






二叉排序树,也叫二叉查找树,这是一种基本的二叉树结构。
概述
二叉排序树,是指一种二叉树,这是一种树形的数据结构,这种数据结构中,存储数据的基本单位叫做节点,对于二叉树,一个节点可以链接到最多两个其他节点,就像树的两个树杈,所以叫做二叉树。
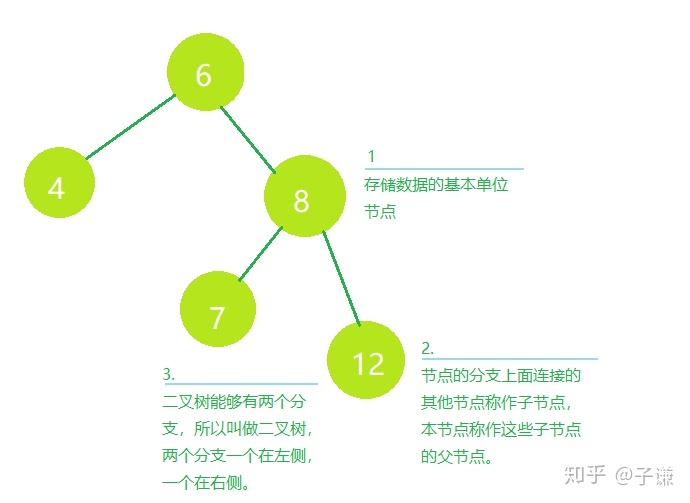
树的第一个节点,所有分支顶部的那个,就是根节点,而树的下方,没有左右节点的节点,被称作叶子节点。
我们说,如果一个二叉树符合如下规则,他就可以被称为二叉排序树:
- 二叉树某节点的左侧所有节点按照某一标准或某种形式“小于”此节点和此节点右侧节点
- 二叉树某节点的右侧所有节点按照某一种标准或形式“大于”此节点和此节点的左侧节点
- 二叉树所有的节点都符合以上规则。
这样的二叉树的特点:
通过中序遍历,可以得到一个有序的节点序列。
遍历是指从头到尾依次访问每一个节点,而树的遍历,有先序遍历,中序遍历,后序遍历三种,这三种遍历方式,也叫做深度优先遍历。
为什么叫深度优先遍历呢,就是因为这三种做法都会从树的根节点出发,依次走向叶子节点,除了这三种之外,还有直接按照树的层次进行遍历的做法,叫做层序遍历,也叫做广度优先遍历。
先序遍历的做法是这样的:
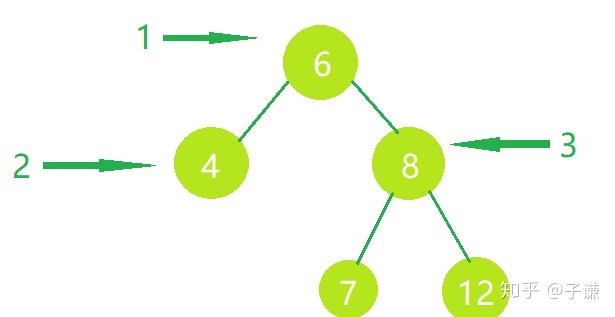
首先访问父节点,然后访问左侧节点,然后访问右侧节点,就按照这个规律经过整个树。
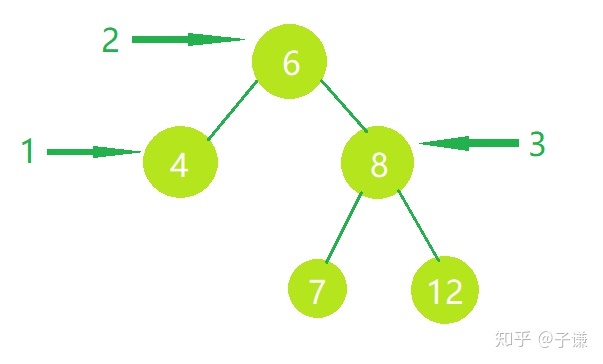
中序呢,其实就是先去左节点,然后是父节点,然后是右节点,按照这样的顺序依次走过整个树,相比先序遍历而言,第一个访问的不是父节点而是左侧节点,然后才会访问父节点。
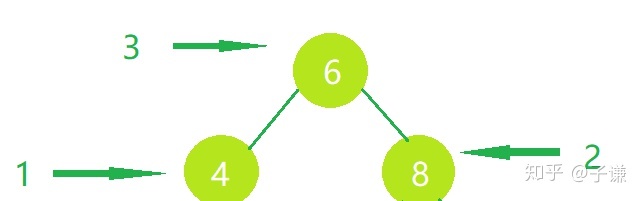
后续遍历更好说,先去左侧节点,然后去右侧节点,最后访问父节点,这就是后续遍历。
通过二叉排序树实现Java的Map接口
算是一个小练习,map里面的TreeMap就是红黑树实现的。
首先定义节点:
public class BinaryTreeNode<K,V> implements Map.Entry<K,V> {
/**
* 指向父节点,根节点这里为空
*/
private BinaryTreeNode<K,V> parent;
/**
* 左节点(左子树)
*/
private BinaryTreeNode<K,V> left;
/**
* 右节点(右子树)
*/
private BinaryTreeNode<K,V> right;
/**
* 哈希冲突链表
*/
private BinaryTreeNode<K,V> conflict;
/**
* 如果当前是冲突表中的节点,这个是此节点在
* 链表的父节点
*/
private BinaryTreeNode<K,V> conflictParent;
/**
* 树高
*/
private int height;
/**
* 键
*/
private K key;
/**
* 值
*/
private V value;
public BinaryTreeNode(K key, V val) {
this.key = key;
this.value = val;
}
/**
* 添加冲突节点。
*
* 通过链表法处理Hash冲突。
* @param node 与本节点发生Hash冲突的节点
*/
public void putConflict(BinaryTreeNode<K,V> node) {
BinaryTreeNode<K,V> conflict = this;
if (conflict.conflict != null) {
conflict = conflict.conflict;
}
conflict.conflict = node;
node.setParent(this.parent);
node.conflictParent = conflict;
}
/**
* 从冲突表移除节点
* @param key key
* @return 被移除的节点
*/
public BinaryTreeNode<K,V> removeConflict(K key) {
BinaryTreeNode<K,V> current = this;
while (current.conflict != null) {
if (current.conflict.key.equals(key)) {
current.conflict = current.conflict.conflict;
return current.conflict;
}
current = current.conflict;
}
return null;
}
/**
* 从冲突链表获取节点
* @param key 键
* @return 冲突链表里面的节点
*/
public BinaryTreeNode<K,V> getFromConflict(K key) {
BinaryTreeNode<K,V> current = this;
while (current.conflict != null) {
if (current.conflict.key.equals(key)) {
return current.conflict;
}
current = current.conflict;
}
return null;
}
public void setRight(BinaryTreeNode<K, V> right) {
this.right = right;
if (right != null) {
this.right.setParent(this);
}
}
public void setLeft(BinaryTreeNode<K, V> left) {
this.left = left;
if (left != null) {
this.left.setParent(this);
}
}
public void unLink() {
this.left = null;
this.right = null;
this.setParent(null);
}
// ---- 省略普通Getter和Setter -----
}这样就有了一个Tree节点了,接下来开始定义Tree的各类方法,
首先是添加:
实现的方法十分简单,参照添加的方法,实现查找也并不困难,查找的实现就不列出了。
/**
* 插入节点
* @param key 键
* @param val 值
* @return 插入的节点
*/
protected BinaryTreeNode<K,V> putEntry(K key, V val) {
BinaryTreeNode<K,V> target = new BinaryTreeNode<>(key,val);
if (root == null) {
// 没有根节点的时候,直接放入根节点
root = target;
this.size ++;
return target;
}
BinaryTreeNode<K,V> node = this.root;
while (node != null) {
int comp = compare(key,node.getKey());
if (comp > 0) {
// 大于上个节点,应当去右侧
if (node.getRight() != null) {
// 右侧有节点,更新当前节点进行下一次判断
node = node.getRight();
continue;
}
// 没有节点,直接放到右侧
node.setRight(target);
this.size ++;
return target;
} else if (comp == 0) {
// 节点相等,两种可能,一是key完全一致,二是hash出现了冲突
if (node.getKey().equals(key)) {
// 完全一致,替换value
node.setValue(val);
this.size ++;
return target;
} else {
// 出现冲突,加入冲突链表
node.putConflict(target);
this.size ++;
return target;
}
} else {
// 小于上个节点,应该向左
if (node.getLeft() != null) {
// 左边有节点,更新当前节点进行下一次判断
node = node.getLeft();
continue;
}
// 没有节点,放入左侧。
node.setLeft(target);
this.size ++;
return target;
}
}
return null;
}然后是查找后继节点,或者前驱节点也行,因为删除需要这种,下面是查找后继节点的实现方法:
/**
* 获取中序遍历的后继节点
*
* @param node 节点(参照节点)
* @return 节点的后继节点
*/
protected BinaryTreeNode<K,V> nextNode(BinaryTreeNode<K,V> node) {
// 存在hash冲突的时候,返回冲突表的节点,冲突表节点和参照节点相等。
if (node.getConflict() != null) {
// 返回冲突表下一个节点
return node.getConflict();
}
// 回溯到冲突表头
while (node.getConflictParent() != null) {
node = node.getConflictParent();
}
if (node.getRight() != null) {
// 存在右子树,右子树比节点大,因此在右子树找
BinaryTreeNode<K,V> right = node.getRight();
while (right.getLeft() != null) {
// 右子树如果有左子树,那后继节点应该在最左侧的左子树上
// 那个位置的节点必然比参照节点大,而且在所有比参照节点大的
// 节点中最小。
right = right.getLeft();
}
return right;
} else {
// 没有右子树,那么检查参照节点与其父节点的关系
BinaryTreeNode<K,V> parent = node.getParent();
if (parent.getLeft() == node) {
// 参照节点在左侧,按照中序遍历的规则,
// 下一个就是父节点。
return parent;
}
BinaryTreeNode<K,V> target = node;
while (parent.getRight() == target) {
// 向节点的上层查找,如果上层依然在他父节点的右侧,
// 就继续向上查找
target = target.getParent();
parent = target.getParent();
if (parent == null) {
// 到达了顶部,没有找到后继
// 这样做是因为,后继必然大于参照节点。
return null;
}
}
// target在其父节点的左侧,则父节点为后继
return parent;
}
}实现这个时候,删除节点就好说了
/**
* 删除节点
* @param key 键
* @return 删除的节点
*/
protected BinaryTreeNode<K,V> removeEntry(K key) {
BinaryTreeNode<K,V> node = getEntry(key);
if (node.getConflictParent() != null) {
BinaryTreeNode<K,V> parent = node.getConflictParent();
// node位于冲突表,直接删除即可
BinaryTreeNode<K,V> removed = parent.removeConflict(key);
if(removed != null) {
this.size--;
return removed;
}
return null;
}
if (node.getLeft() == null || node.getRight() == null) {
BinaryTreeNode<K,V> child = node.getLeft() == null ? node.getRight() : node.getLeft();
BinaryTreeNode<K,V> parent = node.getParent();
if (parent == null) {
// 如果待删除的是根节点
this.root = child;
} else if (parent.getLeft() == node) {
parent.setLeft(child);
} else {
parent.setRight(child);
}
this.size--;
return node;
}
BinaryTreeNode<K,V> parent = node.getParent();
BinaryTreeNode<K,V> next = this.nextNode(node);
BinaryTreeNode<K,V> nextParent = next.getParent();
// 挂载后继节点的右侧节点到他的父级节点
if (nextParent.getLeft() == next) {
nextParent.setLeft(next.getRight());
} else {
nextParent.setRight(next.getRight());
}
next.setRight(node.getRight());
next.setLeft(node.getLeft());
if (parent == null) {
this.root = next;
} else if (parent.getLeft() == node) {
parent.setLeft(next);
} else {
parent.setRight(next);
}
this.size --;
return node;
}那么上面就是几个关键的操作了,剩余的部分,只需要完善的Map的API,那么就可以实现一个完整的Map。
通过重写put和get,entryset和values,iterator等,做完剩余的部分很简单,不需要多记录其他的了。
当然,二叉排序树是个很基础的树,在某些情况下会变成链表那种情况,所以为了防止这种状态,需要通过一些方法对它进行平衡,防止变成一个线性的链表,而具备这种平衡能力的树,就是平衡二叉排序树(平衡二叉查找树)。















 3087
3087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









