






今天遇到一个问题,使用python的find函数寻找字符串中的第一个空格时没有找到正确的位置,例如:
http://zc.whmc.edu.cn ==> 无法访问的网站或无效的招标网站

使用find(" ")函数寻找时找到的第一个空格对应在==>后面的那个位置。一开始觉得是编码问题,但是文件是用UTF-8编码的,按理说不应该产生编码问题,就用Sublime打开一看是这样的:
可以看到,我的Sublime设置了显示空白,所以第二个红线上方有一个白点,而第一个红线上方却没有,这说明第一个红线上方那个字符确实不是一个空格,也就是说函数的运行没有问题。但那个空格倒底是个什么东西呢?在Sublime中File-->Reopen with Encoding-->Hexadecimal打开文件可以看到是这样的:
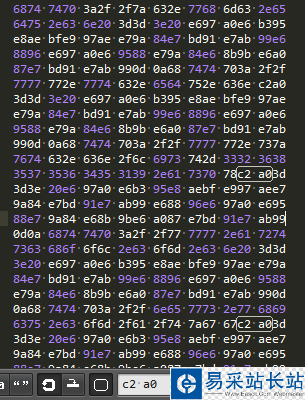
在网上可以查到,==>对应的UTF-8编码是x3dx3dx3e,所以前面的那个神秘字符的编码就是xc2xa0,上网查到这是一个叫做Non-breaking space的东西,用于阻止在此处自动换行和阻止多个空格被压缩成一个。至于解决方法,先用subplace("xc2xa0", " ")把这个特殊的空格替换一下就行了。
去除特殊空格:xc2xa0
在去除空格的时候遇到一种情况:
a = '2 '
b = '3'
print a.split(),b
输出结果:
['2xc2xa0'] 3
在网上可以查到,==>对应的UTF-8编码是x3dx3dx3e,所以前面的那个神秘字符的编码就是xc2xa0,上网查到这是一个叫做Non-breaking space的东西,用于阻止在此处自动换行和阻止多个空格被压缩成一个。至于解决方法,先用subplace("xc2xa0", " ")
a = '2 '
b = '3'
print a.replace("xc2xa0", ""),b
输出结果:

python 爬虫爬取内容时, xa0 、 u3000 的含义与处理方法
处理方法
str.replace(u'xa0', u' ')
最近用 scrapy 爬某网站,发现拿到的内容里面含有 xa0 、 u3000 这样的字符,起初还以为是编码不对,搜了一下才知道是见识太少 233 。
xa0 是不间断空白符
我们通常所用的空格是 x20 ,是在标准ASCII可见字符 0x20~0x7e 范围内。
而 xa0 属于 latin1 (ISO/IEC_8859-1)中的扩展字符集字符,代表空白符nbsp(non-breaking space)。
latin1 字符集向下兼容 ASCII ( 0x20~0x7e )。通常我们见到的字符多数是 latin1 的,比如在 MySQL 数据库中。
这里也有一张简陋的Latin1字符集对照表。
u3000 是全角的空白符
根据Unicode编码标准及其基本多语言面的定义, u3000 属于CJK字符的CJK标点符号区块内,是空白字符之一。它的名字是 Ideographic Space ,有人译作表意字空格、象形字空格等。顾名思义,就是全角的 CJK 空格。它跟 nbsp 不一样,是可以被换行间断的。常用于制造缩进, wiki 还说用于抬头,但没见过。















 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









