






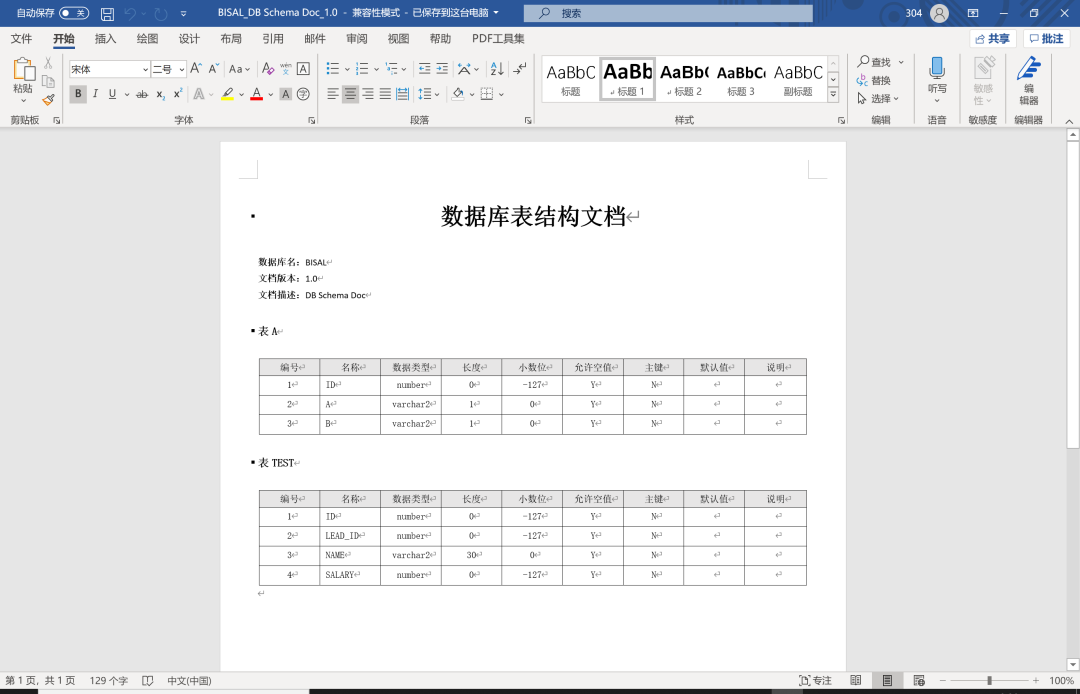
之前我们每次的数据库变更,都会增量更新我们的数据库文档,如下所示,便于从文档中了解数据库结构,
但是自从我们开始使用自研的数据库变更管控平台,每次变更都会记录到系统中,因此不再手动更新这个文档。可最近同事因为项目需求,需要一个最新的数据库文档,这可有些为难了,难道要回溯每次变更,手工加到这个文档中?
其实不然,这个问题,可能有很多技术解决方式,例如用PowerDesigner,可以反向生成数据库文档,可参考《PowerDesigner逆向工程导出pdm》。还可以自己写个程序,读取user_tables、user_indexes、user_constraints等视图,构建一个数据库文档,曾经为了比对两个数据库结构,写过一个生成pdf格式的程序,列出table、index、constraint等的不同,用的就是这种。
无意中从git上找到了一个契合此需求的项目,叫做screw,他是一个数据库表结构文档生成工具。

作者的解释,是不是和我们的日常状态非常相像?
关于数据库表结构文档状态:要么没有、要么有、但都是手写、后期运维开发,需要手动进行维护到文档中,很是繁琐、如果忘记一次维护、就会给以后工作造成很多困扰、无形中制造了很多坑留给自己和后人。
关于名字,想一个太难了,好在我这个聪明的小脑瓜灵感一现,怎么突出它的小,但重要呢?从小就学过雷锋的螺丝钉精神,摘自雷锋日记:虽然是细小的螺丝钉,是个细微的小齿轮,然而如果缺了它,那整个的机器就无法运转了,慢说是缺了它,即使是一枚小螺丝钉没拧紧,一个小齿轮略有破损,也要使机器的运转发生故障的...,感觉自己写的这个工具,很有这意味,虽然很小、但是开发中缺了它还不行,于是便起名为screw(螺丝钉)。
https://github.com/pingfangushi/screw
他的特点很鲜明,
1. 简洁、轻量、设计良好。代码量很少,从如下示例,可以体会一下。
2. 多数据库支持。目前支持MySQL、MariaDB、TIDB、Oracle、SqlServer 、PostgreSQL、Cache DB,在开发中的,包括H2、DB2、HSQL 、SQLite、瀚高、达梦、虚谷、人大金仓,可以看到,不仅有主流商业数据库,还支持很多国产数据库。
3. 多种格式文档。目前支持html格式、word格式、md格式。
4. 灵活扩展。可以自行选择导出的数据库对象。
5. 支持自定义模板。可以根据需求,定制自己的数据库导出逻辑。
不多说了,直接上代码,创建一个maven工程,首先要在pom中引入依赖,
cn.smallbun.screwscrew-core${lastVersion} com.zaxxerHikariCP3.4.5//需要连接的数据库driver接下来可以参照这个,定制自己的逻辑,有几点可以说下,
1. 示例用的Oracle,可以改成其他的数据库连接。
2. 可以使用ignore*方法过滤不需要导出的表或者指定需要导出的表,支持完整表名、前缀、后缀等形式。
package com.swagger.Swagger;import java.util.ArrayList;import com.zaxxer.hikari.HikariDataSource;import cn.smallbun.screw.core.Configuration;import cn.smallbun.screw.core.engine.EngineConfig;import cn.smallbun.screw.core.engine.EngineFileType;import cn.smallbun.screw.core.engine.EngineTemplateType;import cn.smallbun.screw.core.execute.DocumentationExecute;import cn.smallbun.screw.core.process.ProcessConfig;public class ScrewApplicationTest {public static void main(String args[]) {new ScrewApplicationTest().documentGeneration(); }void documentGeneration() {//配置 - 数据源 HikariDataSource ds = new HikariDataSource(); ds.setJdbcUrl("jdbc:oracle:thin:@//x.x.x.x:1523/user"); ds.setUsername("user"); ds.setPassword("password"); ds.setDriverClassName("oracle.jdbc.driver.OracleDriver"); ds.setSchema("user"); //配置 - 输出文件String fileOutputDir = "D:\\doc"; EngineConfig engineConfig = EngineConfig.builder()//生成文件路径 .fileOutputDir(fileOutputDir)//打开目录 .openOutputDir(true)//文件类型 .fileType(EngineFileType.WORD)//生成模板实现 .produceType(EngineTemplateType.freemarker)//自定义文件名称 .fileName("test_file") .build();//配置 - 读取哪些数据表 ArrayList ignoreTableName = new ArrayList<>(); ignoreTableName.add("test_user"); ArrayList ignorePrefix = new ArrayList<>(); ignorePrefix.add("test_"); ArrayList ignoreSuffix = new ArrayList<>(); ignoreSuffix.add("_test"); ArrayList tablePrefix = new ArrayList<>(); tablePrefix.add("T_"); ProcessConfig processConfig = ProcessConfig.builder()//指定生成逻辑、当存在指定表、指定表前缀、指定表后缀时,将生成指定表,其余表不生成、并跳过忽略表配置//根据名称指定表生成// .designatedTableName(new ArrayList<>())//根据表前缀生成 .designatedTablePrefix(tablePrefix)//根据表后缀生成 .designatedTableSuffix(new ArrayList<>())//忽略表名 .ignoreTableName(ignoreTableName)//忽略表前缀 .ignoreTablePrefix(ignorePrefix)//忽略表后缀 .ignoreTableSuffix(ignoreSuffix) .build(); Configuration config = Configuration.builder()//版本 .version("1.0.0")//描述 .description("DB Schema Doc")//数据源 .dataSource(ds)//生成配置 .engineConfig(engineConfig)//生成配置 .produceConfig(processConfig) .build();//执行生成 System.out.println("start");new DocumentationExecute(config).execute(); System.out.println("end"); }}忽略网络因素,执行起来的速度还是很快的,格式很清晰。
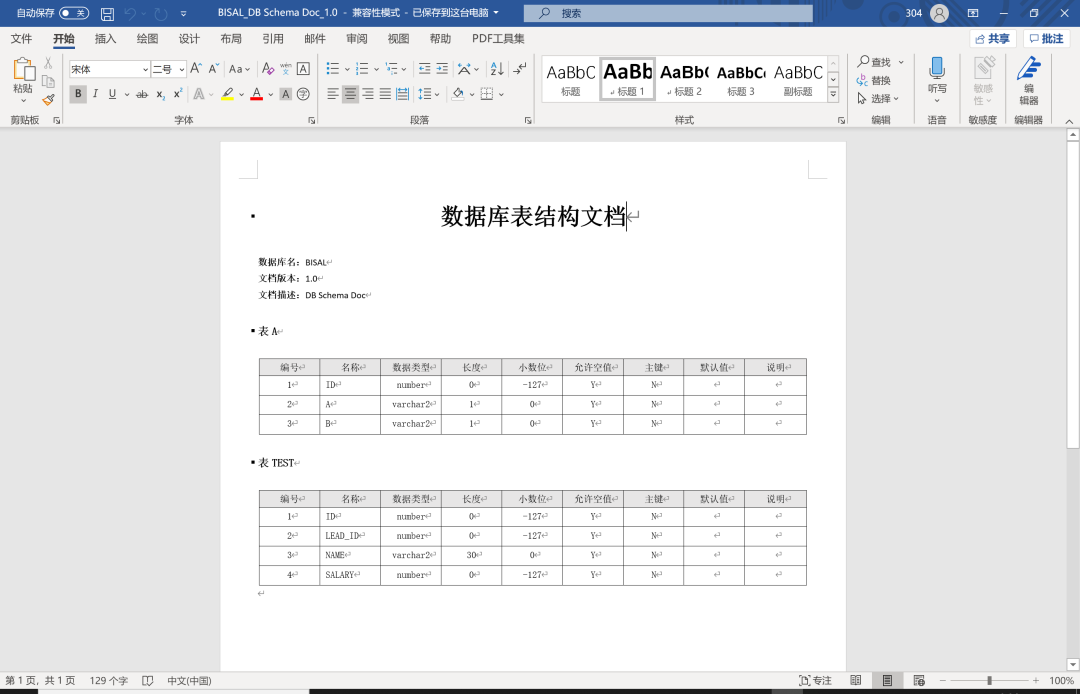
word格式,
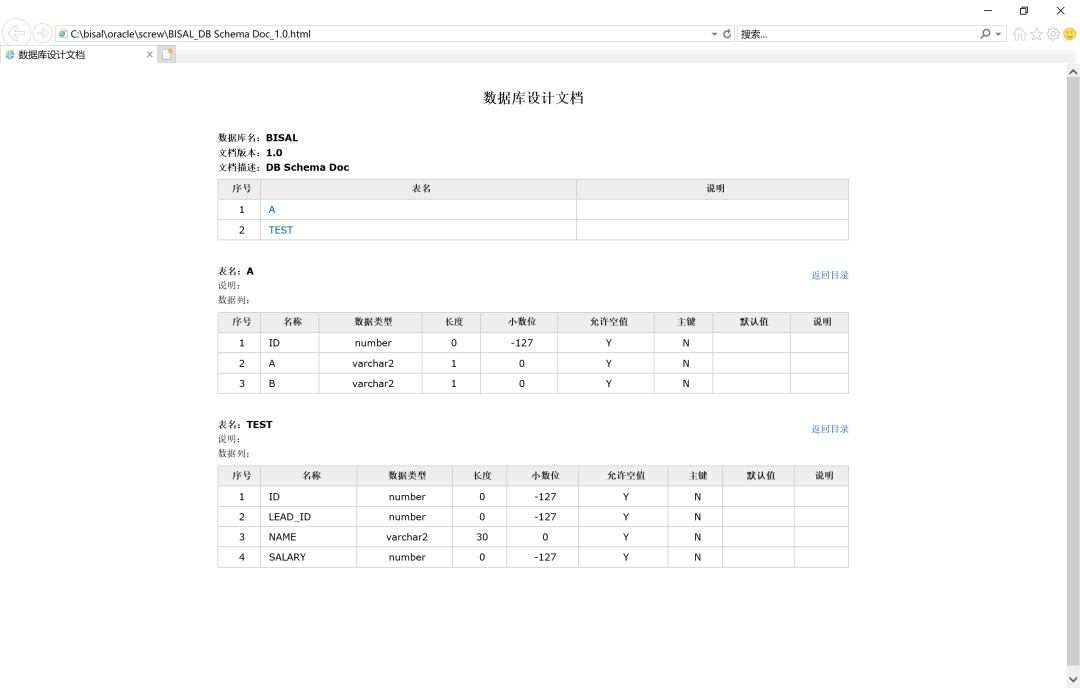
html格式,支持超链接,
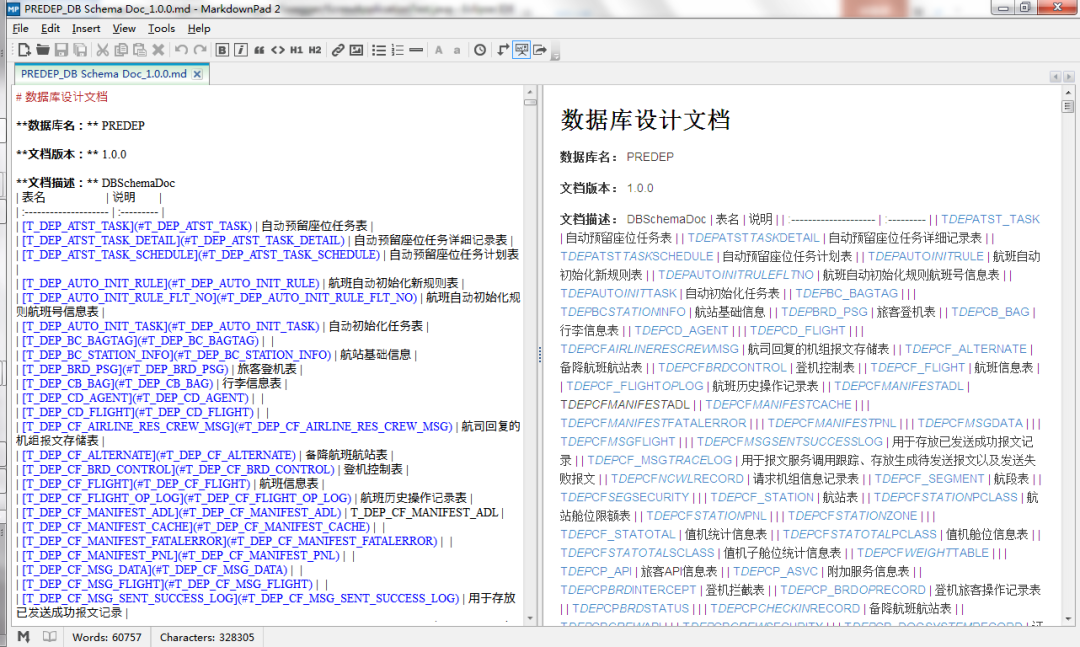
md格式,
转文至此。
正如作者所说,这个工具,很有意味,虽然很小,但是开发中缺了他还不行,这就是技术的意义所在,解决我们日常的点点滴滴,实现工作生活的价值。

欢迎关注个人微信公众号“一森咖记”

近期热文
你可能也会对以下话题感兴趣。点击链接便可查看。
为什么不建议把数据库部署在docker容器内?
MySQL数据延迟跳动的问题分析
MySQL 5.6和 5.7_同步账号修改密码方式:真的不一样
MySQL8.0 为嘛弃用Query Cache?
你应该知道的分布式系统之奠基石CAP理论
MySQL数据延迟跳动的问题分析
如何判断一个应用系统性能好不好?
MySQL Document Store 混合使用关系型数据与非关系型数据
分布式一致性算法:Paxos算法学习
MySQL 中你不得不知的重要知识点
神技_如何快捷下载Oracle补丁的方法?!
趋势篇:oracle 11g,12c,18c,19c之support lifetime
Centos能不能替换RHEL?
Centos能不能替换RHEL?
年末总结_聊一聊数据库行业的“继往开来”
【干货篇】在国内外数据库百家争鸣的时代,DBA们该何去何从?
实操:12C RAC环境下的ADG同步库搭建
浅谈MySQL三种锁:全局锁、表锁和行锁














 2474
2474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









