







概述
spark stream是对spark core api的扩展;对于spark core不太了解的请阅读:spark系列:spark core 数据交互技术点(数据模型)。所以本质上是通过批处理来模拟流处理。
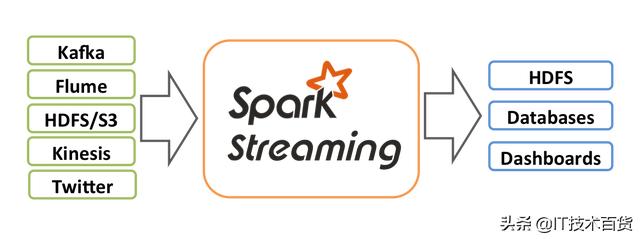
spark stream的流数据源可以来自Kafka, Flume, Kinesis, 或 TCP sockets甚至是文件。
spark stream
对于流数据可以做很多复杂的处理(只有想不到,没有做不到的),如map操作、reduce操作、join操作,甚至是在线训练机器学习模型等等。
最终处理完之后的数据可以写入各种文件系统,如HDFS、数据库等等。
内部机制
spark stream模块接收流数据,并按照时间维度将其分割成一段段的小量的批数据,然后通过spark core引擎来处理。
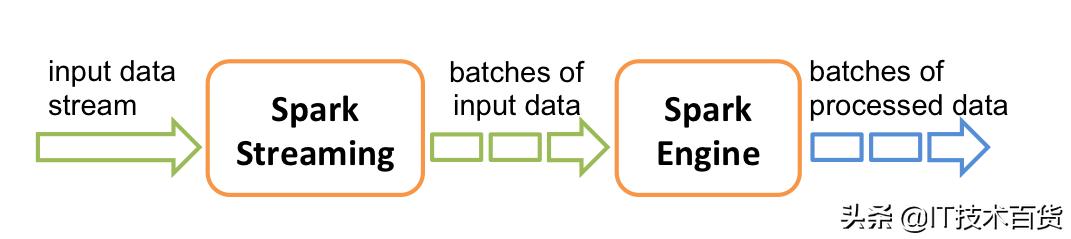
批处理模拟流处理
对外提供的接口本质上是对离散小批量数据(discretized stream or DStre
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1422
1422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









