






物理内存分配
物理内存主要结构 node zone page
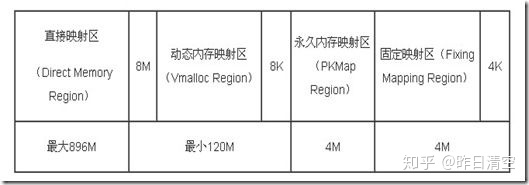
总体管理分为两块:页面级内存管理和slab内存管理
首先讲一下node,节点的引入是因为NUMA(非一致内存访问)的出现
zone是node下面的细分,类型用zone_type表示,主要分为DMA,NORMAL,HIGHMEM三类。
page是物理内存管理的最小单位,存放在mem_map数组中,page大小取决于MMU,MMU用于将虚拟地址转换位物理地址。


伙伴系统是物理内存分配的核心。可以分配单个或连续的物理页面。
每个物理页面都有page对象严格对应,并且是固定的。
Linux初始化时,虚拟地址空间对应的物理页面直接映射到DMA NORMAL区,如果落在这两个区,说明虚拟到物理地址映射的页目录表项已经建立,而且是线性映射,相差3GB。如果落在HIGHMEM,说明对该页面尚未进行映射,那么就需要调用kmap来分配一个虚拟地址再映射到物理页面。注意64位系统不存在HIGHMEM。
页面分配器核心函数:allocpages和__get_freepages,二者最终都会调用allocpages_node。
gfp_mask是这些函数中的重要参数。可以去搜索对应的含义,太多就不展开了。
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask,
unsigned int order)
{
/* Unknown node is current node */
if (nid < 0)
nid = numa_node_id();
return __alloc_pages(gfp_mask, order, node_zonelist(nid, gfp_mask));
}
//分配2^order个连续物理页面并返回起始页的struct page实例
#define alloc_pages(gfp_mask, order)
alloc_pages_node(numa_node_id(), gfp_mask, order)
//如果gpf_mask未指定HIGHMEM,就默认DMA NORMAL,由于这两个在一开始已经建立了映射,所以可用
//page_address来获取对应页面的虚拟地址KVA对于新分配的高端物理页面,由于上面提到的尚未建立映射关系。所以需要两个操作
1.在内核的动态映射区分配一个KVA。
2.通过页表将1中的KVA映射到该物理页面上,调用kmap。
与kmap相反的是kunmap,可用于拆除映射+释放KVA。
void kunmap(struct page *page)
{
if (in_interrupt())
BUG();
if (!PageHighMem(page))
return;
kunmap_high(page);
}下面是一些常见函数
分配的函数
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{
struct page *page;
/*
* __get_free_pages() returns a 32-bit address, which cannot represent
* a highmem page
*/
VM_BUG_ON((gfp_mask & __GFP_HIGHMEM) != 0); //不能从高端内存分配
page = alloc_pages(gfp_mask, order); //完成实际分配
if (!page)
return 0;
return (unsigned long) page_address(page);//内核线性地址
}unsigned long get_zeroed_page(gfp_t gfp_mask)
{
return __get_free_pages(gfp_mask | __GFP_ZERO, 0);
}#define __get_dma_pages(gfp_mask, order)
__get_free_pages((gfp_mask) | GFP_DMA, (order))释放的函数
void free_pages(unsigned long addr, unsigned int order)
{
if (addr != 0) {
VM_BUG_ON(!virt_addr_valid((void *)addr));
__free_pages(virt_to_page((void *)addr), order); //返回线性虚拟地址
}
}void __free_pages(struct page *page, unsigned int order)
{
if (put_page_testzero(page)) {
if (order == 0)
free_hot_cold_page(page, 0);
else
__free_pages_ok(page, order);
}
}slab分配器
用于分配比一页要小的物理内存。slob slub是替代品,针对大型和嵌入式系统。
基本思想:先利用页面分配器分配单个或一组连续的物理页面,然后在此基础上再将页面分割成多个相等的小内存单元。
为了进行管理,需要用到两个最重要的结构struct kmem_cache 和 struct slab
struct kmem_cache {
/* 1) per-cpu data, touched during every alloc/free */
struct array_cache *array[NR_CPUS];
/* 2) Cache tunables. Protected by cache_chain_mutex */
unsigned int batchcount;
unsigned int limit;
unsigned int shared;
unsigned int buffer_size;
u32 reciprocal_buffer_size;
/* 3) touched by every alloc & free from the backend */
unsigned int flags; /* constant flags */
unsigned int num; /* # of objs per slab */
/* 4) cache_grow/shrink */
/* order of pgs per slab (2^n) */
unsigned int gfporder;//该kmem_cache种每个slab占用的页面数量,2^order个页面
/* force GFP flags, e.g. GFP_DMA */
gfp_t gfpflags;//通过伙伴系统寻找空闲页时的行为
size_t colour; /* cache colouring range */
unsigned int colour_off; /* colour offset */
struct kmem_cache *slabp_cache;
unsigned int slab_size;
unsigned int dflags; /* dynamic flags */
/* constructor func */
void (*ctor)(void *obj);//构造函数,初始化新分配的slab的所有内存对象
/* 5) cache creation/removal */
const char *name; //kmem_cache的名字
struct list_head next;//将kmem_cache加入到cache_chain链表
/* 6) statistics */
#ifdef CONFIG_DEBUG_SLAB
unsigned long num_active;
unsigned long num_allocations;
unsigned long high_mark;
unsigned long grown;
unsigned long reaped;
unsigned long errors;
unsigned long max_freeable;
unsigned long node_allocs;
unsigned long node_frees;
unsigned long node_overflow;
atomic_t allochit;
atomic_t allocmiss;
atomic_t freehit;
atomic_t freemiss;
/*
* If debugging is enabled, then the allocator can add additional
* fields and/or padding to every object. buffer_size contains the total
* object size including these internal fields, the following two
* variables contain the offset to the user object and its size.
*/
int obj_offset;
int obj_size;
#endif /* CONFIG_DEBUG_SLAB */
/*
* We put nodelists[] at the end of kmem_cache, because we want to size
* this array to nr_node_ids slots instead of MAX_NUMNODES
* (see kmem_cache_init())
* We still use [MAX_NUMNODES] and not [1] or [0] because cache_cache
* is statically defined, so we reserve the max number of nodes.
*/
struct kmem_list3 *nodelists[MAX_NUMNODES];
/*
* Do not add fields after nodelists[]
*/
};最后一个成员struct kmem_list3定义为
static void kmem_list3_init(struct kmem_list3 *parent)
{
INIT_LIST_HEAD(&parent->slabs_full);//kmem_cache中满员的slab加入
INIT_LIST_HEAD(&parent->slabs_partial);//kmem_cache中半空闲的slab加入
INIT_LIST_HEAD(&parent->slabs_free);//kmem_cache中完全空闲的slab加入
parent->shared = NULL;
parent->alien = NULL;
parent->colour_next = 0;
spin_lock_init(&parent->list_lock);
parent->free_objects = 0;
parent->free_touched = 0;
}struct slab定义为
struct slab {
union {
struct {
struct list_head list;
unsigned long colouroff;
void *s_mem; /* including colour offset */
unsigned int inuse; /* num of objs active in slab */
kmem_bufctl_t free;
unsigned short nodeid;
};
struct slab_rcu __slab_cover_slab_rcu;
};
};kmem_cache和slab形成分级管理
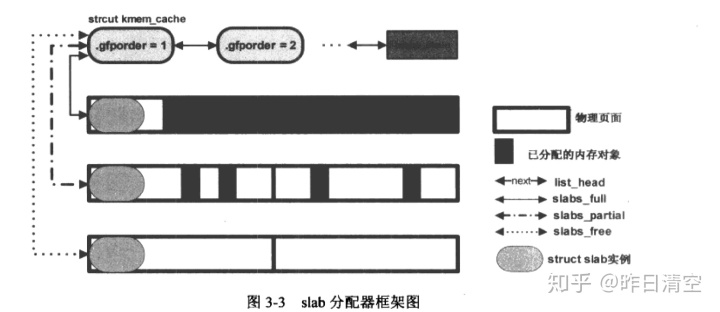
对于每个slab分配器,都需要一个struct kmem_cache。在slab系统尚未建立时,kemem cache就需要存在,使用的是静态内存分配
static struct kmem_cache cache_cache = {
.batchcount = 1,
.limit = BOOT_CPUCACHE_ENTRIES,
.shared = 1,
.buffer_size = sizeof(struct kmem_cache),
.name = "kmem_cache",
};struct cache_sizes {
size_t cs_size;
struct kmem_cache *cs_cachep;//存放size下新建的实例地址
#ifdef CONFIG_ZONE_DMA
struct kmem_cache *cs_dmacachep;
#endif
};初始化时,kmem_cache_init 遍历 malloc_sizes数组,对其中每个元素都调用kmem_cache_create在cache_cache中分配一个struct kmem_cache,并将实例所在地址放在cs_cachep中
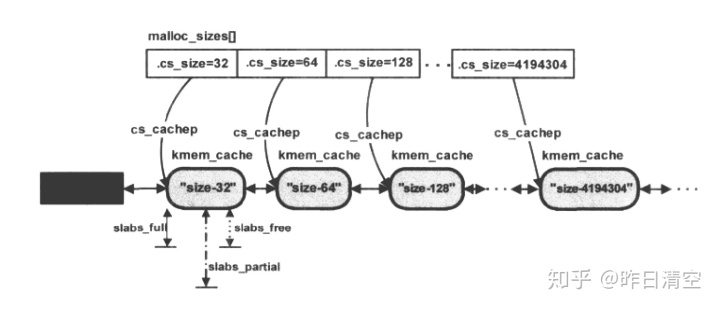
kmalloc是驱动程序中使用最多的一个内存分配函数,分配的内存在物理上连续,分配出来的空间保存原来的数据。建立在slab基础上。其中的参数size在malloc_sizes数组中找,找到第大于等于它的最小值。找到这样一个数组元素后,也获得了该元素对应的slab分配器的kmem_cache对象cachep,这个在上面提到,cachep存放新建的实例地址。最后函数调用kmem_cache_alloc进行内存的分配。通常返回cachep对应的slab分配器的。
需要注意一点,对于slab而言,kmalloc只能分配在地段内存区,如果调用kmalloc时使用HIGHMEM将会触发BUG_ON。如果内存不够,则kmalloc返回NULL。
对应的释放函数kfree,代码如下

下面分析一下之前提到的kmem_cache_create和kmem_cache_alloc。有些内核模块可能需要频繁分配和释放,slab分配器在这是可以作为一种内核对象的缓存,对象在slab中被分配,但是释放时并不会将占用的空间返回给伙伴系统,这样下次分配时就能直接得到对象的内存,利用了局部性原理,从而提高了性能。
可以通过kmem_cache_create来创建内核对象的缓存,成功创建之后就可以用kmem_cache_alloc在kmem_cache中分配对象。
对应的kmem_cache_destroy负责销毁kmem_cache_create创建的对象,kmem_cache_free负责把kmem_cache_alloc分配的对象释放掉。
其中kmem_cache_destroy首先从cache_chain链表中摘下要销毁的kmem_cache对象,之后调用__cache_shrink,确保cachep中没有尚未被释放的内存对象。
static int __cache_shrink(struct kmem_cache *cachep)
{
int ret = 0, i = 0;
struct kmem_list3 *l3;
drain_cpu_caches(cachep);
check_irq_on();
for_each_online_node(i) {
l3 = cachep->nodelists[i];
if (!l3)
continue;
drain_freelist(cachep, l3, l3->free_objects);
ret += !list_empty(&l3->slabs_full) ||
!list_empty(&l3->slabs_partial);
}
return (ret ? 1 : 0);
}如果cachep中所有对象都已经被释放掉,最终通过kmem_cache_free释放cachep指向的kmem_cache对象。
内存池
预先为将来要使用的对象分配内存空间,这些空间地址存在内存池对象中,真正需要分配时,调用前面的函数,分配失败则可以从内存池中取得预分配的内存池。
虚拟内存
32位处理器可寻址4GB的地址空间,这块空间即虚拟地址空间。通过MMU实现虚拟地址-->物理地址的转换。页表是实现转换的前提。
通常内核将4GB的虚拟地址空间分为两大块,顶部的1G留给内核,底部的3G留给用户空间,使用PAGE_OFFSET来标识该分段点。
下面是1GB的内核空间。其中vmalloc区主要用于vmalloc函数。
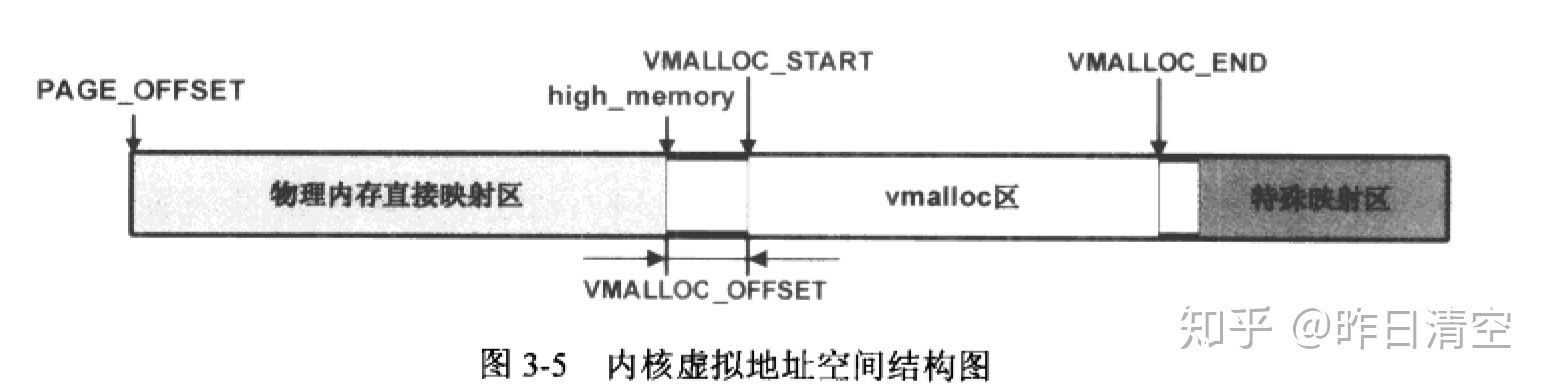
白色区域为空洞,不允许作任何地址映射,用于防止越界。
下面讲一下vmalloc和vfree:
vmalloc分配的虚拟地址空间连续,回忆一下之前的,kmalloc分配的物理地址空间连续。vmalloc主要针对vmalloc区进行操作。 但是并不鼓励使用vmalloc,因为效率远低于kmalloc。
使用红黑树来解决动态虚拟内存块的分配,对每个分配出来的虚拟内存块使用struct vm_struct来表示

next将vm_struct对象构成链表,表头为全局变量struct vm_struct * vmlist,addr为对应虚拟内存块的起始地址。size为虚拟内存块的大小,总是页面的整数倍。flags是标志,有两个重要的,VM_ALLOC VM_IOREMAP。
VM_ALLOC表示当前虚拟内存块给vmalloc使用,映射的是实际物理内存。
VM_IOREMAP表示当前虚拟内存块是给ioremap相关函数使用,映射的是io空间地址。
pages是被映射的物理内存页面所形成的数组首地址
nr_pages表示映射的物理页的数量
phys_addr表示映射的io空间起始地址
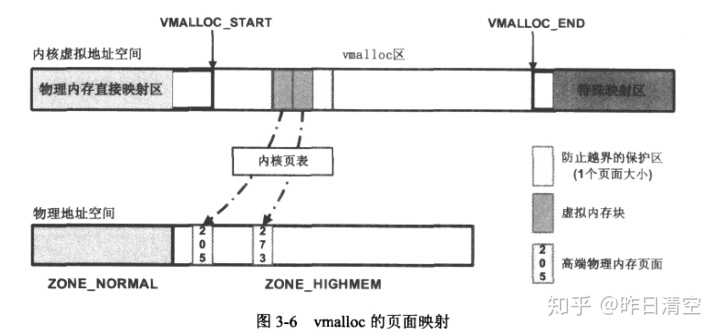
图中vmalloc分配的虚拟内存块通过内核页表,映射到了205和273的物理页面,注意到虚拟内存块的最后一块未被使用,用于越界保护。
使用vfree释放vmalloc分配的内存块。
PER-CPU变量
该变量为系统中的每个处理器都分配了该变量的一个副本。好处是cpu处理属于它的变量时无需考虑与其他cpu的竞争。
按照存储变量的空间来源分为静态per-cpu和动态per-cpu变量。前者代码编译时静态分配,后者执行期动态分配。
首先是静态。
#define DECLARE_PER_CPU(type, name)
DECLARE_PER_CPU_SECTION(type, name, "")
#define DECLARE_PER_CPU_SECTION(type, name, sec)
extern __PCPU_ATTRS(sec) __typeof__(type) name
#define __PCPU_ATTRS(sec)
__percpu __attribute__((section(PER_CPU_BASE_SECTION sec)))
PER_CPU_ATTRIBUTES
#define DEFINE_PER_CPU(type, name)
DEFINE_PER_CPU_SECTION(type, name, "")使用define_per_cpu定义的变量,系统中每个cpu都有其副本,如何做到的?
答案是在初始化期间调用了setup_per_cpu_areas,完成了变量副本的生成+per_cpu变量的动态分配机制初始化。
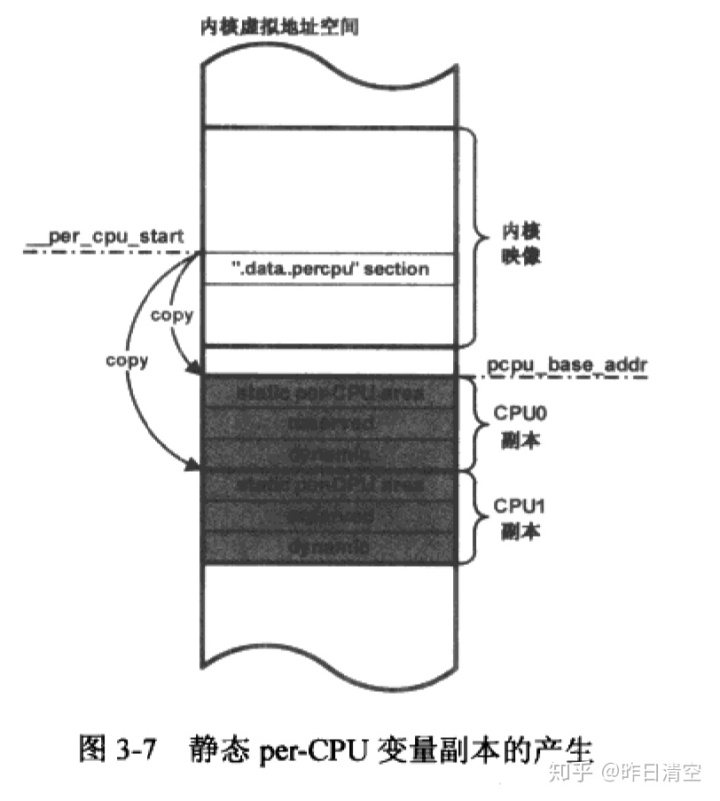
首先计算出".data..percpu"section的大小,然后setup_per_cpu_areas调用alloc_bootmem_nopanic来分配一段内存,保存per-cpu变量副本。然后进行数据复制,使用了memcpy。
per-cpu变量的创建使用 alloc_percpu,底层调用__alloc_percpu,释放使用了free_percpu。
下面讲讲共同per-CPU变量的分配,主要是 分配副本空间+访问机制。内核基于chunk来实现,chunk是存放管理数据的容器。根据空闲空间的大小在一个pcpu_slot数组所表示的链表中进行迁移,数组索引知名了其链表中chunk空闲空间的大小。需要动态分配时,就在pcpu_slot中查找满足需求的空间,如果没用满足的空间,就重新创建新的chunk。新的chunk在vmalloc区分配副本空间,起始地址在chunk的base_addr,即图中的base_addr。通过map成员跟踪空间分配信息。
如何访问per-CPU变量?
get_cpu_var宏返回一个指向当前处理器数据的实例,同时禁止了内核抢占。















 213
213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









