






-0.017612 14.053064 0
-1.395634 4.662541 1
-0.752157 6.538620 0
-1.322371 7.152853 0
0.423363 11.054677 0
0.406704 7.067335 1
0.667394 12.741452 0
首先把需要处理的数据集的格式张贴一下。
我们先来看第一个函数:导入数据集
from numpy import *
def loadDataSet():
dataMat = []; labelMat = []
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat,labelMat
在每一行中我们按照 line.strip() 默认分割方式(空格,tab等)进行分割,然后把数据的加上1.0作为开头,这是为了方便计算的,待会会进行说明;然后把列表加载到矩阵里。并把标签存在另一个矩阵里。
一般在二维平面分类的时候,我们的直线是
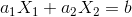
,但是放到矩阵里进行计算的话,就比较麻烦。我们把b移位到左边,生成新的表示方式:

,注意这里的X0永远是1,这样右边就是0了,在矩阵计算就只需要用到左边就行了。
然后是第二个函数:sigmoid以及梯度上升函数。
def sigmoid(inX):
return 1.0/(1+exp(-inX))
def gradAscent(dataMatIn, classLabels):
dataMatrix = mat(dataMatIn) #convert to NumPy matrix
labelMat = mat(classLabels).transpose() #convert to NumPy matrix
m,n = shape(dataMatrix)
alpha = 0.001
maxCycles = 500
weights = ones((n,1))
for k in range(maxCycles): #heavy on matrix operations
h = sigmoid(dataMatrix*weights) #matrix mult
error = (labelMat - h) #vector subtraction
weights = weights + alpha * dataMatrix.transpose()* error #matrix mult
return weights
标签进行一下转置,学习率设为0.001,然后一共学习500轮。注意这里的n打印出来以后是3,代表前面每个样本的三个数值。
weights的初始值设为了(1,1,1),然后乘出来的结果进入sigmoid函数,sigmoid函数接受一个矩阵,输出也是一个矩阵(而不仅是一个数值),我们把标签与sigmoid生成的结果相减,得到偏差error,然后通过梯度上升算法来修改weight。
简单说明一下:郑州人流手术费用 http://www.zzzzyy120.com/
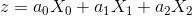
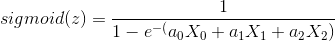
对任意Xi进行求偏导,然后就可以得到后面的表达式。注意一个样本的三个数据(X0,X1,X2)在经过了上面的sigmoid函数后,值会在1——0之间。误差的意义就是判断这个值与样本的标签(二分类的时候要么是0,要么是1)的差距是多少,然后通过梯度上升进行计算。为什么是梯度上升以及为什么这么求,大家可以看别人的博客,李航的统计学习书也比较详细,李宏毅的视频里也介绍了。这里我就懒得再写了。
然后再看第三个函数:关于随机梯度上升法。
def stocGradAscent0(dataMatrix, classLabels):
m,n = shape(dataMatrix)
alpha = 0.01
weights = ones(n)
for i in range(m):
h = sigmoid(sum(dataMatrix[i]*weights))
error = classLabels[i] - h
weights = weights + alpha * error * dataMatrix[i]
return weights
因为不再是一堆样本的矩阵相乘,这里只是数组,所以需要用到sum(dataMatrix[i]*weights),将数值乘权重然后加起来。
然后上升的梯度也是加一个数值。
随意梯度上升可能会震荡很大,因为存在很多分类不好的数据。改进方式见第四个函数。
第四个函数:改进的随机梯度上升。
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = shape(dataMatrix)
weights = ones(n)
for j in range(numIter): dataIndex = range(m)
for i in range(m):
alpha = 4/(1.0+j+i)+0.01
randIndex = int(random.uniform(0,len(dataIndex)))
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights
这个代码改进了两个地方:
一是 alpha = 4/(1.0+j+i)+0.01 ,在迭代时随时调整学习率。
二是通过生成随机数来随机选择第几个样本,这里通过dataIndex = range(m)先来生成一个数组,数据变化从0到m-1,然后选中一个值后,用完将其剔除。














 513
513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









