






之前听说过高性能的分布式缓存开源工具,但一直没有真正接触过,如今接触的产品中实用到过分布式缓存。所以决定一探到底。memcached是一个优秀的开源的分布式缓存工具。也是眼下比較火热的分布式缓存的解决方式雏形。memcached的服务端产品本身功能简洁,简单易用。可是玩法多种多样。可是其实它是一个“伪分布式”解决方式。它本身并没有实现服务端分布式(服务端的memcached
server之间是不能通信的),所谓的分布式都是依靠client来实现,而眼下市面上提供了client分布式实现的开源工具非常多,在这里我主要以Spymemcached这个client实现为基础讲述一些memcached的原理和应用。
【原理说明】
之前提到了,memcached产品本身并未实现分布式,所以借助下列两幅网上流行的图片便能够直观的了解memcached的原理以及怎么玩分布式的。
1、存储(set)
如果memcached server有node1/node2/node3三个节点,如今应用程序须要存储"tokyo"/"test"这样一对键值对。memcachedclient接收应用程序传来的键值对"tokyo"/"test",通过算法(文章尾部会介绍详细的算法细节)从server列表中选中了node1作为目标存储server。接着发送set指令命令node1运行存储任务。

图1 存储数据
2、获取(get)
如果应用程序如今须要获取键"tokyo"相应的值数据"test",memcachedclient程序接收參数"tokyo",通过相同的算法从server列表中选中node1,接着发送get指令命令node1获取键"tokyo"相应的值数据。

图2 获取数据
【使用场景】
在网上也看过一些前辈描写叙述过一些关于使用场景的描写叙述,我简单总结下大致就下面两点
1、从memcached设计初衷的角度来看,memcached能够降低站点数据库的开销。对于常常须要读取,而又不常常改变的数据全然能够放到memcached中。
2、分布式应用之间共享数据。举个样例,登陆系统和商品查询系统是独立部署,而且是集群的。用户登陆了登陆系统之后怎样将登录信息与其它的业务系统(商品查询系统)共享信息,这时就能够使用memcached缓存登录信息。商品查询系统便能够从memcached中获取用户的登陆信息。
【client源代码分析】
1、client调用
以Spymemcachedclient实现为例。以下贴一段client的简单应用代码。下载链接memcached client
package com.lvmama.memcached;
import java.net.InetSocketAddress;
import net.spy.memcached.MemcachedClient;
public class TestSpymemcached {
public static void main(String[] args) throws Exception{
MemcachedClient client = new MemcachedClient(new InetSocketAddress("127.0.0.1", 11211)); //创建连接
client.set("name", 10, "tony"); //set数据
Object name = client.get("name"); //get数据
System.out.println("name:" + name);
}
}
2、余数hash算法
实现类为ArrayModNodeLocator,将传入的參数k(键)。通过hash算法得出一个整数值,计算下memcached server的个数。拿着參数k的hash值对server节点的个数求余数。余数便是选中的server节点。
public MemcachedNode getPrimary(String k) {
return nodes[getServerForKey(k)];
}
private int getServerForKey(String key) {
int rv = (int) (hashAlg.hash(key) % nodes.length);
assert rv >= 0 : "Returned negative key for key " + key;
assert rv < nodes.length : "Invalid server number " + rv + " for key "
+ key;
return rv;
}
3、consistent hash算法
算法原理见下图
第一步:将memcachedserver节点的hash值映射到一个0~2的32次方的环形数据结构上,存储方式为k(hash值),v(server节点);
第二步:将要保存的參数k计算hash值,并映射到环形数据结构中;
第三步:从參数k的hash值顺时针查找已映射的hash值,第一个hash值相应的server节点便是选中的目标存储server。
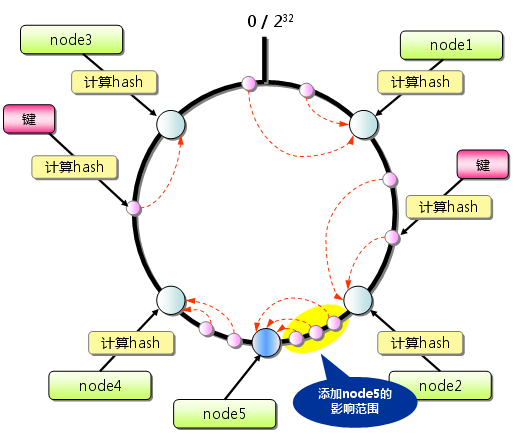
图 3 consistent hash算法
实现类为KetamaNodeLocator,代码结构比較简单:将要保存的k计算hash值作为參数传入getNodeForKey()方法,从hash值顺时针查找到剩余的环形数据结构tailMap。假设tailMap不为空则取tailMap中第一个已经映射hash值,假设tailMap为空则取整个环形数据结构ketamaNodes的第一个已经映射的hash值(从0開始),取得hash值便能够找到相应的memcachedserver节点。
public MemcachedNode getPrimary(final String k) {
MemcachedNode rv = getNodeForKey(hashAlg.hash(k));
assert rv != null : "Found no node for key " + k;
return rv;
}
MemcachedNode getNodeForKey(long hash) {
final MemcachedNode rv;
if (!ketamaNodes.containsKey(hash)) {
// Java 1.6 adds a ceilingKey method, but I'm still stuck in 1.5
// in a lot of places, so I'm doing this myself.
SortedMap tailMap = getKetamaNodes().tailMap(hash);
if (tailMap.isEmpty()) {
hash = getKetamaNodes().firstKey();
} else {
hash = tailMap.firstKey();
}
}
rv = getKetamaNodes().get(hash);
return rv;
}
4、算法优劣比較
余数hash算法:当server节点存在添加或者降低时,get数据时求得的余数同set数据时求得的余数非常可能就不是同一个值,这时便大大降低了缓存读取的命中率。
consistent hash算法:当server节点存在添加或者降低时,如图3添加了node5,仅仅有node2~node5之间的hash值会受到影响,由原来存储时命中的node4变成获取数据时命中的node5。其余hash值都不会受到影响。所以命中率较高。
并且有些consistent
hash算法的实现採用了虚拟节点的思想,使用一般的hash函数会使得server节点的映射分布的不均匀。因此能够为每一个物理server节点分配100~200虚拟映射点。这样便可最大限度的降低节点分布不均的情况发生。
初尝memcached,如有描写叙述有误,欢迎拍砖哈!兴许会写memcached服务端的内存模型。内存管理,源代码分析等文档,欢迎大家一起探讨!















 272
272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









