




简介:Java分页思想是处理大数据集时提高性能的关键技术。本文档详尽介绍了分页的基本原理、数据库分页实现方法、Java代码层面的分页策略,以及国际化和会话管理在分页中的应用。文档中包含代码示例、数据库设计图解、分页的分工图解、session监听应用图解、以及分页相关文档和课程资料,旨在帮助开发者全面理解并实践Java分页技术。
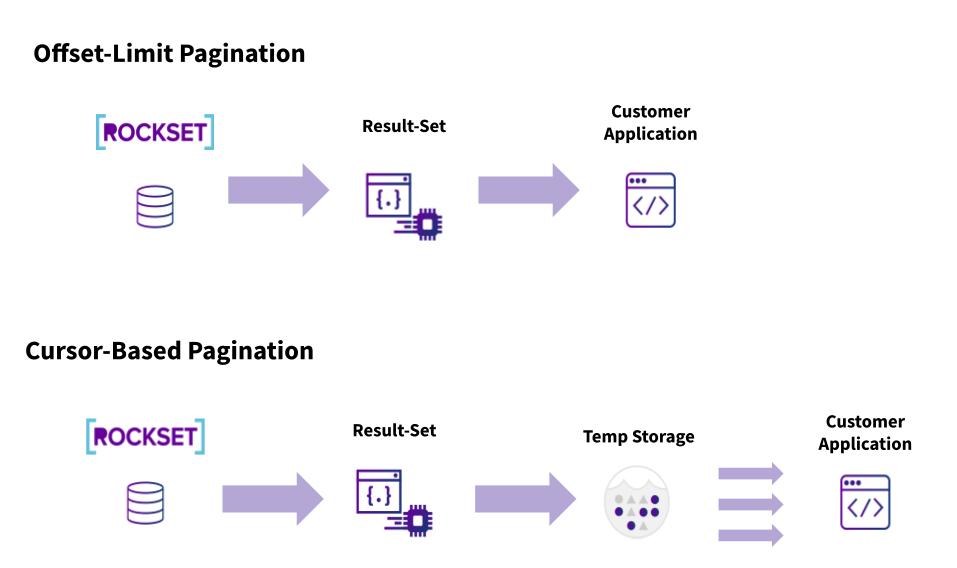
1. 分页的基本原理和数据库分页实现方法
1.1 分页的基本原理
分页,一种常见的数据展示方式,其核心在于将大量数据分散到多个页面上逐一展示,提高用户获取信息的效率和系统响应速度。它的基本原理是通过每次只加载用户当前查看页面所对应的数据,而非一次性加载全部数据。这种方式尤其适用于处理大规模数据集,减轻服务器端和客户端的压力。
1.2 数据库分页实现方法
在数据库层面实现分页,常用的查询语句是SQL中的 LIMIT 和 OFFSET 子句。以MySQL数据库为例, LIMIT 子句指定返回记录的数量,而 OFFSET 子句指定开始返回记录之前要跳过的记录数。例如,如果要获取第二页的数据(每页显示10条),查询语句将可能是:
SELECT * FROM table_name LIMIT 10 OFFSET 10;
这种方式的优点是简单易用,但当数据量非常大时,随着 OFFSET 值的增加,查询性能会逐渐下降。因此,在实际应用中需要根据具体情况进行优化,比如使用索引或结合其他数据库特性来提升分页查询的性能。接下来的章节中,我们将探讨通过不同技术和框架实现分页的具体方法,以及如何对这些方法进行优化。
2. JDBC分页、ORM框架分页和Spring Data JPA分页技术
2.1 JDBC分页技术
2.1.1 JDBC分页的原理
JDBC(Java Database Connectivity)分页是利用JDBC API提供的接口实现数据库查询结果的分页处理。JDBC分页主要依赖于SQL语句中的 LIMIT 和 OFFSET 子句。 LIMIT 子句用于指定返回查询结果的最大行数,而 OFFSET 子句用于指定返回结果的起始位置。
分页的基本逻辑是首先确定每页显示的记录数(即页面大小),然后通过计算出 OFFSET 值来确定当前页第一条记录的位置。例如,如果每页显示10条记录,那么第1页的 OFFSET 值是0(从第一条记录开始),第2页的 OFFSET 值是10(从第11条记录开始)。
JDBC分页操作通常分为两步:
1. 构造分页查询的SQL语句。
2. 执行SQL语句并从 ResultSet 中获取当前页的数据。
2.1.2 JDBC分页的实现步骤
以下是一个使用JDBC进行分页操作的示例代码块,包含执行逻辑说明和参数解释:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class JdbcPaginationExample {
private static final String URL = "jdbc:mysql://localhost:3306/mydatabase";
private static final String USER = "username";
private static final String PASSWORD = "password";
public static void main(String[] args) {
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
conn = DriverManager.getConnection(URL, USER, PASSWORD);
String sql = "SELECT * FROM table_name LIMIT ? OFFSET ?";
pstmt = conn.prepareStatement(sql);
pstmt.setInt(1, 10); // 每页显示的记录数
pstmt.setInt(2, 0); // 当前页的起始记录位置(第1页从0开始)
rs = pstmt.executeQuery();
while (rs.next()) {
// 处理结果集中的记录
System.out.println(rs.getString("column_name"));
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
if (rs != null) rs.close();
if (pstmt != null) pstmt.close();
if (conn != null) conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
在此代码中,我们首先建立了数据库连接,然后创建了一个带有 LIMIT 和 OFFSET 子句的SQL语句。 LIMIT 10 OFFSET 0 表示我们希望获取10条记录,从第一条记录开始获取。 pstmt.setInt(1, 10) 设置了每页的记录数,而 pstmt.setInt(2, 0) 设置了当前页的起始位置。最后,我们执行了查询并处理了结果集。
2.2 ORM框架分页技术
2.2.1 Hibernate分页技术
Hibernate是一个流行的ORM(Object-Relational Mapping)框架,它提供了丰富的API来实现分页。Hibernate分页可以通过 org.hibernate.Query 对象的 setFirstResult(int firstResult) 和 setMaxResults(int maxResults) 方法来实现。 setFirstResult 方法用于指定从哪一条记录开始获取结果,而 setMaxResults 方法用于指定获取记录的最大数量。
2.2.2 MyBatis分页技术
MyBatis是一个半自动的ORM框架,它允许开发者通过XML文件或注解来定义SQL语句。MyBatis的分页通常使用拦截器(Interceptor)来实现。开发者可以通过自定义拦截器,在SQL执行前动态地插入 LIMIT 和 OFFSET 子句。
2.3 Spring Data JPA分页技术
2.3.1 Spring Data JPA分页的原理
Spring Data JPA是建立在Spring和JPA(Java Persistence API)之上的数据访问层框架。它简化了数据访问层的代码,并且集成了Spring生态系统的强大功能。Spring Data JPA支持多种分页方法,包括使用 Page 和 Pageable 接口。
分页原理是通过 Pageable 接口的实现来传递分页的参数,比如当前页码和页面大小。然后在查询方法中将 Pageable 参数与查询结合起来,Spring Data JPA会自动将这些参数转换为合适的SQL语句。
2.3.2 Spring Data JPA分页的实现步骤
以下是一个使用Spring Data JPA进行分页操作的示例代码块,包含执行逻辑说明和参数解释:
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.jpa.repository.JpaRepository;
public interface ItemRepository extends JpaRepository<Item, Long> {
// 定义查询方法
}
@Service
public class ItemService {
@Autowired
private ItemRepository itemRepository;
public Page<Item> findPaginated(int pageNo, int pageSize) {
Pageable pageable = PageRequest.of(pageNo - 1, pageSize);
return this.itemRepository.findAll(pageable);
}
}
在这个服务类中,我们注入了 ItemRepository ,这是一个继承自 JpaRepository 的接口。 findPaginated 方法接受页码和页面大小作为参数,然后使用 PageRequest.of 方法构建一个 Pageable 对象。 PageRequest.of 方法的第一页页码通常为0,这是因为 PageRequest 是基于0开始计算的。
然后,我们调用 itemRepository.findAll(pageable) ,传入我们的 Pageable 对象。这样就会返回一个 Page<Item> 对象,其中包含了分页数据和分页信息,如总页数、当前页数据等。
表格和mermaid流程图
为了更详细地说明分页技术,我们可以创建一张表格来比较不同分页技术的特点,并通过一个流程图来展示Spring Data JPA分页的处理流程。
表格:分页技术比较
| 特点/技术 | JDBC分页 | Hibernate分页 | MyBatis分页 | Spring Data JPA分页 |
|---|---|---|---|---|
| 分页原理 | LIMIT/OFFSET | Query接口 | 拦截器 | Pageable接口 |
| 实现难易度 | 较复杂 | 中等 | 中等 | 简单 |
| 灵活性 | 较灵活 | 中等 | 较灵活 | 中等 |
| 性能 | 较低 | 中等 | 中等 | 较高 |
| 集成性 | 无 | 高 | 中等 | 高 |
mermaid 流程图:Spring Data JPA分页处理流程
graph LR
A[开始] --> B[创建Pageable对象]
B --> C[调用Repository方法]
C --> D{是否有更多数据?}
D -- 是 --> E[获取分页数据]
D -- 否 --> F[结束]
E --> G[返回Page对象]
G --> H[处理数据]
H --> F
在这个流程图中,我们展示了使用Spring Data JPA进行分页的处理流程。首先创建一个 Pageable 对象来指定分页参数,然后调用Repository方法。接着,根据查询结果判断是否有更多数据需要处理。如果有,则获取并处理分页数据,如果没有,则结束流程。最终,返回 Page 对象供调用者使用。
3. 分页的国际化实现和会话管理
3.1 分页的国际化实现
3.1.1 国际化的概念和重要性
国际化(Internationalization),通常被简称为 i18n,因为从单词 “internationalization” 中 “i” 和 “n” 之间有18个字母。国际化涉及使应用程序能够适应不同的语言和地区需求,而无需进行大规模的修改。这一过程不仅涉及翻译用户界面中的文本,还包含适配本地化的数据格式(如日期、时间和货币)、地区特定的规则以及用户交互方式等方面。
对于分页来说,国际化尤其重要,因为分页组件常常涉及到显示当前页面信息、总页数、分页控件以及页面导航等元素。国际化可以确保这些信息对于不同语言的用户都是友好和易于理解的。
3.1.2 分页国际化的实现方法
在Web应用程序中,实现分页国际化的一种常见方法是使用属性文件(properties)。每个属性文件包含了特定语言环境下的翻译字符串。例如,一个名为 messages_en.properties 的文件可能包含:
page.current=Current Page
page.of=of
而 messages_es.properties 文件可能包含:
page.current=Página actual
page.of=de
在Java代码中,可以利用 ResourceBundle 类来加载这些属性文件,并根据用户的语言环境显示相应的文本。下面是一个简单的代码示例:
ResourceBundle messages = ResourceBundle.getBundle("messages",Locale.getDefault());
String currentPage = messages.getString("page.current");
String pageOf = messages.getString("page.of");
在Spring框架中,可以使用 MessageSource 接口和 @ExceptionHandler 注解来实现国际化异常处理和消息管理。
对于前后端分离的应用程序,通常在前端框架中(如React或Vue.js)使用国际化库(如 react-intl 或 vue-i18n )来处理多语言支持。
3.2 会话管理在分页中的应用
3.2.1 会话管理的概念和重要性
会话管理(Session Management)是指在用户与应用程序交互过程中,持续跟踪用户状态的过程。这通常涉及到识别用户、存储用户特定信息、以及提供一种机制让用户在不同的请求之间保持状态一致。
在Web应用程序中,会话管理对于保持用户的登录状态、保存用户的个人偏好设置以及跟踪用户的浏览行为等方面至关重要。特别是在需要分页的列表视图中,用户的滚动位置、当前的排序状态、筛选条件等信息需要被保存,以便用户可以回到相同的列表视图位置。
3.2.2 会话管理在分页中的应用实例
在分页功能中,会话管理可以用来保存用户在一系列页面中的特定状态,例如:
- 用户在执行大量数据查询时所选择的排序和筛选参数。
- 用户在浏览分页列表时所处的页面位置。
- 用户对特定页面进行的个性化设置。
举一个简单的例子,当用户在浏览一个商品列表时,他们可能按照价格排序,并且浏览了20多个分页。如果用户暂时离开页面,会话管理可以帮助应用程序记住用户的当前排序方式、筛选条件以及最后访问的页码。当用户返回时,不需要重新进行筛选或排序,可以直接查看之前查看的页面。
在Java中, HttpSession 对象经常被用来管理会话。下面是一个简单的代码示例,演示了如何在用户会话中存储和检索分页状态:
HttpSession session = request.getSession(true); // 创建一个会话或获取现有的会话
session.setAttribute("pageSize", 10); // 设置每页显示10个条目
session.setAttribute("currentPage", 1); // 设置当前页码为1
// ... 在后续请求中
int pageSize = (Integer) session.getAttribute("pageSize");
int currentPage = (Integer) session.getAttribute("currentPage");
会话数据的存储方式可以是内存中的会话存储、数据库或使用分布式缓存系统,如Redis。选择哪种方式取决于应用的具体需求,比如是否需要支持跨多个服务器的会话共享。
在实际应用中,为了安全起见,会话数据不应该被直接存储敏感信息,而是存储一个唯一的会话标识,实际的数据存储在数据库或缓存系统中,并通过这个标识关联起来。
通过结合使用会话管理与分页功能,可以极大地提升用户的使用体验,使用户能够无缝地与应用程序交互,即使在多个页面之间或在不同时间点进行操作时也能保持一致性。
4. 分页的设计文档、课程资料和实战应用案例
在探讨分页技术时,设计文档、课程资料和实战应用案例都是不可或缺的部分。本章节将着重讨论这些方面的深入内容。
4.1 分页的设计文档
设计文档是分页系统开发的蓝图,它详细描述了分页实现的每个环节,对于整个项目的成功至关重要。
4.1.1 设计文档的编写方法
设计文档应当从系统需求开始,详细说明分页功能的业务逻辑、技术选型、接口定义、性能要求以及安全策略等关键信息。编写设计文档的过程通常包括以下几个步骤:
- 需求分析 :收集用户需求,明确分页功能的目标和约束条件。
- 系统设计 :根据需求分析的结果,进行系统的高层次设计,包括技术架构选择、数据库设计、系统模块划分等。
- 接口定义 :详细定义前后端交互的API接口,包括参数、请求方法、返回值等。
- 性能规划 :设定性能指标,如响应时间、吞吐量等,并针对可能的瓶颈制定优化策略。
- 安全性设计 :考虑潜在的安全威胁,并制定相应的防护措施。
4.1.2 分页设计文档的实例分析
下面我们通过一个分页系统的设计文档实例进行分析。假设该系统是一个电商网站的商品列表展示页面。
# 分页系统设计文档
## 1. 引言
介绍背景、目标和主要功能。
## 2. 系统需求
详细描述分页功能需求,包括用户场景、业务逻辑等。
## 3. 技术架构
选择合适的技术栈,如Spring Boot、MyBatis等。
## 4. 接口定义
详细说明API的输入输出参数、请求方法等。
## 5. 数据库设计
展示数据库表结构设计,包括索引优化方案。
## 6. 安全性设计
列举安全策略,如输入验证、数据加密等。
## 7. 性能优化策略
介绍分页查询优化措施,如SQL优化、缓存策略等。
## 8. 维护与部署
说明系统的部署流程和维护策略。
4.2 分页的课程资料
课程资料为开发者提供了深入学习分页技术的途径,涵盖了理论知识到实践案例的全面内容。
4.2.1 课程资料的获取和整理
获取高质量的课程资料通常可以通过以下途径:
- 在线教育平台 :如Coursera、Udemy等,它们提供众多关于分页技术的课程。
- 技术社区 :如GitHub、Stack Overflow等,社区分享的教程、问答有助于理解分页的实际应用。
- 官方文档 :阅读官方文档,如Spring Data JPA的用户指南,能够获得权威的指导。
课程资料的整理需要:
- 主题分类 :按照分页技术的类型、数据库类别等进行分类。
- 难易程度 :按照初级、中级、高级整理,帮助开发者循序渐进学习。
- 实践案例 :搜集不同场景下的分页应用案例,以供参考。
4.2.2 分页课程资料的深度解读
深度解读课程资料,可以让开发者对分页有更全面的理解。这里我们以JPA分页课程为例:
# JPA分页技术课程资料深度解读
## 1. JPA分页基础
介绍JPA分页的API、实现原理和使用场景。
## 2. 高级查询技巧
深入讲解使用Specification实现复杂的查询和分页。
## 3. 性能优化实践
通过案例分析,讲解如何对JPA分页进行性能调优。
## 4. 安全分页实现
讨论实现安全分页的关键点和最佳实践。
## 5. 实战演练
结合真实案例,进行代码实战和问题排查演练。
4.3 分页的实战应用案例
实战应用案例是将理论知识和课程资料转化为实际操作的关键步骤,对于巩固学习成果具有重要作用。
4.3.1 分页实战应用案例的介绍
一个典型的分页实战案例可以是用户在电商网站上浏览商品列表,页面需要展示商品信息,并提供分页导航。
4.3.2 分页实战应用案例的详细解析
详细解析中,我们可以用伪代码、流程图和数据库交互示例来说明分页操作。
graph LR
A[用户请求页面] -->|请求参数| B[后端处理]
B --> C{判断分页参数}
C -->|有| D[执行分页查询]
C -->|无| E[返回错误信息]
D --> F[组装数据]
F --> G[返回分页数据]
伪代码示例:
@RestController
@RequestMapping("/products")
public class ProductController {
@Autowired
private ProductService productService;
// 分页查询商品
@GetMapping("/list")
public ResponseEntity<Page<Product>> list(
@RequestParam(name = "page", defaultValue = "0") int page,
@RequestParam(name = "size", defaultValue = "10") int size) {
Pageable pageable = PageRequest.of(page, size);
Page<Product> productPage = productService.findProducts(pageable);
return new ResponseEntity<>(productPage, HttpStatus.OK);
}
}
在实际代码中, PageRequest.of(page, size) 创建了一个分页请求对象, productService.findProducts(pageable) 则会根据分页信息查询数据库,并返回一个分页结果。
通过实战案例的详细解析,开发者可以更好地理解分页技术的应用,并在自己的项目中进行实践。
5. Java分页性能优化策略
随着互联网应用的不断扩展和用户量的日益增加,数据量的处理成为每一个应用的挑战,分页查询作为处理大量数据的一种手段,它的性能优化策略显得尤为重要。本章节将深入探讨Java分页性能优化的理论知识和实践操作,使开发者能够掌握分页查询的优化技巧,提升应用性能。
5.1 分页性能优化的理论知识
在讨论具体的优化策略之前,有必要先了解分页性能优化的基本原理。
5.1.1 分页性能优化的原理
分页性能优化的核心在于减少数据库的查询量和提高查询效率。这通常涉及到减少数据传输量、降低数据库的计算压力、利用缓存以及合理使用索引等策略。在大型应用中,分页查询往往不是单机执行,而是可能需要跨多个节点进行数据汇总和处理,这种场景下的性能优化显得更为复杂。
5.1.2 分页性能优化的方法
性能优化的方法众多,但万变不离其宗,主要是从以下几个方面进行:
- 数据库索引优化 :为经常用于分页查询的字段添加索引,可以极大提高查询效率。
- 查询语句优化 :优化SQL查询语句,减少不必要的数据传输,如避免使用SELECT *。
- 业务逻辑优化 :调整业务逻辑,提前过滤不需要的数据,减少查询时的数据量。
- 缓存机制 :合理使用缓存,对于不经常变动的数据可以使用缓存来提高访问速度。
- 分布式架构优化 :在分布式系统中,合理使用分布式数据库的分片和聚合查询技术。
- 资源利用 :优化硬件资源的使用,比如使用更快的磁盘、更大的内存等。
5.2 分页性能优化的实践操作
接下来将结合实际案例,讨论如何在Java项目中实施分页性能优化的策略。
5.2.1 分页性能优化的实践步骤
在实践中,分页性能优化可以遵循以下步骤:
- 性能分析 :使用数据库的性能分析工具,找出查询瓶颈所在。
- 索引优化 :根据性能分析的结果,对数据库表结构进行索引优化。
- SQL改写 :对涉及分页的查询语句进行优化,减少数据传输量。
- 业务逻辑调整 :修改业务逻辑,减少数据在应用层的处理量。
- 缓存策略 :根据查询数据的特性,设计合理的缓存策略。
- 测试验证 :在实施优化后,进行充分的测试验证优化效果。
- 持续监控 :优化后持续监控性能,根据反馈进行调整。
5.2.2 分页性能优化的实践案例
下面以一个常见的用户信息分页查询为案例,进行性能优化的详细解析。
假设我们有一个用户信息表,包含用户ID、姓名、邮箱、注册时间和最后登录时间等字段。在进行分页查询时,如果没有进行优化,可能会出现查询效率低下的问题。
步骤一:性能分析
使用数据库的查询分析工具,发现查询性能瓶颈在于全表扫描和大量的数据排序。因为数据库没有为排序字段创建索引,导致每次查询都需要对全表进行排序。
步骤二:索引优化
根据分析结果,为经常用于排序的“注册时间”字段添加索引。创建索引的SQL语句如下:
CREATE INDEX idx_user_registration ON user_info(registration_time);
步骤三:SQL改写
优化SQL查询语句,避免不必要的数据加载。例如,用户表中可能不需要加载所有字段,可以只加载需要的字段。
SELECT user_id, name, email FROM user_info WHERE ... ORDER BY registration_time LIMIT 10 OFFSET 0;
步骤四:业务逻辑调整
在应用层,如果用户权限足够,可以在分页查询前,先进行权限校验,减少数据库的压力。
步骤五:缓存策略
由于用户信息不会频繁变动,可以使用缓存来提高访问速度。可以使用Redis等NoSQL数据库来缓存用户信息,减少对关系型数据库的访问次数。
// 示例伪代码,使用Redis缓存用户信息
User user = redisCache.get("userId");
if (user == null) {
user = database.queryUserById("userId");
redisCache.set("userId", user);
}
步骤六:测试验证
在完成优化后,使用相同的查询条件进行测试,验证优化效果是否符合预期。
步骤七:持续监控
优化完成后,持续监控数据库性能指标,比如查询时间、CPU使用率等,确保优化效果的稳定性和可持续性。
通过这个实践案例,我们可以看到分页性能优化是一个需要从多个维度进行综合考虑的过程。通过逐步优化,能够显著提升应用的性能和用户体验。
6. 基于前端技术的分页实现
6.1 前端分页技术概述
随着Web应用的不断发展,前端技术也在日新月异地进步。在前端实现分页功能,不仅可以减少服务器的负载,还能为用户提供更流畅、更快速的浏览体验。现代前端框架和库,如React, Angular, Vue.js等,提供了许多插件和组件来帮助开发者轻松实现前端分页。
6.2 前端分页的实现原理
前端分页的原理本质上是通过JavaScript动态操作DOM来改变数据的展示。当用户进行翻页操作时,前端发送请求到后端,获取新的数据集,并更新页面内容,而无需重新加载整个页面。常见的前端分页技术包括:滚动加载、按钮点击翻页等。
6.3 前端分页技术的实现步骤
6.3.1 滚动加载(Infinite Scrolling)
滚动加载是一种用户体验较好的分页方式,用户滚动至页面底部时自动加载更多数据。实现步骤如下:
- 在页面底部预留一个加载提示区域。
- 监听窗口滚动事件,并判断是否滚动到页面底部。
- 当用户到达页面底部时,发送请求到后端获取新数据。
- 将返回的数据添加到当前数据集的末尾,并更新页面内容。
// 示例代码
window.addEventListener('scroll', function() {
if (window.innerHeight + window.scrollY >= document.body.offsetHeight) {
// 到达底部的逻辑处理,加载数据
fetchMoreData();
}
});
function fetchMoreData() {
// 发起请求获取新数据
// 更新页面逻辑...
}
6.3.2 按钮点击翻页
通过翻页按钮实现前后页的切换,这种方式适合于数据量较少且翻页次数不多的情况。实现步骤如下:
- 在页面上提供“上一页”和“下一页”按钮。
- 为按钮添加点击事件监听器。
- 当用户点击翻页按钮时,隐藏当前页的数据,显示下一页数据。
- 同时,根据当前页码更新按钮的可用状态。
// 示例代码
const pageButtons = document.querySelectorAll('.page-button');
pageButtons.forEach(button => {
button.addEventListener('click', function() {
const page = parseInt(this.dataset.page, 10);
switchPage(page);
});
});
function switchPage(pageNumber) {
// 显示/隐藏页面逻辑
// 更新按钮状态
// 发起请求获取指定页的数据
}
6.4 前端分页数据结构设计
在前端分页中,数据结构的设计十分关键。分页数据通常以数组形式存在,需要按页存储。针对前端框架的响应式特性,我们可以使用各种状态管理工具来优化数据管理,如Vuex, Redux, NgRx等。
6.5 前端分页性能优化
前端分页性能优化主要围绕减少数据的加载时间和提高用户操作的响应速度展开。以下是一些优化建议:
- 减少不必要的DOM操作,利用现代前端框架的虚拟DOM机制。
- 使用Web Workers来处理耗时的计算任务,以免阻塞UI线程。
- 实现局部更新,只重绘页面发生变化的部分。
- 适当时,使用缓存机制存储已经加载的数据,避免重复请求。
6.6 前端分页的调试与测试
分页功能的调试与测试是确保前端分页正确性的关键环节。这包括功能测试、性能测试和用户体验测试。
- 功能测试:确保所有分页操作均能正确响应,数据展示无误。
- 性能测试:评估加载数据时页面的响应速度和流畅度。
- 用户体验测试:从用户角度出发,测试翻页的直观性和易用性。
6.6.1 功能测试
功能测试可以通过编写自动化测试脚本来完成。例如,在Vue.js中,可以使用Vue Test Utils结合Jest来完成:
// 示例代码
import { mount } from '@vue/test-utils';
import PaginationComponent from '@/components/Pagination.vue';
describe('PaginationComponent', () => {
it('renders correctly and changes page on click', async () => {
const wrapper = mount(PaginationComponent);
await wrapper.find('.page-button.next').trigger('click');
// 验证数据是否正确变更等...
});
});
6.6.2 性能测试
性能测试可以使用浏览器自带的性能分析工具,例如Chrome的Performance标签页来完成:
- 开启记录功能,执行翻页操作。
- 分析记录,查看是否有不必要的重绘或回流操作。
- 根据分析结果,对性能进行调优。
6.6.3 用户体验测试
用户体验测试更倾向于主观评价,可以邀请实际用户来试用分页功能,或者进行A/B测试,比较不同分页设计的用户满意度。
6.7 前端分页的未来发展
随着前端技术的进一步发展,分页技术也会有更多创新。例如,利用Web Components构建可复用的分页组件,以及借助Server-Side Rendering技术优化初次加载性能等。
6.8 总结
本章节介绍了前端分页技术的实现原理、具体步骤、数据结构设计、性能优化以及调试与测试。通过综合应用这些技术,可以大幅提高Web应用的用户体验和性能表现。未来前端分页将继续朝着更高效、更智能、更人性化的方向发展。
7. 分页功能中的安全性和最佳实践
6.1 分页安全性的必要性
在Web应用中,分页是用户界面中常见的功能,允许用户浏览大量数据的不同部分。在设计和实现分页功能时,安全性是一个关键的考虑因素,尤其是当分页处理的不仅仅是展示数据而是涉及到敏感信息时。
例如,如果一个网站允许用户搜索个人信息,那么未经审查的分页查询可能会暴露出搜索结果外的其他数据。攻击者可能会利用这一点来获取那些本不应该对用户公开的数据。因此,开发者必须确保分页逻辑能够抵御各种安全威胁,如SQL注入、跨站脚本攻击(XSS)和跨站请求伪造(CSRF)等。
6.2 防止SQL注入
SQL注入是一种常见的攻击手段,攻击者通过在输入字段中插入恶意SQL代码,试图在数据库中执行未授权的命令。为了防止这种攻击,在实现分页功能时,建议使用参数化的查询而不是拼接SQL语句。
以Java为例,使用 PreparedStatement 可以有效地防止SQL注入:
String query = "SELECT * FROM users WHERE id > ? ORDER BY id LIMIT ? OFFSET ?";
try (PreparedStatement stmt = connection.prepareStatement(query)) {
stmt.setInt(1, lastId);
stmt.setInt(2, limit);
stmt.setInt(3, offset);
ResultSet rs = stmt.executeQuery();
// 处理结果集
}
在此代码示例中, PreparedStatement 对象通过使用占位符 ? 来避免SQL注入,并且将参数作为输入安全地绑定到SQL语句中。
6.3 跨站脚本攻击(XSS)防护
跨站脚本攻击(XSS)是指攻击者在页面中注入恶意脚本,当其他用户浏览这些页面时,脚本被执行,可能会导致用户信息泄露或页面内容被篡改。
在分页功能中,如果将用户的输入(如页码)直接嵌入到HTML中,那么未经处理的输入可能会导致XSS攻击。为了防止XSS,应当对所有输出进行HTML编码。例如,使用JavaScript库,如jQuery的 $.text() ,它能够自动对内容进行编码。
6.4 跨站请求伪造(CSRF)防护
跨站请求伪造(CSRF)是一种攻击者利用用户身份,伪造用户的请求来操作网站功能的攻击方式。
在分页中,如果分页链接被攻击者诱导用户点击,可能会导致用户在不知情的情况下执行了非法分页操作。为了防御CSRF攻击,开发者应确保所有的请求都包含一个验证令牌,这个令牌与用户的会话绑定,并且攻击者无法获得或预测。
例如,在Web应用中使用隐藏字段在每次请求中发送一个令牌:
<input type="hidden" name="csrfToken" value="token_value">
服务器端在处理请求时,要验证 csrfToken 字段的存在和有效性。
6.5 分页的最佳实践
为了构建安全且健壮的分页功能,以下是一些最佳实践的建议:
- 避免暴露过多数据: 确保分页不会一次性加载过多数据到客户端。
- 使用资源标识符: 通过资源标识符(如用户ID、帖子ID等)进行分页,而不是页码,以避免页码预测攻击。
- 优化数据库查询: 使用
SELECT *可能会带来性能问题,尽可能只选择需要的列。 - 用户友好的分页: 设计一个直观的用户界面,清晰显示当前页和总页数,并提供有效的导航控件。
- 错误处理: 妥善处理用户输入错误或不合法的情况,并给出清晰的错误信息。
以上建议不仅能够帮助构建一个更加安全的分页功能,同时也为用户提供了一个更加友好和高效的浏览体验。
简介:Java分页思想是处理大数据集时提高性能的关键技术。本文档详尽介绍了分页的基本原理、数据库分页实现方法、Java代码层面的分页策略,以及国际化和会话管理在分页中的应用。文档中包含代码示例、数据库设计图解、分页的分工图解、session监听应用图解、以及分页相关文档和课程资料,旨在帮助开发者全面理解并实践Java分页技术。

















 796
796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









