



 本文详细介绍了Linux内核中的双向链表实现方式,并通过具体示例展示了如何定义链表节点、初始化链表以及进行节点操作等核心功能。
本文详细介绍了Linux内核中的双向链表实现方式,并通过具体示例展示了如何定义链表节点、初始化链表以及进行节点操作等核心功能。
关于Linux内核代码的真正接触还是最近2个月,首先接触这个最简单的就是双向链表了,这个链表可谓真的短小。原来有些时候,看这种经典代码也是一种享受。在大学里面写的那些双向链表那只不过是学习而已。
#ifndef _LINUX_LIST_H
#define _LINUX_LIST_H
#ifdef __KERNEL__
structlist_head {
structlist_head *next, *prev;
};
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) /
structlist_head name = LIST_HEAD_INIT(name)
#define INIT_LIST_HEAD(ptr) do { /
(ptr)->next = (ptr); (ptr)->prev = (ptr); /
}while(0)
static__inline__void__list_add(structlist_head *new,
structlist_head * prev,
structlist_head * next)
{
next->prev =new;
new->next = next;
new->prev = prev;
prev->next =new;
}
static__inline__voidlist_add(structlist_head *new,structlist_head *head)
{
__list_add(new, head, head->next);
}
static__inline__voidlist_add_tail(structlist_head *new,structlist_head *head)
{
__list_add(new, head->prev, head);
}
static__inline__void__list_del(structlist_head * prev,
structlist_head * next)
{
next->prev = prev;
prev->next = next;
}
static__inline__voidlist_del(structlist_head *entry)
{
__list_del(entry->prev, entry->next);
}
static__inline__voidlist_del_init(structlist_head *entry)
{
__list_del(entry->prev, entry->next);
INIT_LIST_HEAD(entry);
}
static__inline__intlist_empty(structlist_head *head)
{
returnhead->next == head;
}
static__inline__voidlist_splice(structlist_head *list,structlist_head *head)
{
structlist_head *first = list->next;
if(first != list) {
structlist_head *last = list->prev;
structlist_head *at = head->next;
first->prev = head;
head->next = first;
last->next = at;
at->prev = last;
}
}
#define list_entry(ptr, type, member) /
((type *)((char*)(ptr)-(unsignedlong)(&((type *)0)->member)))
#define list_for_each(pos, head) /
for(pos = (head)->next; pos != (head); pos = pos->next)
#endif /* __KERNEL__ */
#endif
这些链表结构体只能在内核使用,但其实我们在平时写链表时,可以仿照这样,精简。
如果我们需要某种数据结构的队列,就在这种结构内部放上list_head结构即可。例如:
typedef struct page {
struct list_head list;
.....
struct list_head lru;
....
}page_t;
这里面放了了2个list_head结构体(list和lru),这代表page结构体可以存在两个队列中,如下面图所示:
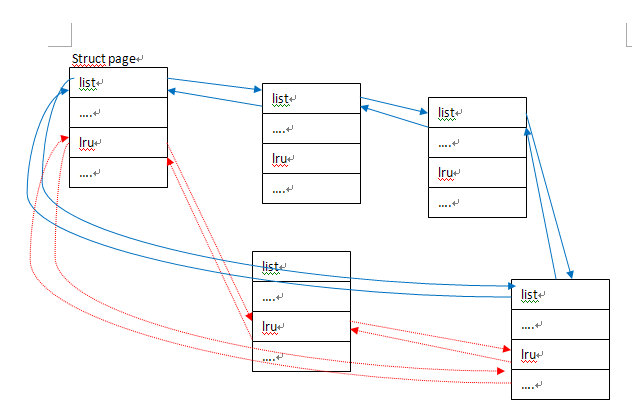
在这链表里面最关键的地方在
#define list_entry(ptr, type, member) /
((type *)((char *)(ptr)-(unsigned long)(&((type *)0)->member)))
通过它才可以访问链表里面真正的元素
例如:
list_head pstList;
struct page *page;
page = list_entry(pstList, struct page, list); 其中pstList 指向一个page结构体。
list_entry的原理的,通过这个结构体链表头在结构体中的偏移来获取 某个结构体的地址。
(unsigned long)(&((type *)0)->member)),这个是获取结构链表头的偏移值,如在page中,list偏移page的值
然后再把该地址减去该偏移才真正得到我们想要的结构体地址。

















 753
753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









