



在 Spring AI 中,流式输出(Streaming Output)是一种逐步返回 AI 模型生成结果的技术,允许服务器将响应内容分批次实时传输给客户端,而不是等待全部内容生成完毕后再一次性返回。
这种机制能显著提升用户体验,尤其适用于大模型响应较慢的场景(如生成长文本或复杂推理结果)。
技术实现
在 Spring AI 中流式输出的实现有以下两种方式:
- 通过 ChatModel 实现流式输出。
- 通过 ChatClient 实现流式输出。
ChatModel 流式输出
Spring AI 中的流式输出实现非常简单,使用 ChatModel 中的 stream 即可实现:
@RequestMapping(value = "/streamChat", produces = "text/event-stream")
public Flux<String> streamChat(@RequestParam(value = "msg") String msg) {
return chatModel.stream(msg);
}
ChatClient 流式输出
ChatClient 流式输出实现也很简单,也是调用 stream().content() 返回 Flux 对象即可:
@RequestMapping("/stream")
public Flux<String> stream(String question) {
return chatClient.prompt(question)
.stream()
.content();
}
底层实现
那么问题来了流式输出的底层实现究竟是啥呢?
根据以往的经验我们知道,流式输出的实现技术基本有两种:
- Spring MVC(Servlet)+ SSE 实现流式输出。
- Spring WebFlux Reactor 模型实现流式输出。
SSE 介绍
SSE(Server-Sent Events)是一种允许服务器向浏览器或其他客户端推送实时更新的技术。它是一种单向通信机制,服务器可以主动向客户端发送数据,而客户端无需频繁轮询服务器请求数据。SSE 是基于 HTTP 协议的,使用标准的 text/event-stream MIME 类型来传输数据。
SSE 主要特点
- 单向通信:SSE 仅支持服务器到客户端的单向通信,客户端不能向服务器发送消息。如果需要双向通信,可以结合 WebSocket 或其他技术。
- 基于 HTTP:SSE 使用标准的 HTTP 协议,不需要额外的协议支持,因此兼容性较好。
- 自动重连:客户端在连接中断后会自动尝试重新连接。
- 数据格式:SSE 数据以特定的格式发送,每条消息以 data: 开头,以两个换行符 \n\n 结尾。
- 事件类型:可以为每条消息指定事件类型,客户端可以通过监听特定事件类型来处理不同的消息。
Spring MVC(Spring Web)底层是基于 Servlet 实现的,它是使用 SseEmitter 技术实现 SSE 协议实现流式输出的。
SseEmitter 基本用法
这里提供一个 SseEmitter 的简单使用案例,实现流式输出,让大家更好的理解这个技术点:
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.servlet.mvc.method.annotation.SseEmitter;
import java.io.IOException;
@RestController
public class SseDemoController {
@GetMapping(value = "/sse-demo", produces = "text/event-stream")
public SseEmitter streamData() {
// 设置超时时间(单位:毫秒)
SseEmitter emitter = new SseEmitter(30_000L); // 30秒超时
// 异步任务模拟流式输出
new Thread(() -> {
try {
for (int i = 1; i <= 5; i++) {
String message = "第 " + i + " 条消息";
emitter.send(message);
Thread.sleep(1000); // 每秒发送一次
}
emitter.complete(); // 完成推送
} catch (IOException | InterruptedException e) {
emitter.completeWithError(e); // 异常处理
}
}).start();
return emitter;
}
}
Spring WebFlux 介绍
Spring WebFlux 是 Spring Framework 5 引入的响应式 Web 框架,旨在解决高并发场景下传统同步阻塞模型(如 Spring MVC)的性能瓶颈。其核心目标是通过非阻塞异步编程模型提升系统吞吐量,适用于 I/O 密集型任务(如微服务通信、实时数据流处理)。
Spring WebFlux 与 Spring MVC 不同,它基于 Reactive Streams 规范实现的,支持背压机制(Backpressure),防止数据生产者压垮消费者。
背压机制:通过订阅者主动控制数据流速,避免内存溢出。例如,消费者可动态调整请求量,生产者根据反馈调整数据生成速度.
Spring AI 流式输出
说完了前置知识,咱们回到主题:Spring AI 是如何实现流式输出的?
要搞清楚这个问题,我们需要看流式输出对象 Flux 的实现源码:
查看 Flux 源码我们发现它是属于 reactor.core.publisher 包下的抽象类:
并且看类注释和类所在的 jar 包我们就明白了:
Spring AI 中的流式输出是通过 Reactor Streams 模型实现的,和 Spring WebFlux 的底层实现是一样的技术。
具体执行流程:Reactor Streams 会订阅数据源,当有数据时,Reactor Streams 以分块流的方式发送给客户端(用户)。
Reactor 介绍
Reactor 是一种事件驱动的高性能网络编程模型,主要用于处理高并发的网络 I/O 请求。其核心思想是通过一个或多个线程监听事件,并将事件分发给相应的处理程序,从而实现高效的并发处理。
Reactor 模型的主要特征如下:
- 事件驱动:所有 I/O 操作都由事件触发并处理。
- 非阻塞:操作不会因为 I/O 而挂起,避免了线程等待的开销。
- 高效资源利用:通过少量线程处理大量并发连接,提升性能。
- 组件分离:将事件监听(Reactor)、事件分发(Dispatcher)和事件处理(Handler)解耦,使代码结构更清晰。
Reactor 实现方式有三种:
- 单线程 Reactor 模型:所有操作在一个线程完成,适用于低并发场景。
- 多线程 Reactor 模型:主线程处理连接,子线程池处理 I/O 和业务。
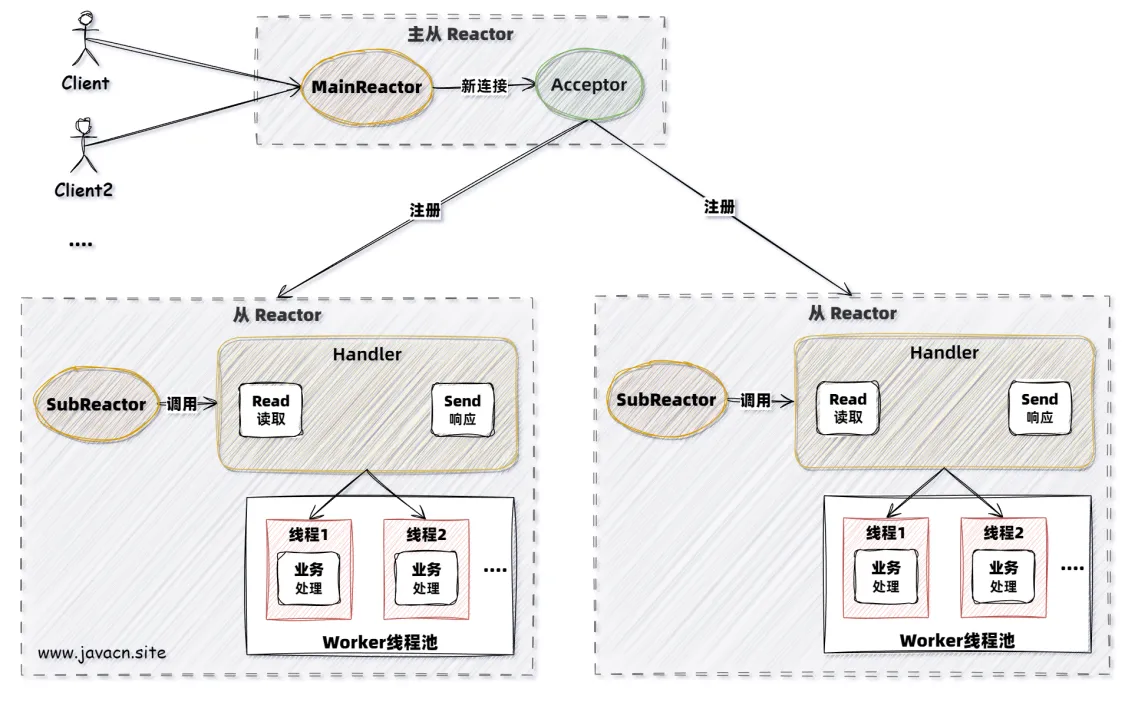
- 主从 Reactor 模型:主线程池处理连接,子线程池处理 I/O(进一步优化资源分配)。
生产级别使用的 Reactor 基本都是主从 Reactor 模型,它的执行流程如下:
小结
Spring AI 中的流式输出有两种实现,而通过查看这两种流式输出的实现源码可知,Spring AI 中的流式输出是通过 Reactor Streams 技术实现的,当客户端发送请求时,会建立连接并订阅数据源,当有数据时,Reactor Streams 以分块流的方式发送给客户端(用户)。
原创作者: vipstone 转载于: https://www.cnblogs.com/vipstone/p/18843073本文已收录到我的技术小站 www.javacn.site,其中包含的内容有:Spring AI、LangChain4j、MCP、Function Call、RAG、向量数据库、Prompt、多模态、向量数据库、嵌入模型等内容。

















 5247
5247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









