








导读:Python数据科学基础库主要是三剑客:Numpy,pandas以及Matplotlib,每个库都集成了大量的方法接口,配合使用功能强大。
本篇对Numpy常用的方法进行思维导图式梳理,多数方法仅拉单列表,部分接口辅以解释说明及代码案例。最后分享了个人关于axis和广播机制的理解。
作者:luanhz 来源:小数志(ID:Datazhi)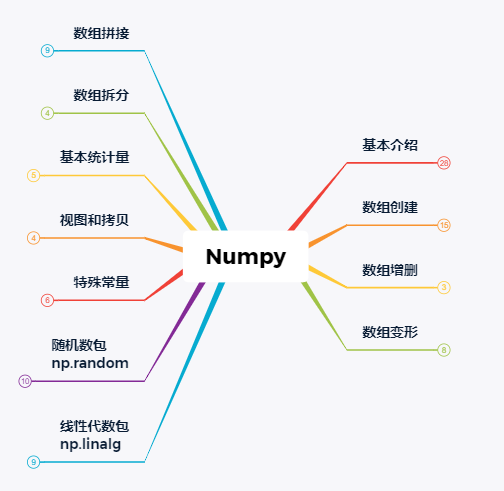 ▲本文知识要点一级菜单
01 基本介绍
▲本文知识要点一级菜单
01 基本介绍
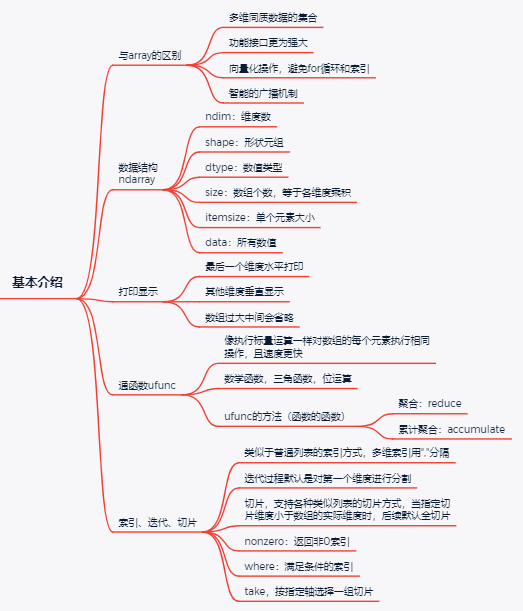
- Numpy:Numerical Python缩写,提供了底层基于C语言实现的数值计算库,与Python内置的list和array数据结构相比,其支持更加规范的数据类型和极其丰富的操作接口,速度也更快
- Numpy的两个重要对象是ndarray和ufunc,其中前者是数据结构的基础,后者是接口方法的基础
- ufunc,通函数,其意义是可以像执行标量运算一样执行数组运算,本质即是通过隐式的循环对各个位置依次进行标量运算。只不过这里的隐式循环交由底层C语言实现,因此相比直接用Python循环实现,ufunc语法更为简洁、效率更为高效
- 索引、迭代和切片操作方式与普通列表比较类似,但是支持更为强大的bool索引
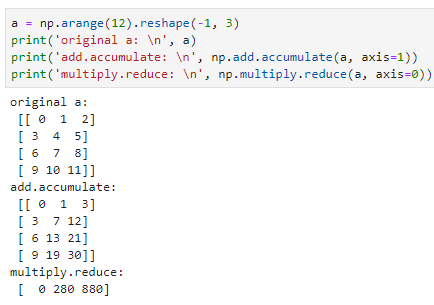
- reduce,聚合方法
- accumulate,累计聚合
- reduceat,按指定轴向、指定切片聚合
- outer,外积
 02 数组创建
02 数组创建
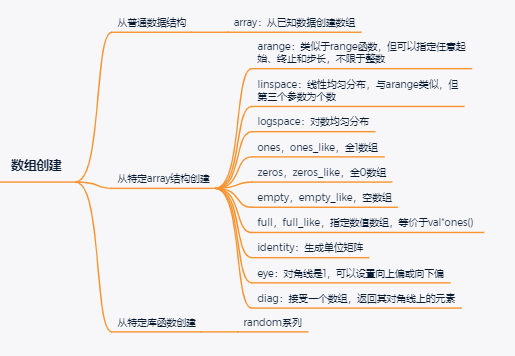 Numpy中支持
5类创建数组的方式:
Numpy中支持
5类创建数组的方式:
- 从普通数据结构创建,如列表、元组等
- 从特定的array结构创建,支持大量方法,例如ones、zeros、empty等等
-
- empty接收指定大小创建空数组,这里空数组的意义在于未进行数值初始赋值,随机产生,因而速度要更快一些
- linspace和arange功能类似,前者创建指定个数的数值,后者按固定步长创建,其中linspace默认包含终点值(可以通过endpoint参数设置为false),而arange则不含终点
- 从磁盘读取特定的文件格式
- 从缓存或字符读入数组
- 从特定的库函数创建,例如random随机数包
 Numpy提供了与列表类似的
增删操作,其中
Numpy提供了与列表类似的
增删操作,其中
- append是在指定维度后面拼接数据,要求相应维度大小匹配
- insert可以在指定维度任意位置插入数据,要求维度大小匹配
- delete删除指定维度下的特定索引对应数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1070
1070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









