







 本文介绍了IN(Instance Normalization)和AdaIN(Adaptive Instance Normalization)在风格迁移中的作用和原理。IN通过对每个通道进行规范化,而AdaIN引入了风格图像的均值和标准差作为仿射参数,实现任意风格转换。实验表明,AdaIN在图像到图像转换、语音转换和风格迁移任务中表现出色。参考代码和论文链接提供进一步阅读。
本文介绍了IN(Instance Normalization)和AdaIN(Adaptive Instance Normalization)在风格迁移中的作用和原理。IN通过对每个通道进行规范化,而AdaIN引入了风格图像的均值和标准差作为仿射参数,实现任意风格转换。实验表明,AdaIN在图像到图像转换、语音转换和风格迁移任务中表现出色。参考代码和论文链接提供进一步阅读。
Ulyanov发现在风格迁移上使用IN效果比BN好很多,从他开始凡是风格迁移都离不开IN和其变种AdaIN,本文简要介绍IN和AdaIN原理,应用。
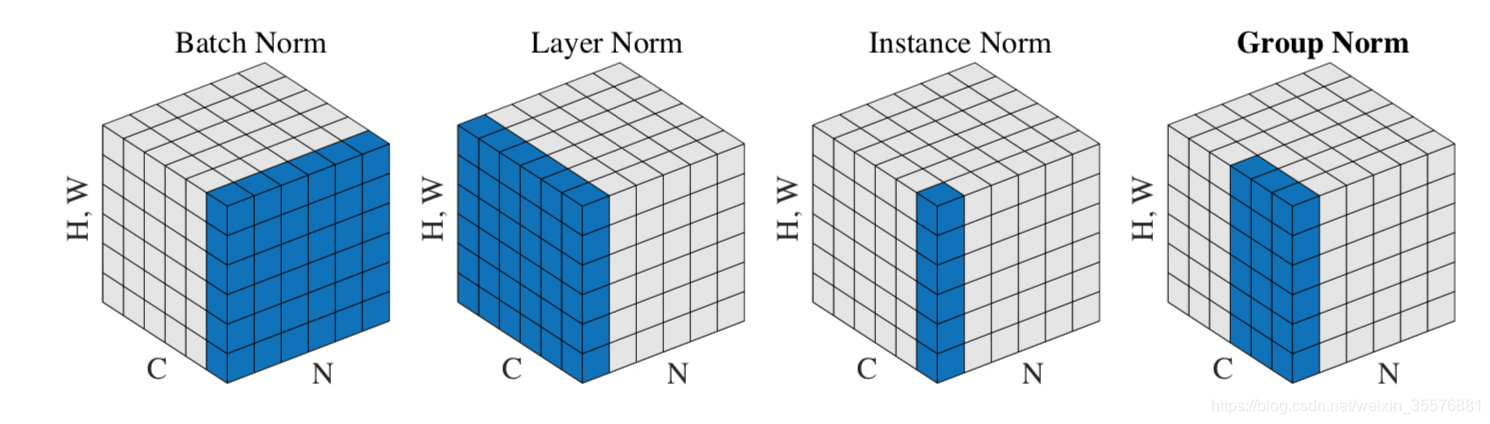
下图为特征图张量,可以直观看出BN,LN,IN,GN等规范化方法的区别。N为样本维度,C为通道维度,H为height,W即width,代表特征图的尺寸。
IN
IN对每个样本在每个通道进行规范化,x为特征图,减去均值,除以标准差,规范化后分布均值为0,方差为1。在进行缩放和平移(仿射变换),仿射参数通过反向传播学习。
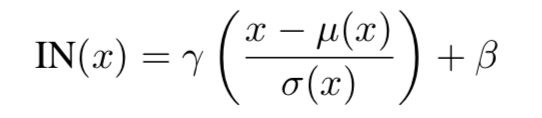
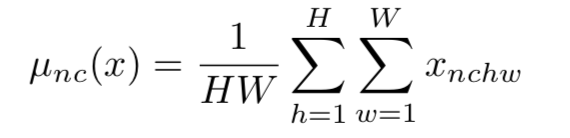
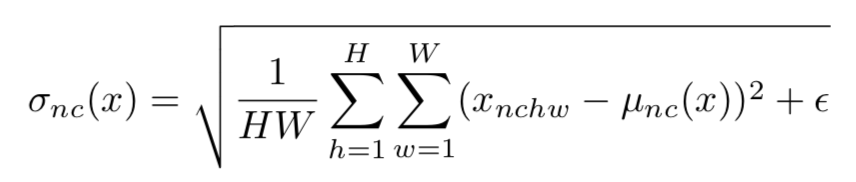
AdaIN
AdaIN和IN的不同在于仿射参数来自于样本,即作为条件的样本,也就是说AadIN没有需要学习的参数,这和BN,IN,LN,GN都不同。
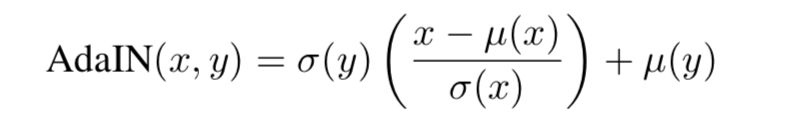
经过实验研究,风格转换中的风格与IN中的仿射参数有很大关系,AdaIN扩展了IN的能力,使用风格图像的均值和标准差作为仿射参数,基于这样一个假设:给定任意的仿射参数能够合成具有任意风格的图像。
实验证实在few-shot image-to-image translation,voice conversion,image style transfer等任务上,AdaIN确实能够实现任意的风格转换。
论文
Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
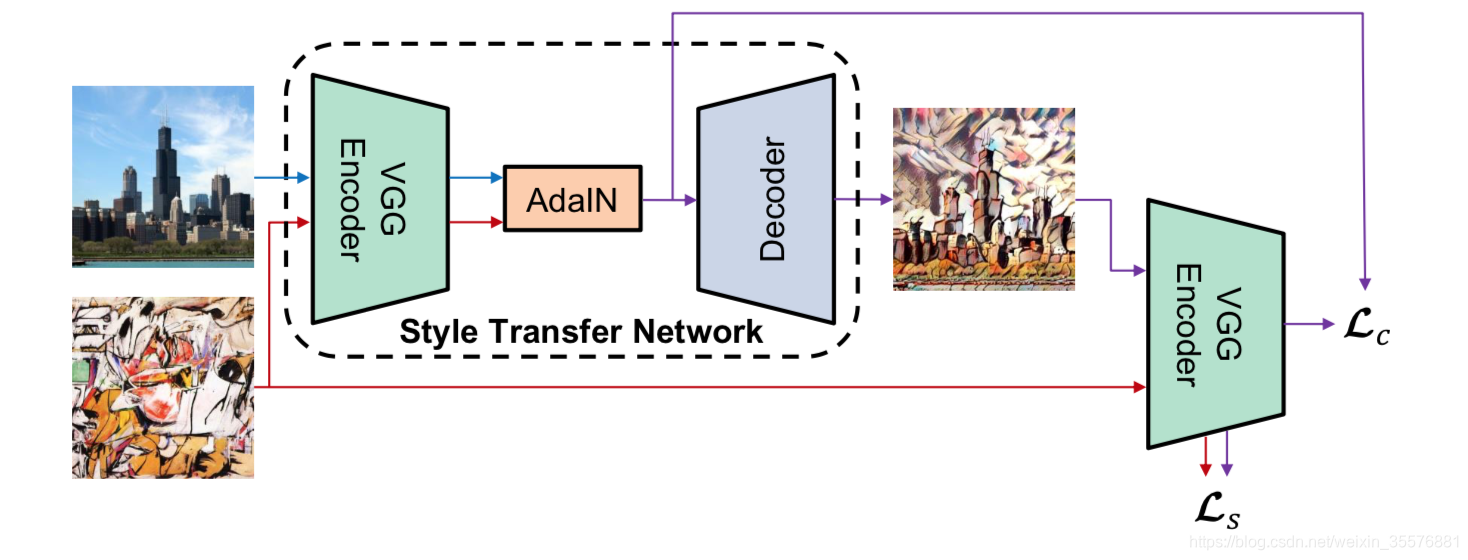
文中使用VGG-19来编码内容和风格,固定编码器,在潜层空间将特征图通过AdaIN层,在其中进行上述仿射变换,解码器根据变换后的特征图试图重建图像,通过反向传播训练解码器,使得解码器输出越来越真实的图像。
代码
import torch
def calc_mean_std(feat, eps=1e-5):
# eps is a small value added to the variance to avoid divide-by-zero.
size = feat.size()
assert (len(size) == 4)
N, C = size[:2]
feat_var = feat.view(N, C, -1).var(dim=2) + eps
feat_std = feat_var.sqrt().view(N, C, 1, 1)
feat_mean = feat.view(N, C, -1).mean(dim=2).view(N, C, 1, 1)
return feat_mean, feat_std
#AadIN
def adaptive_instance_normalization(content_feat, style_feat):
assert (content_feat.size()[:2] == style_feat.size()[:2])
size = content_feat.size( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5204
5204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









