









文章目录
Redis分布式集群
redis支持集群架构。集群有主节点master和从节点slave。
slave通过复制技术,自动同步master的数据。
主从复制
redis主从复制分为2类,一种叫全量复制。第二种叫增量复制。
如果新加入的slave节点就需要全量复制。master通过bgsave命令在本地生成一个RDB快照发给slave节点。
如果salve之前有数据,则会被RDB的快照数据覆盖。
sentinel集群
redis的高可用是通过哨兵sentinel来保证的。
可以通过sentinel脚本启动,也可以用redis-server启动
eg:
./redis-sentinel ../sentinel.conf
或
./redis-server ../sentinel.conf --sentinel
它本质上只是一个运行在特殊模式下的Redis。

为了保证监控服务器的可用性,对sentinel也做集群部署。Sentinel即监控redis服务,Sentinel之间也相互监控。
注意:sentinel本身没有主从之分。只有Redis服务节点有主从之分。
哨兵机制的不足
主从切换中会丢失数据,因为只有一个master。
只能单点写入,没有水平扩展。
如果redis数据量很大,这时候需要对redis做分片存储。
Codis代理集群
Redis Cluster
跟codis不同的是,Redis cluster是一个去中心化的集群。
我们以3主3从为例,节点之间两两交互。

cluster数据分布
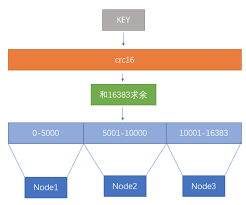
redis既没有用哈希取模,也没用一致性哈希,而是用虚拟槽实现的。
Redis创建了16384个槽(slot)。每个节点负责一定区间的slot。
Redis cluster特点
1、无中心架构
2、数据按照slot存储在多个节点,节点之间数据共享,可动态调整分布。
3、可扩展性,可先行扩展1000个节点。(官方推荐不超过1000个)
4、高可用,部分节点不可用,集群仍可用。
5、降低运维成本,提高扩展性和可用性。
Redis客户端
官网推荐3个客户端:Jedis、Redisson和Luttuce
Pipeline
我们平时说Redis是单线程的,说的是Redis的请求是单线程的,只有上一个命令的结果香型之后,下一个命令才会处理。
如果1次操作10万个key,客户端跟服务端就要交互10万次,排队时间加上网络时间就会慢的不得了。
举个例子,假设一次tcp交互的时间是1毫秒,客户端一秒钟也就最多发送1000个命令。怎么能做到10w的qps呢?
联想一下:kafka是怎么解决这个问题的?mysql是怎么解决的?
能否把一组命令组装在一起发给redis服务端执行?然后返回结果。这个就是Pipeline的作用。Pipeline通过一个队列把所有命令缓存起来,然后多个命令在一次连接中发送给服务器。
需要注意的是,并不是所有业务场景都要用Pipeline。
如果某些操作需要马上得到redis操作是否成功的结果,这种场景就不适合。
Lettuce
Lettuce克服了Jedis线程不安全的缺点。Springboot 2.X默认客户端就是Lettuce,替换了原来的Jedis。我们直接使用RedisTemplate操作即可。
Redisson
Spring可以配置和注入RedissonClient。在Redisson提供了更简单的分布式锁的实现。
数据一致性
1、如果缓存不存在,数据库存在。则直接从数据库拿数据,然后再写入缓存。这种情况不存在一致性问题。

2、如果redis缓存存在,应该从redis拿数据,不用访问数据库。这种情况下有可能数据库和缓存数据不一致。
一致性问题定义
我们始终要以数据库为准。一旦缓存数据发生变化的时候,我们既要操作数据库又要操作redis。
所以问题来了,我先操作数据库还是操作redis?
操作Redis,我们是删除key还是更新key?
在一般情况下,我们推荐使用删除key的方案。 这样可以避免数据库和缓存不一致的情况。
接下来我们对比第一个问题:
1)先更新数据库,再删除缓存。
1、更新数据库失败,程序捕获异常,不会走下一步。所以不会出现数据不一致。
2、更新数据库成功,删除缓存失败。数据库是新数据,缓存是旧数据,发生了数据不一致。
所以针对 2 的情况,我们需要捕获这个异常进行重试。
2)先删除缓存,再更新数据库
1、删除缓存失败,程序捕获到异常,不会走下一步,所以不会出现数据不一致。
2、删除缓存成功,更新数据库失败。因为以数据库的数据为准,所以也不会存在一致性问题。
这样看来貌似没问题。但是如果有并发的情况下:
1、线程A需要更新数据,首先删除了Redis缓存。
2、线程B查询数据,发现缓存不存在,到数据库查询旧值,写入redis。
3、线程A更新了数据库。
这个时候,redis是旧值,数据库是新值,发生了不一致的情况。
怎么办?删一次不保险。所以更新完数据库需要再删除一次。
高并发问题
在redis存储的所有数据中,有一部分是频繁访问的。会导致热点数据产生,处于存储和流量优化的角度,我们需要找出这些热点数据。
热点数据发现
除了LRU和LFU这些自动淘汰机制,怎么能够找出访问频率高的key呢?或者说,我们哪里在记录key被访问的情况呢?
1)客户端记录
我们在调用set和get方法时候,可以在Jedis的Connection类中sendCommand()方法里,用一个HashMap进行key的计数。
但是这种方式有风险:
1、会侵入客户端代码
2、不知道多少个key,key数量过多,可能会导致JVM内存泄漏。
2)服务端记录
redis有一个monitor命令,可以监控到所有redis执行的命令。
Facebook开源项目redis-faina就是基于monitor原理实现的。
这样做也有2个问题。
1)monitor命令在高并发场景下,会影响性能,所以不适合长时间使用。
2)只能统计一个redis节点的key。
3)机器层面统计
可以在机器层面,对TCP协议抓包分析。统计出热点key。
缓存雪崩
缓存雪崩就是大量redis热点数据同时失效(过期),因为设置了相同的过期时间。刚好这时候redis请求并发量很大,就会导致所有请求落到数据库。
缓存雪崩解决方案:
1)加互斥锁或者使用队列
2)缓存定时预先更新,避免同时失效
3)通过随机数,使key不在同一时间过期
4)缓存永不过期
缓存穿透
如果数据库和缓存都不存在这个数据,该怎么办?
1)缓存空数据
2)缓存特殊字符,如:&&。
如果是恶意请求,每次都生成一个符合ID规则的账号,但是这个账号在我们的数据库是不存在的,那么redis将会失去作用。
这个问题叫做缓存穿透。
eg:
如何在海量数据(例如 10亿 无序、不定长、不重复)快速判断一个元素是否存在?
如果是缓存穿透的问题,我们要避免数据库查询不存在的数据,肯定要把10亿的放在别的地方。
比如按照一个元素1字节的字段,10亿数据大概需要900G的内存空间,这对于普通的服务器来说是承受不了的。
所以我们不能直接存值,我们用位图来标记这个元素有没有出现,从而节省内存空间。
位图,是一个有序的数组,只有2个值,0和1。0代表不存在,1代表存在。
对于这个映射方法,我们有2个基本要求:
1)我们的值长度不固定,我希望不同长度的输入能够得到固定长度的输出。
2)转换成下标的时候,我希望在我的有序数组里面是分布均匀的,不然全挤到一块去了,我们就无法判断这个元素是否存在。
这就是哈希函数,比如常见的MD5。SHA-1等等都是常见哈希算法。

比如这6个元素,我们根据哈希函数和位运算,得到相应的下标。
那么问题来了,比如说我们存放100万个元素,到底需要多大的位图容量,需要多少个哈希函数呢?
布隆1970年发表了一篇论文,提出一个容器叫布隆过滤器。
布隆过滤器
布隆过滤器的本质是一个位数组,和若干个哈希函数。

集合里有3个元素,要把它放到布隆过滤器里面去。首先是a元素我们用了3次计算。b、c元素也一样。
现在我要判断一个元素,在这个容器里是否存在,就要使用三个函数进行计算。
如果3个位都是1,则说明大概率可能存在。
如果3个位,其中有一个位是0,那么这个元素一定不存在。
Guava的实现
谷歌的Guava里面就提供了一个现成的布隆过滤器。
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>21.0</version>
</dependency>
创建布隆过滤器:
String checkData(String data) {
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),10000000,0.00001);//0.0001代表误判率。
if(bloomFilter.mightContain(data)){//判断元素是否存在
return "true" ;
}else{
bloomFilter.put(data);//布隆过滤器添加元素
return "false" ;
}
}
位图的容量是基于元素个数和误判率计算出来的。
存储100万个元素只占了0.87M的内存,生成了5个哈希函数。
布隆过滤器在项目中的使用

因为要判断数据库的值是否存在,所以第一步是加在数据库所有的数据。在去redis查询之前,现在布隆过滤器查询,如果bloomfilter说没有,那数据库肯定就没有。也不用去查了。如果bloomfilter说有,才快开始走业务流程。
布隆过滤器的不足与变种
如果数据库delete一条记录,布隆过滤器也要删除一条数据。可是布隆过滤器不提供删除的方法。或者说如果删除了布隆过滤器元素会发生什么?

如果把a删除了,那么3个位置都要改成0。所以判断b元素的时候,b也不存在。因此元素只能存入,不能删除。
布隆过滤器应用场景
布隆过滤器解决的问题是什么?如何在海量元素中快速判断一个元素是否存在。除了缓存穿透的问题之外,还有其它用途。
比如爬虫爬过的url不需要重复爬取。















 1159
1159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









