







索引本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。索引的主要的功能就是加速查找。
一、mysql的常见索引
普通索引INDEX:加速查找
唯一索引:-主键索引PRIMARY KEY:加速查找+约束(不为空、不能重复)-唯一索引UNIQUE:加速查找+约束(不能重复)
联合索引:-PRIMARY KEY(id,name):联合主键索引-UNIQUE(id,name):联合唯一索引-INDEX(id,name):联合普通索引
除此之外还有全文索引,即FULLTEXT,但其实对于全文搜索,我们并不会使用MySQL自带的该索引,而是会选择第三方软件如Sphinx,专门来做全文搜索。
二、索引类型
索引主要包括hash和btree两大类型,我们在创建索引时可以为其指定索引类型。其中hash类型的索引:查询单条快,范围查询慢;btree类型的索引:b+树,层数越多,数据量指数级增长(我们就用它,因为innodb默认支持它)。
#不同的存储引擎支持的索引类型也不一样
InnoDB 支持事务,支持行级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
MyISAM 不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
Memory 不支持事务,支持表级别锁定,支持 B-tree、Hash 等索引,不支持 Full-text 索引;
NDB 支持事务,支持行级别锁定,支持 Hash 索引,不支持 B-tree、Full-text 等索引;
Archive 不支持事务,支持表级别锁定,不支持 B-tree、Hash、Full-text 等索引;
三、创建与删除索引
1、在创建表时创建索引
create table t1(
id int,
name char(5),
age int;
unique key uni_name(name),#uni_name为索引名
index index_age(age), #index_age为索引名,不需要key
primary key(id) #primary不需要起索引名,起了也不会显示
);
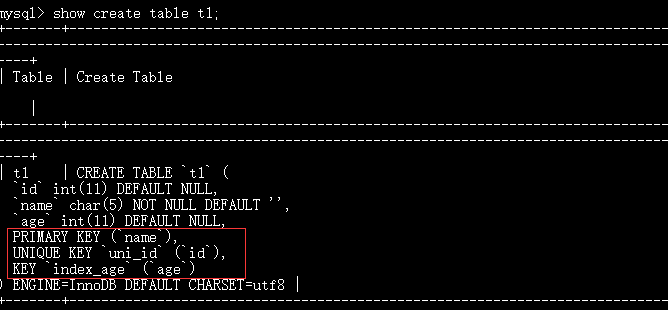
2、创建完表后为其添加索引
create table t3(
id int,
name char(5),
age int
);
create index indx_name on t3(name);#常用
alter table t3 add index indx_id(id);
alter table t3 add primary key(age);
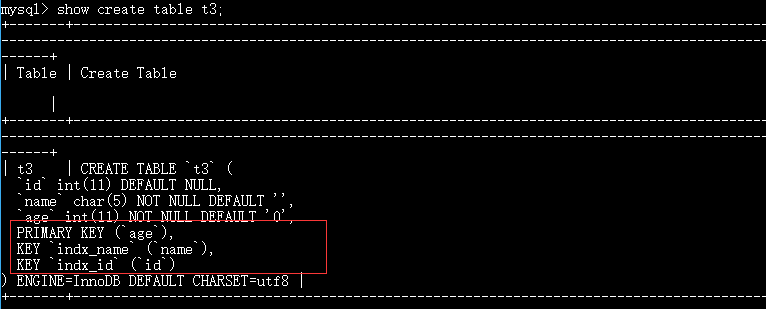
3、删除索引
drop index indx_id on t3;
alter table t3 drop primary key;
上述第一个删除语法中,因primary key 没有名字,所以删除方式为:drop index ‘primary’ on t3,其他有名字的索引删除方式为:drop index 索引名 on 表名
四、测试索引
按照如下sql语句创建表s1,后续所有测试均基于此表:
#1. 准备表
create table s1(
id int,
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









