






WMD简介
词移距离(Word Mover’s Distance)

更多内容:
WMD MATLAB代码
注意emd_mex是调用搬土距离的库Earth Mover’s Distance
MATLAB
%徐奕 E21614061
clc
clear
tic;
load_file = 'bbcsport.mat'; % 数据集为bbcsport
save_file = 'wmd_d_bbcsport.mat';
%X每个单元对应一个文档,是一个[d,u]矩阵,
%其中d是嵌入单词的维数bbcsport中的是300,u是该文档中Unique单词的数量
%每一列是特定单词的word2vec向量。
%Y是文档的标签
%BOW_X单元阵列中的每个单元格都是与文档对应的向量。
%向量的大小是文档中Unique单词的数量,每个条目是每个Unique单词出现的频率。
%indices 每个单元格对应于一个文档,它本身就是一个{1,u}单元格,其中每个条目是对应于每个Unique单词的实际单词
%TR每一行对应于训练集的随机分割,每个条目是相对于完整数据集的索引。
load(load_file)
docNum = length(BOW_X); %文档的数量
WMD = zeros(docNum,docNum);
parfor i = 1:docNum %并行运行
E_distance = zeros(1,docNum); %用来存放当前文档与其他文档的距离
for j = (i+1):docNum
if isempty(BOW_X{i}) || isempty(BOW_X{j})
E_distance(j) = Inf; % 错误处理
else
x1 = BOW_X{i}./sum(BOW_X{i}); %归一化
x2 = BOW_X{j}./sum(BOW_X{j}); %归一化
%%% 求欧式距离
D = distance(X{i}, X{j}); %计算两个文档间的距离(计算X{i}和{j}中的任意列向量之间的两两平方距离矩阵)
D(D < 0) = 0; %设置下限
D = sqrt(D); %开方
[emd,flow]=emd_mex(x1,x2,D); %调用搬土距离的库Earth Mover's Distance,求WMD
E_distance(j) = emd;
end
end
WMD(i,:) = E_distance; %存放到外部变量
end
%% 根据距离矩阵计算相似度,使用归一化
similarVar = -WMD;
maxs = max(similarVar);
mins = min(similarVar);
for i = 1:size(WMD,1)
for j = 1:length(WMD(i,:))
similarVar(i,j) = (similarVar(i,j)-mins)/(maxs-mins);
end
end
toc
%% 保存数据与文件
save('wmd_sim',similarVar);
save(save_file,'WMD');
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
%徐奕E21614061
clc
clear
tic;
load_file='bbcsport.mat';% 数据集为bbcsport
save_file='wmd_d_bbcsport.mat';
%X每个单元对应一个文档,是一个[d,u]矩阵,
%其中d是嵌入单词的维数bbcsport中的是300,u是该文档中Unique单词的数量
%每一列是特定单词的word2vec向量。
%Y是文档的标签
%BOW_X单元阵列中的每个单元格都是与文档对应的向量。
%向量的大小是文档中Unique单词的数量,每个条目是每个Unique单词出现的频率。
%indices每个单元格对应于一个文档,它本身就是一个{1,u}单元格,其中每个条目是对应于每个Unique单词的实际单词
%TR每一行对应于训练集的随机分割,每个条目是相对于完整数据集的索引。
load(load_file)
docNum=length(BOW_X);%文档的数量
WMD=zeros(docNum,docNum);
parfori=1:docNum%并行运行
E_distance=zeros(1,docNum);%用来存放当前文档与其他文档的距离
forj=(i+1):docNum
ifisempty(BOW_X{i})||isempty(BOW_X{j})
E_distance(j)=Inf;% 错误处理
else
x1=BOW_X{i}./sum(BOW_X{i});%归一化
x2=BOW_X{j}./sum(BOW_X{j});%归一化
%%% 求欧式距离
D=distance(X{i},X{j});%计算两个文档间的距离(计算X{i}和{j}中的任意列向量之间的两两平方距离矩阵)
D(D<0)=0;%设置下限
D=sqrt(D);%开方
[emd,flow]=emd_mex(x1,x2,D);%调用搬土距离的库Earth Mover's Distance,求WMD
E_distance(j)=emd;
end
end
WMD(i,:)=E_distance;%存放到外部变量
end
%% 根据距离矩阵计算相似度,使用归一化
similarVar=-WMD;
maxs=max(similarVar);
mins=min(similarVar);
fori=1:size(WMD,1)
forj=1:length(WMD(i,:))
similarVar(i,j)=(similarVar(i,j)-mins)/(maxs-mins);
end
end
toc
%%保存数据与文件
save('wmd_sim',similarVar);
save(save_file,'WMD');
RWMD(Relaxed word moving distance )
先去掉一个约束,计算相应的WMD,最终取最大值。
这两个 relax 过的优化问题的解,恰好对应于词向量矩阵的行空间和列空间上的最近邻问题,也是很好算的。最后定义 RWMD 为这两个 relaxed 优化问题的两个目标值中的最大值。
RWMD MATLAB代码
本代码不需要任何外部包
MATLAB
%徐奕 E21614061
clc
clear
tic;
addpath('emd')
load_file = 'bbcsport.mat'; % 数据集为bbcsport
save_file = 'rwmd_bbcsport.mat';
load(load_file)
%X每个单元对应一个文档,是一个[d,u]矩阵,
%其中d是嵌入单词的维数bbcsport中的是300,u是该文档中Unique单词的数量
%每一列是特定单词的word2vec向量。
%Y是文档的标签
%BOW_X单元阵列中的每个单元格都是与文档对应的向量。
%向量的大小是文档中Unique单词的数量,每个条目是每个Unique单词出现的频率。
%indices 每个单元格对应于一个文档,它本身就是一个{1,u}单元格,其中每个条目是对应于每个Unique单词的实际单词
%TR每一行对应于训练集的随机分割,每个条目是相对于完整数据集的索引。
docNum = length(BOW_X); % 读取文档的数量
RWMD = zeros(docNum,docNum); % 最终的生成矩阵
parfor i = 1:docNum %并行运行
E_distance = zeros(1,docNum); % 计算单个文档与其他文档的距离
for j = (i+1):docNum
if isempty(BOW_X{i}) || isempty(BOW_X{j}) % 错误处理
E_distance(j) = Inf;
else
x1 = BOW_X{i}./sum(BOW_X{i}); % 归一化
x2 = BOW_X{j}./sum(BOW_X{j}); % 归一化
DD = distance(X{i}, X{j}); % 计算两个文档间的距离(计算X{i}和{j}中的任意列向量之间的两两平方距离矩阵)
m1 = sqrt(max(min(DD,[],1),0));
m2 = sqrt(max(min(DD,[],2),0));
dist1 = m1*x2'; % 只保留约束1
dist2 = m2'*x1'; % 只保留约束2
E_distance(j) = max(dist1,dist2); % 根据论文,对于RWMD,需要选择两个目标中最大的值
end
end
RWMD(i,:) = E_distance; %存储
fprintf("doc %d done!\n",i);
end
RWMD = RWMD + RWMD'; % 上三角加上下三角
%% 根据距离矩阵计算相似度,归一化
similarVar = -RWMD;
maxs = max(similarVar);
mins = min(similarVar);
for i = 1:size(RWMD,1)
for j = 1:length(RWMD(i,:))
similarVar(i,j) = (similarVar(i,j)-mins)/(maxs-mins);
end
end
%% 保存数据与文件
toc;
save(save_file,'RWMD');
save('rwmd_sim', 'similarVar');
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
%徐奕E21614061
clc
clear
tic;
addpath('emd')
load_file='bbcsport.mat';% 数据集为bbcsport
save_file='rwmd_bbcsport.mat';
load(load_file)
%X每个单元对应一个文档,是一个[d,u]矩阵,
%其中d是嵌入单词的维数bbcsport中的是300,u是该文档中Unique单词的数量
%每一列是特定单词的word2vec向量。
%Y是文档的标签
%BOW_X单元阵列中的每个单元格都是与文档对应的向量。
%向量的大小是文档中Unique单词的数量,每个条目是每个Unique单词出现的频率。
%indices每个单元格对应于一个文档,它本身就是一个{1,u}单元格,其中每个条目是对应于每个Unique单词的实际单词
%TR每一行对应于训练集的随机分割,每个条目是相对于完整数据集的索引。
docNum=length(BOW_X);% 读取文档的数量
RWMD=zeros(docNum,docNum);% 最终的生成矩阵
parfori=1:docNum%并行运行
E_distance=zeros(1,docNum);% 计算单个文档与其他文档的距离
forj=(i+1):docNum
ifisempty(BOW_X{i})||isempty(BOW_X{j})% 错误处理
E_distance(j)=Inf;
else
x1=BOW_X{i}./sum(BOW_X{i});% 归一化
x2=BOW_X{j}./sum(BOW_X{j});% 归一化
DD=distance(X{i},X{j});% 计算两个文档间的距离(计算X{i}和{j}中的任意列向量之间的两两平方距离矩阵)
m1=sqrt(max(min(DD,[],1),0));
m2=sqrt(max(min(DD,[],2),0));
dist1=m1*x2'; % 只保留约束1
dist2 = m2'*x1'; % 只保留约束2
E_distance(j) = max(dist1,dist2); % 根据论文,对于RWMD,需要选择两个目标中最大的值
end
end
RWMD(i,:) = E_distance; %存储
fprintf("doc %d done!\n",i);
end
RWMD = RWMD + RWMD';% 上三角加上下三角
%% 根据距离矩阵计算相似度,归一化
similarVar=-RWMD;
maxs=max(similarVar);
mins=min(similarVar);
fori=1:size(RWMD,1)
forj=1:length(RWMD(i,:))
similarVar(i,j)=(similarVar(i,j)-mins)/(maxs-mins);
end
end
%%保存数据与文件
toc;
save(save_file,'RWMD');
save('rwmd_sim','similarVar');
上述两个代码的distance函数
MATLAB
function dist=distance(X,x)
% dist=distance(X,x)
% 计算X和中的任意列向量之间的两两平方距离矩阵
[D,~] = size(X);
if(nargin>=2)
[d,~] = size(x);
if(D~=d)
error('注意维度要相等!\n');
end
X2 = sum(X.^2,1);
x2 = sum(x.^2,1);
dist = bsxfun(@plus,X2.',bsxfun(@plus,x2,-2*X.'*x));
else
[D,N] = size(X);
s=sum(X.^2,1);
dist=bsxfun(@plus,s',bsxfun(@plus,s,-2*X.'*X));
end
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
functiondist=distance(X,x)
%dist=distance(X,x)
%计算X和中的任意列向量之间的两两平方距离矩阵
[D,~]=size(X);
if(nargin>=2)
[d,~]=size(x);
if(D~=d)
error('注意维度要相等!\n');
end
X2=sum(X.^2,1);
x2=sum(x.^2,1);
dist=bsxfun(@plus,X2.',bsxfun(@plus,x2,-2*X.'*x));
else
[D,N]=size(X);
s=sum(X.^2,1);
dist=bsxfun(@plus,s',bsxfun(@plus,s,-2*X.'*X));
end
数据集来源
结果
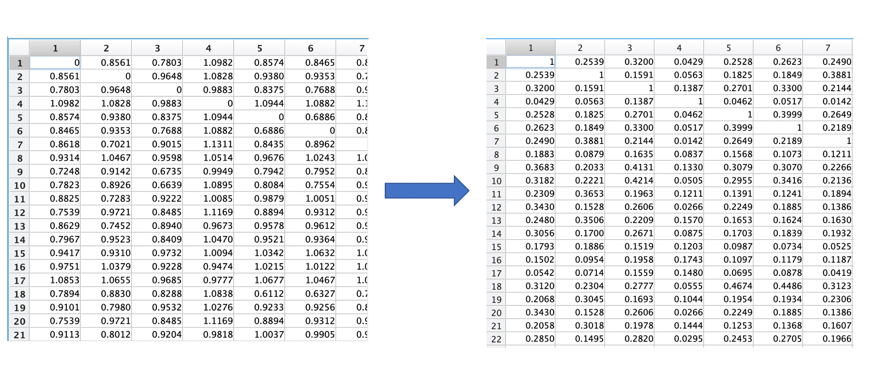
生成的WMD距离矩阵(左),归一化后可以转化为相似度矩阵(右)
结果举例:找出的相似的两个文本,下面的相似度为47.78%(与文档1最相似)

其中用不同颜色标注的是有明显相似特征的句子。
分析
通过下面的文档相似度矩阵可以发现,文档与文档间的相似度较小,这是因为数据集是真实世界的数据集,即BBC SPORT中没有两篇完全一样的报道。另外,BBC SPORT共有5个不同的类别,从实验结果可以看到相同类别间的相似度远远大于不同类别间的相似度,因此,WMD对文本分类是有一定的效果。
另外从作者的论文中实验结果可以看到,基于KNN的词移距离算法相对于大多数其他主流文本相似度分析算法来说,错误率要少很多,因此,在工业界,使用WMD来做NLP处理是非常有前景的。
最后,根据由于WMD是无监督学习,通过有监督学习的论文(Supervised word mover’s distance)中可以发现,加上了监督机制后错误率还能再下降一个层次。
需要指出的是,不能简单地添加基于度量学习的监督矩阵,一方面,在计算过程中梯度可能不存在,另一方面,基于KNN的SWMD将会耗费大量的时间,因此需要采取相关措施来解决这些问题。
SWMD简介:
参考资料
Kusner M, Sun Y, Kolkin N, et al. From word embeddings to document distances[C]//International Conference on Machine Learning. 2015: 957-966.














 906
906











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









