







字体基础
\1. 安装字体命令
yum -y install fontconfig
\2. 查看已安装字体
(1) 查看linux已安装字体
fc-list
(2) 查看安装的中文字体
fc-list :lang=zh
\3. 安装需要的字体
(1) 创建目录
mkdir -p /usr/share/fonts/my_fonts
(2) 将要安装的字体上传到该文件夹下
(3) 获取相关字体,以 windows 为例上传到刚刚创建的文件夹下
进入C:\Windows\Fonts,该文件夹下就存放相关字体,将需要字体拷贝到linux 目录/usr/share/fonts/my_fonts下即可
(4) 安装字体索引指令
yum install mkfontscale
(5) 生成字体索引
mkfontscale
(6) 查看是否安装成功
fc-list :lang=zh
字体反爬虫
反爬虫和爬虫之间的较量已经争斗多年,不管是攻还是守,已经持续N年,这是一个没有硝烟的战场,大家都知道爬虫和反爬之家的道高一尺魔高一丈的关系。但这个方案可以很大程度上可以增加普通爬虫的采集成本,在不使用OCR的前提下,算是比较极致的方案了。当然方案有很多种,层出不穷的各种方法,这里介绍的时候反爬虫的中的一种比较实用的方案,字体反爬也就是自定义字体反爬通过调用自定义的ttf文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容!必须通过程序去处理才能达到采集成本。
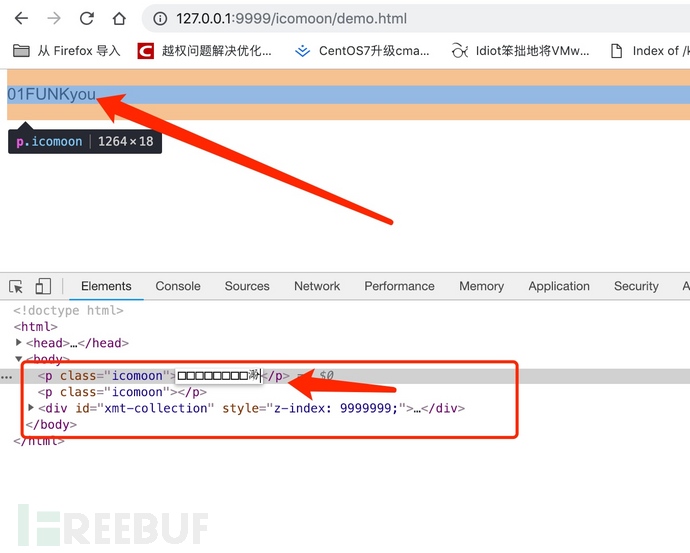
效果展示!
思路
细心的人会问,为什么不把所有的内容都替换成编码呢?这个就涉及到加载和渲染速度的问题。还有如果启动字体反爬虫,基本上已经告别SEO了,请仔细考虑中间的厉害关系,你懂得!
我们知道,单纯汉字就有好几千个,还有各种字符,有的还包含各种外国人的字符串!如果全部放到自定义字体库中的话,这个文件灰常大,几十兆是肯定有的了,那后果啥样就很清楚了,加载肯定很慢,更糟糕的是如此之多的字体需要浏览器去渲染,那效果,卡到爆!!!
为了解决这个问题,我们可以选择只渲染少量的、部分的文字,假设50个字,那么字体库就会小到几十K了,相当于一个小图片而已,加上CDN加速之类的,解决了。具体网络上又N种方法参考方法我会贴在下面!
如此简单?50个字儿呢可不是随便随便选择的,要选择那些爬虫采集不到就会很大改变整个语句的语义的词,直接点吧,也就是量词、否定词之类的。如原文“我有一头朱佩琪,我从来都不骑”,我们把其中的“一”、“不”放到我们
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1627
1627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









