1, 250] 69,000
ReLU-26 [-1, 1, 250] 0
================================================================
Total params: 495,322
Trainable params: 495,322
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.53
Params size (MB): 1.89
Estimated Total Size (MB): 2.42
----------------------------------------------------------------
Process finished with exit code 0
2、 Phase Network 结构图
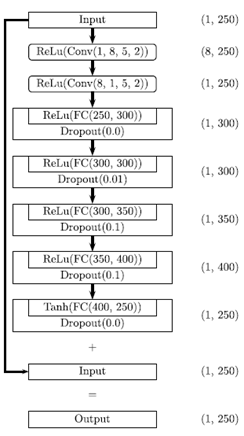
(1)Tensorflow+Keras实现:
def Phase_model(input_shape):
inputs = keras.layers.Input(shape=input_shape, name="input")
x = layers.Conv1D(filters=8, kernel_size=5, padding="same", strides=2, activation="relu")(inputs)
x = layers.Conv1D(filters=1, kernel_size=5, padding="same", strides=2, activation="relu")(x)
x = layers.Dense(300, activation='relu', input_shape=(1, 250))(x) # (1, 300)
x = layers.Dropout(0.0)(x)
x = layers.Dense(300, activation='relu', input_shape=(1, 300))(x) # (1, 300)
x = layers.Dropout(0.01)(x)
x = layers.Dense(350, activation='relu', input_shape=(1, 300))(x) # (1, 350)
x = layers.Dropout(0.1)(x)
x = layers.Dense(400, activation='relu', input_shape=(1, 350))(x) # (1, 400)
x = layers.Dropout(0.1)(x)
x = layers.Dense(250, activation='tanh', input_shape=(1, 400))(x) # (1, 250)
x = layers.Dropout(0.0)(x)
output = layers.Add()([x, inputs])
return keras.models.Model(inputs=inputs, outputs=output)输出网络结构:
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input (InputLayer) [(None, 1, 250)] 0
__________________________________________________________________________________________________
conv1d (Conv1D) (None, 1, 8) 10008 input[0][0]
__________________________________________________________________________________________________
conv1d_1 (Conv1D) (None, 1, 1) 41 conv1d[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 1, 300) 600 conv1d_1[0][0]
__________________________________________________________________________________________________
dropout (Dropout) (None, 1, 300) 0 dense[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 1, 300) 90300 dropout[0][0]
__________________________________________________________________________________________________
dropout_1 (Dropout) (None, 1, 300) 0 dense_1[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 1, 350) 105350 dropout_1[0][0]
__________________________________________________________________________________________________
dropout_2 (Dropout) (None, 1, 350) 0 dense_2[0][0]
__________________________________________________________________________________________________
dense_3 (Dense) (None, 1, 400) 140400 dropout_2[0][0]
__________________________________________________________________________________________________
dropout_3 (Dropout) (None, 1, 400) 0 dense_3[0][0]
__________________________________________________________________________________________________
dense_4 (Dense) (None, 1, 250) 100250 dropout_3[0][0]
__________________________________________________________________________________________________
dropout_4 (Dropout) (None, 1, 250) 0 dense_4[0][0]
__________________________________________________________________________________________________
add (Add) (None, 1, 250) 0 dropout_4[0][0]
input[0][0]
==================================================================================================
Total params: 446,949
Trainable params: 446,949
Non-trainable params: 0
__________________________________________________________________________________________________
Train on 2571 samples, validate on 733 samples(2)PyTorch实现:
class Phase(nn.Module):
def __init__(self):
super().__init__()
self.relu = nn.ReLU()
self.tanh = nn.Tanh()
self.conv1 = nn.Conv1d(1, 8, 5, padding=2) # 1代表输入通道,8代表输出通道,5代表卷积核大小,2代表padding size
self.conv2 = nn.Conv1d(8, 1, 5, padding=2)
self.fc1 = nn.Linear(250, 300)
self.dp1 = nn.Dropout(0.0)
self.fc2 = nn.Linear(300, 300)
self.dp2 = nn.Dropout(0.01)
self.fc3 = nn.Linear(300, 350)
self.dp3 = nn.Dropout(0.1)
self.fc4 = nn.Linear(350, 400)
self.dp4 = nn.Dropout(0.1)
self.fc5 = nn.Linear(400, 250)
self.dp5 = nn.Dropout(0.0)
def forward(self, in_c):
self.x = self.relu(self.conv1(in_c))
self.x = self.relu(self.conv2(self.x))
self.x = self.dp1(self.relu(self.fc1(self.x)))
self.x = self.dp2(self.relu(self.fc2(self.x)))
self.x = self.dp3(self.relu(self.fc3(self.x)))
self.x = self.dp4(self.relu(self.fc4(self.x)))
self.x = self.dp5(self.tanh(self.fc5(self.x)))
y = self.x + in_c
return y
输出网络结构:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv1d-1 [-1, 8, 250] 48
ReLU-2 [-1, 8, 250] 0
Conv1d-3 [-1, 1, 250] 41
ReLU-4 [-1, 1, 250] 0
Linear-5 [-1, 1, 300] 75,300
ReLU-6 [-1, 1, 300] 0
Dropout-7 [-1, 1, 300] 0
Linear-8 [-1, 1, 300] 90,300
ReLU-9 [-1, 1, 300] 0
Dropout-10 [-1, 1, 300] 0
Linear-11 [-1, 1, 350] 105,350
ReLU-12 [-1, 1, 350] 0
Dropout-13 [-1, 1, 350] 0
Linear-14 [-1, 1, 400] 140,400
ReLU-15 [-1, 1, 400] 0
Dropout-16 [-1, 1, 400] 0
Linear-17 [-1, 1, 250] 100,250
Tanh-18 [-1, 1, 250] 0
Dropout-19 [-1, 1, 250] 0
================================================================
Total params: 511,689
Trainable params: 511,689
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.07
Params size (MB): 1.95
Estimated Total Size (MB): 2.02
----------------------------------------------------------------
Process finished with exit code 0
以上只是笔者在深度学习中的第一次尝试,如果以上代码有任何问题,或者存在任何错误,欢迎指出,也很希望和大家一起讨论。















 1264
1264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









