






 博主开发了一款英语词频统计软件,具备统计单词个数、标注音标和翻译、支持导出 Excel、查看单词分布、添加过滤词、对比文件单词异同、词形还原等功能,软件免费。此外,博主还提及公众号后续计划改进搜索功能。
博主开发了一款英语词频统计软件,具备统计单词个数、标注音标和翻译、支持导出 Excel、查看单词分布、添加过滤词、对比文件单词异同、词形还原等功能,软件免费。此外,博主还提及公众号后续计划改进搜索功能。
实在不好意思,好久没有更新文章了。对不住各位了。
最近做了个英语词频统计的软件。
功能如下:
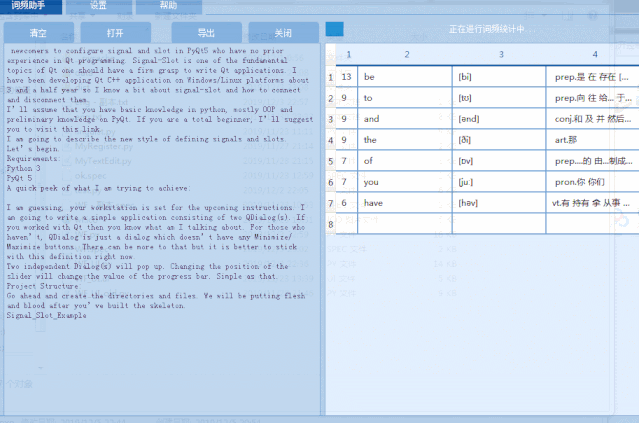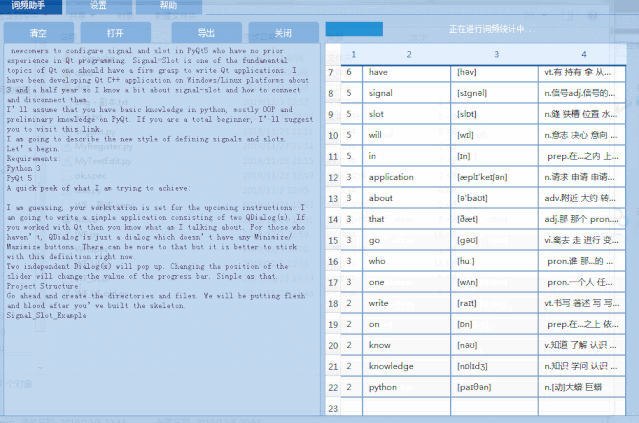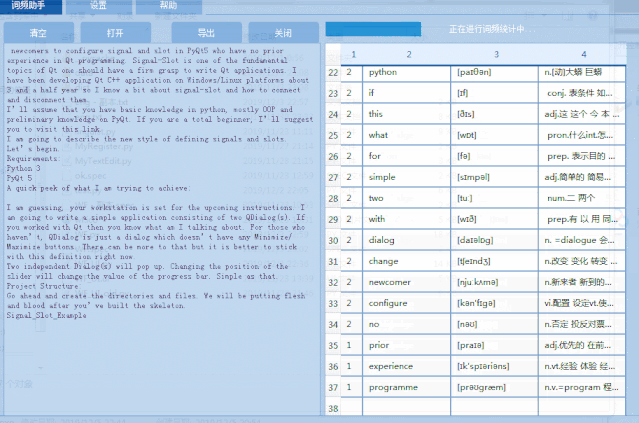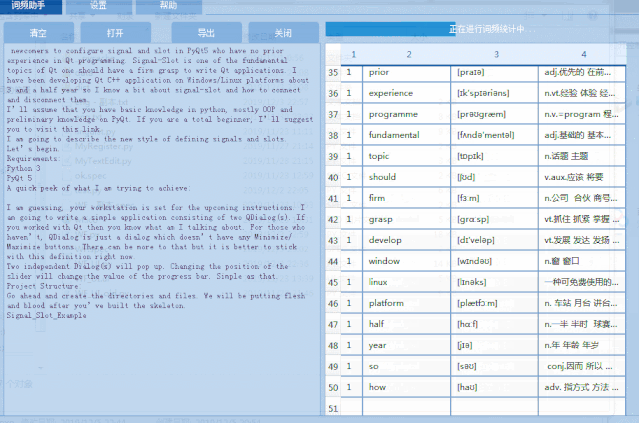
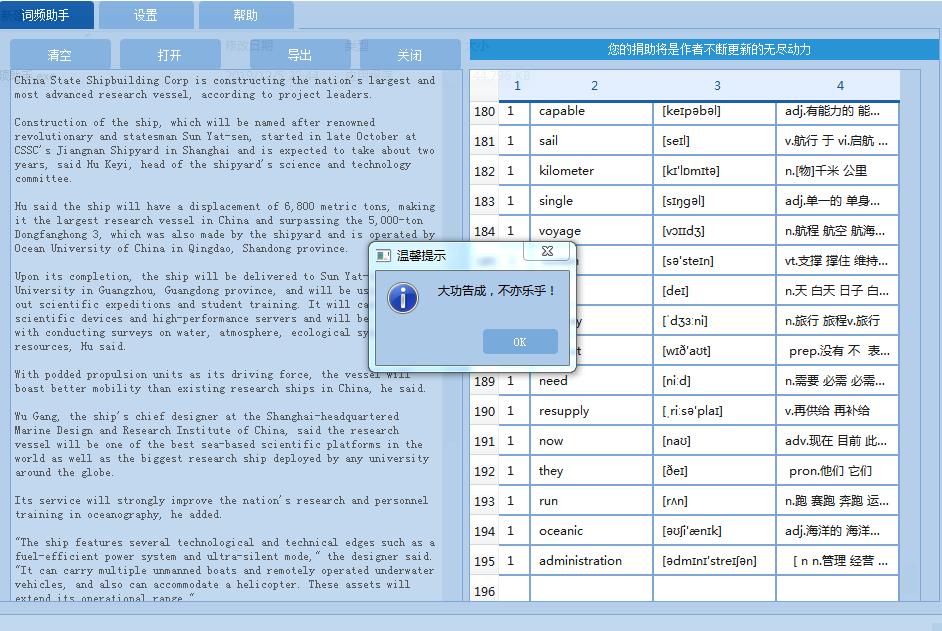
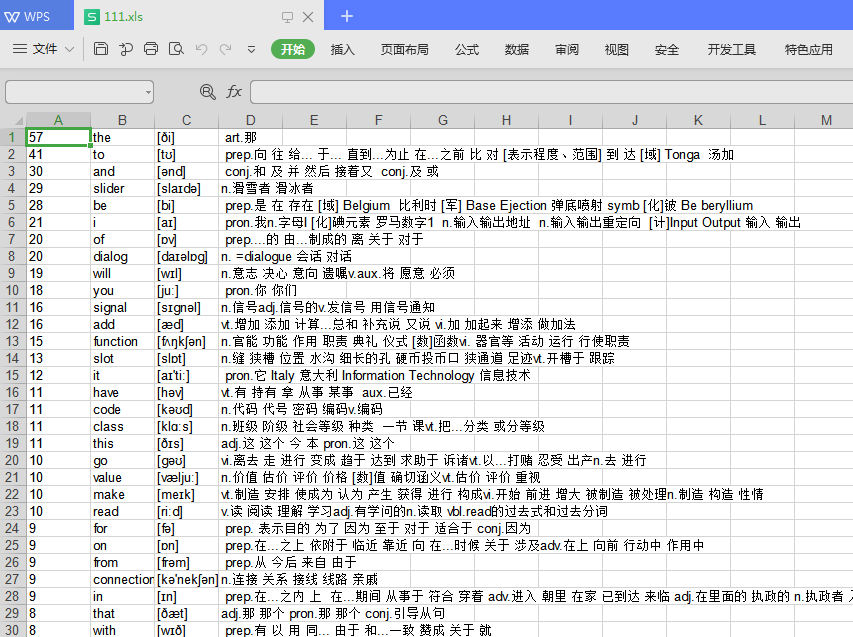
1)英语单词文本中单词个数统计,标注 音标 和 翻译,并支持导出为Excel文件。
2)支持点击统计的单词,查看单词在文本中的分布。用背景色标注显示。
3)支持自己添加过滤词。
4)支持对比两个Excel文件第一列单词的异同,并导出对比情况,方便查看两分文本单词的差异。
5)对于英语单词进行词形还原处理。避免went和gone统计程不同的单词。
软件完全免费,觉得好用可发捐助支持,您的支持将是我不断更新的无尽动力!
链接:pan.baidu.com/s/1P-qDnQ
提取码:tox0
下面是运行效果图:
---------------------------------------
这个公众号最开始是想分享一些自己爬取的资源。所以起名叫稀有资源。后来忙其他的,就荒废了。公众号的自动回复目前是支持软件类的电子书的搜索的。以后会好好改写一下后台的程序。争取实现电影,电子书,视频教程等分类进行关键字搜索回复的功能。人在日本,12月28日会有个长假。到时候除了外出游玩,会留点时间改写后台程序。让这个公众号更好的服务大家。也希望大家提出自己的建议,希望获得怎样的内容。
谢谢大家。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









