







互联网时代除了业务迭代速度快,还有就是数据增速也比较快。单应用、单实例、单数据库的时代早已不复返。现在,作为技术研发,如果参与的项目没有用到分库分表,都不好意说自己做过大项目。
以电商为例, 角色分为买家和卖家,当网站的规模发展到一定的规模后,系统订单采用单表是满足不了用户需求的。分库分表势在必行。由于存在买家、卖家两个维度,所以一个Sharding Key满足不了业务需求。
常规的解决方式是采用空间换时间,毕竟存储的成本越来越低,我们会考虑数据复制,异构化处理。也同步一份数据到卖家的订单库,然后以卖家uid作为 Sharding Key 分片,专门供商家查询订单。
数据异构有两种方式:
1、写入DB订单表时,采用双写模式,买家表创建完后,然后在卖家表也创建一份数据记录,可以采用不用的分表键,写入不同的数据分片中。由于额外增加数据同步的写操作,会导致同步接口RT增大,从而影响整个系统的QPS。
可能有同学立马会说,我们可以采用异步方式,系统启动时初始化一个线程池,把同步业务逻辑封装成任务丢给线程池异步去执行。由于是本地任务,很难监控任务的执行情况,如果不小心赶上发布重启,还会有数据丢失的风险
2、另一种方式可以借助MQ,买家库写完后,发送事务消息,然后接口就可以结束响应。至于卖家库的操作可以消息任务,异步去写入,如果写入失败可以借助消息框架自身的重试机制。
缺点:如果一个业务的数据要异构化处理,就需要对所有的业务动作封装MQ消息体,代码无法做到通用性,跟业务强耦合。
3、有没有更通用的方式,可以通过binlog构建数据实时同步。这里要一个阿里巴巴的开源框架 Canal。
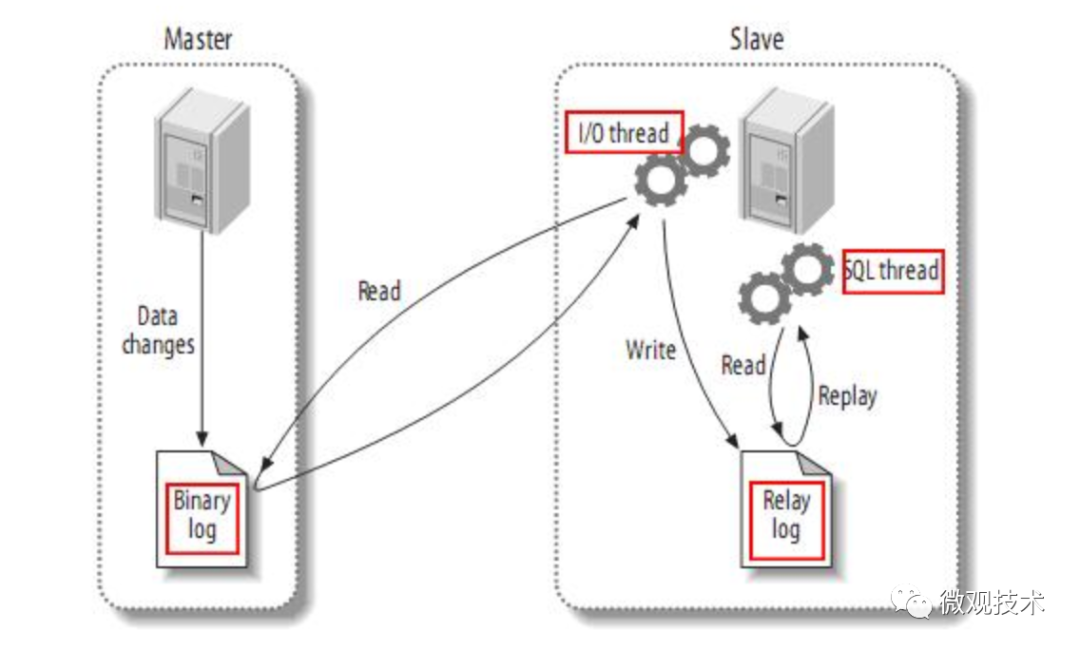
MySQL主备复制原理
MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
Canal 将自己伪装成一个 MySQL 从库,从 MySQL 实时接收 Binlog 然后写入数据库表。为了能够支撑下游众多的数据库,从 Canal 出来的 Binlog 数据肯定不能直接去写下游那么多数据库,一是写不过来,二是对于每个下游数据库,它可能还有一些数据转换和过滤的工作要做。所以需要增加一个 MQ 来解耦上下游。
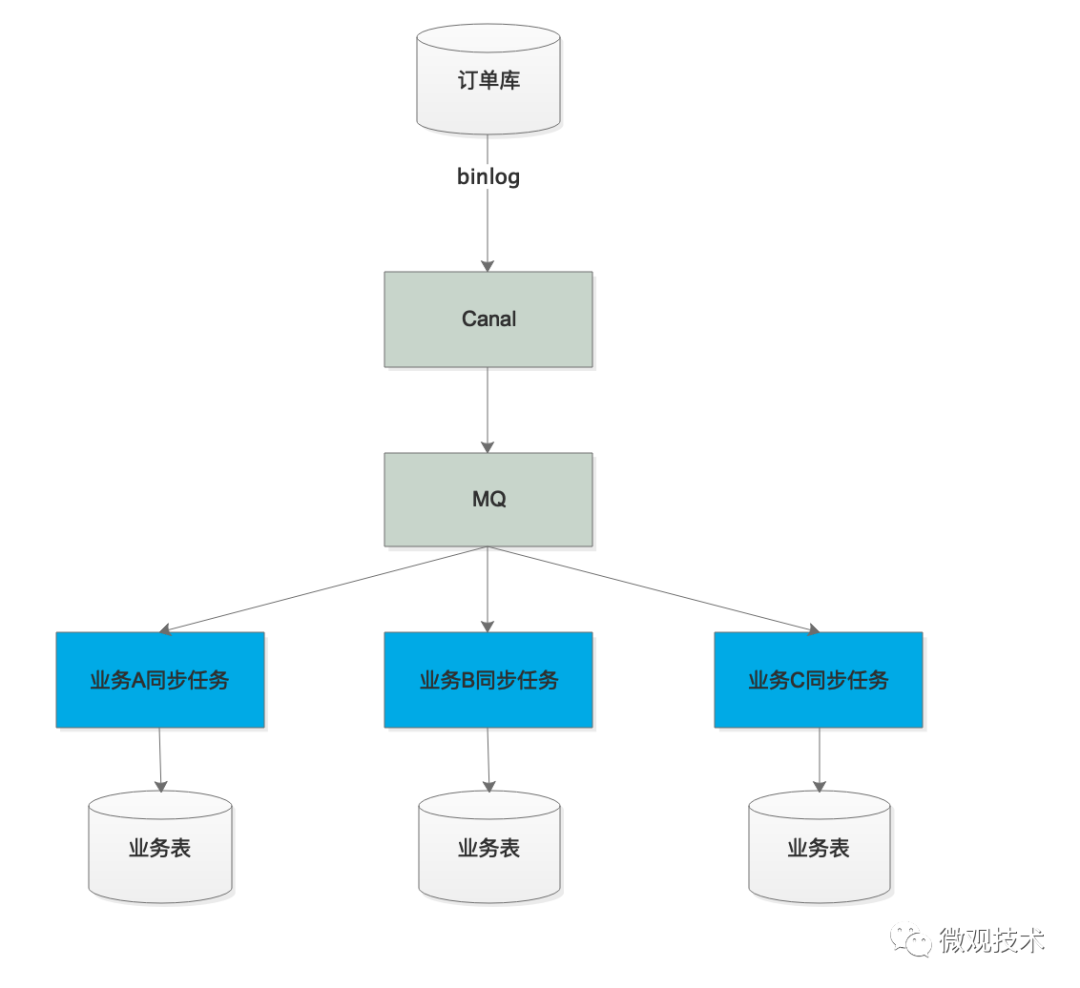
Canal 从 MySQL 收到 Binlog 并解析成结构化数据之后,直接写入到 MQ 的一个订单 Binlog 主题中,然后每一个需要同步订单数据的业务方,都去订阅这个 MQ 中的订单 Binlog 主题,消费解析后的 Binlog 数据。在每个消费者自己的同步程序中,它既可以直接入库,也可以做一些数据转换、过滤或者计算之后再入库,这样就比较灵活了。
注意:由于采用异步消息,数据同步可能会存在一定延迟,一般都是在毫秒级别,不过要注意监控消息的堆积情况,避免一些特殊情况下,消息大量堆积导致数据同步延迟拉大,进而影响到正常业务。
在数据同步的实时方面,有什么可以做的?
我们都知道电商大促期间,系统的并发是很高的,数据库写操作很频繁,同步的binlog流量会比较大,消费MQ消息的同步程序很容易成为性能瓶颈,从而影响到数据同步实时性。
面对这个问题,我们一般会通过多加一些同步程序的实例数,或者增加线程数,通过增加并发来提升处理能力。但是要考虑一个点,MySQL 主从同步 Binlog,是一个单线程的同步过程,原因很简单,为了确保数据一致性,Binlog 的顺序很重要,是绝对不能乱序的。MQ 的topic也必须设置为只有 1 个分区(队列),这样才能保证数据同步过程中的 Binlog 是严格有序的,写到目标数据库的数据才能是正确的。
但是单线程处理速度肯定跟不上,有没有什么好的解决方案?我们可以考虑跟业务结合起来解决。
比如电商的订单库,不同的binlog并发执行受影响的只可能是同一条记录,也就是说同一个订单,如果更新的 Binlog 执行顺序错了,那同步出来的订单数据真的就错了。相反,不同的行记录,错乱的执行顺序并不会影响到数据的一致性。
画外音:有因果关系的数据之间必须要严格地保证顺序,没有因果关系的数据之间的顺序是无所谓的。
基于这个理论,我们要评估下游同步程序的消费能力,计算出并发数。然后设置 MQ 中topic的分区(队列)数量和并发数一致。因为 MQ 是可以保证同一分区内,消息是有序的。所以我们需要把具有因果关系的 Binlog 放到相同的分区中。对应到订单库就是,相同订单号的 Binlog 必须发到同一个分区上。
关于canal的快速使用,可参考下面的文章
https://github.com/alibaba/canal/wiki/Canal-Kafka-RocketMQ-QuickStart
往期推荐
开源实战 | Canal生产环境常见问题总结与分析
Java | 过滤器 和 拦截器 的6个区别
大坑 | JPA框架配置该参数后直接就删库了
SQL调优 | SQL 书写规范及优化技巧(下)
后端技术漫谈 | 原创文章全导航















 5946
5946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









