









文章目录
存储引擎
5.5以前默认存储引擎是myisam,5.5以后默认的存储引擎是InnoDB。
存储引擎比较
MyISAM
表级锁限制了读写的性能,在web和数据仓库配置中,它通常用于只读或以读为主的工作。
特点:
支持表级锁(插入和更新会锁表)。不支持事务
有较高的查询和插入速度。
存储了表的行数。(count速度更快)
InnoDB
InnoDB行级锁。
InnoDB将用户数据存储在聚集索引中,以减少基于主键的常见查询I/O。
特点:
支持事务、支持外键,因此数据一致性、完整性更高。
支持行锁和表锁。
支持读写并发,写不阻塞读。(MVCC)
特殊的索引存放方式,可以减少IO,提升查询效率。
执行引擎
存储引擎,是我们存储数据的形式。是谁执行去操作存储引擎呢?
这是我们的执行引擎,它利用存储引擎的API来完成操作。
这也就是我们修改了表的存储引擎后,操作方式为什么不变的原因。因为不同功能的存储引擎实现的API接口是相同的。
Mysql体系结构
我们可以把mysql分为3层,跟客户端对接的连接层,真正执行操作的服务层,和跟硬件打交道的存储引擎层。
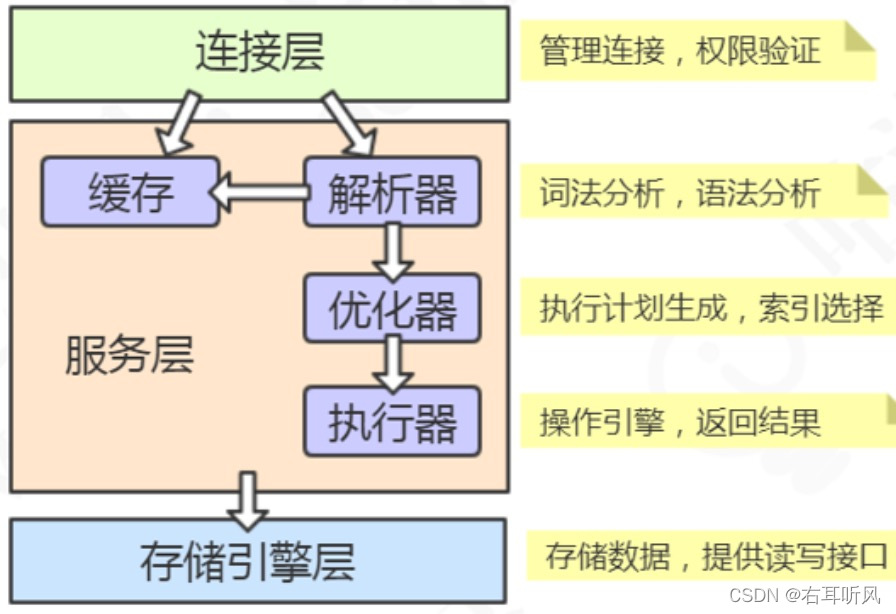
连接层
客户端要连接到Mysql服务器3306端口,必须要跟服务器建立连接。管理所有连接,验证客户端的身份和权限,这些功能就在连接层完成。
服务层
连接层会把SQL语句交给服务层,经过一系列步骤最后交给**执行引擎(执行器)**去执行。
存储引擎
存储引擎就是我们数据真正存放的地方,mysql支持不同的存储引擎。
一条更新的SQL是如何执行的
在数据库里,我们说的update操作其实包括了更新、插入、删除。如果熟悉mybatis源码,应该直到Executor里面也只有doQuery()和doUpdate()。
更新和查询流程有什么不同?
基本流程是一致的,它也要经过解析器、优化器处理,最后交给执行器。
区别在于拿到符合条件的数据之后的操作。
缓冲池Buffer Pool
对于InnoDB来说,数据是存放在磁盘上的,存储引擎要操作数据,必须把数据从磁盘加载到内存才可以操作。
磁盘I/O的读写相对于内存来说是很慢的。如果我们需要的数据分散在磁盘的不同地方,那意味着会产生很多次I/O操作。
所以,无论操作系统来说,还是存储引擎,都有一个预读取的概念。也就是说,当磁盘的一块数据被读取的时候,很有可能它附近的位置也会马上被读取到,这个就叫局部性原理。那么这样,我们干脆每次多读取一些,而不是用多少读多少。
InnoDB设定了一个存储引擎从磁盘读取数据到内存的最小单位,叫做页。操作系统也有页的概念。操作系统的页大小一般是4K,而在InnoDB里面,这个最小单位默认是16K。举个例子,你去烧烤店问老板买1个生蚝。她根本不卖你,懒得给你烤。老板给您卖生蚝,是一打一打的卖。
我们要操作的数据就在这样的页里面,数据所在的页叫数据页。
这里有一个问题,操作数据的时候,每次都要从磁盘读取到内存,有没有什么办法可以提高效率?
还是缓存的思想。把读取的数据页缓存起来。
InnoDB设计了一个内存缓冲区。读取数据的时候,先判断是不是在这个内存区域里面。如果不是,再从磁盘加载。
这个内存区有个名字,叫Buffer Pool。
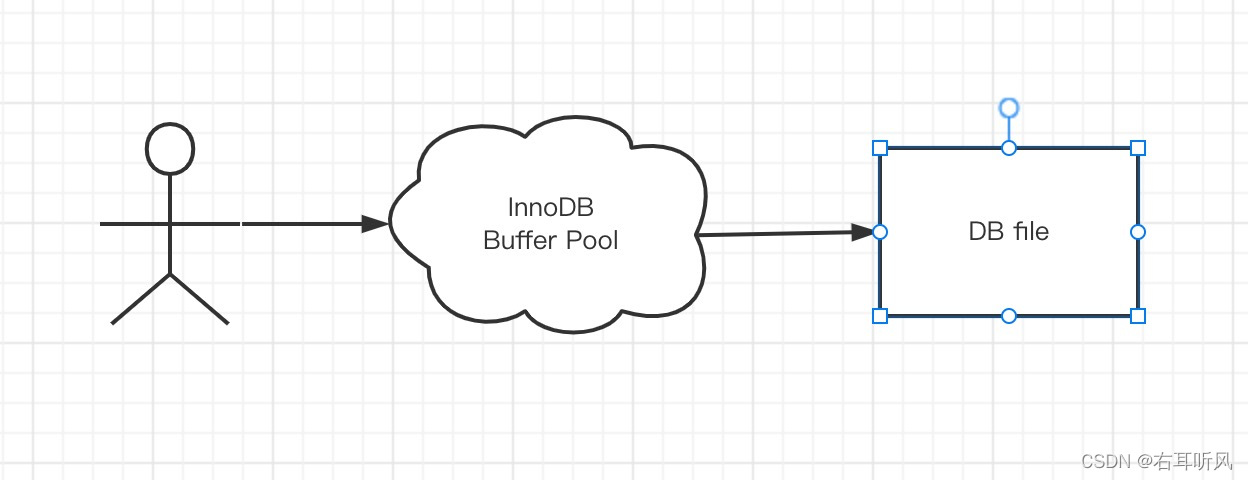
修改数据的时候,也是先写入Buffer Pool,而不是直接写入磁盘。内存的数据页和磁盘数据不一致的时候,我们把它叫做脏页。那么脏页什么时候才同步到磁盘呢?
InnoDB里面转么有一个后台线程把Buffer poll的数据写入磁盘,每隔一段时间就一次性把多个修改写入磁盘,这个动作就叫做刷脏。
Redo log
因为刷脏不是实时的,如果Buffer pool里面的脏页还没有输入磁盘,这个时候数据库宕机,这些数据就会丢失。
那么怎么办?所以内存的数据必须有一个持久化的操作措施。
为了避免这个问题,InnoDB把所有对页面的修改专门写入一个日志文件。
如果有未同步到磁盘的数据,数据库在启动的时候,会从这个日志文件进行恢复操作。我们所说的事务ACID里面的D(持久性),就是用它来实现的。
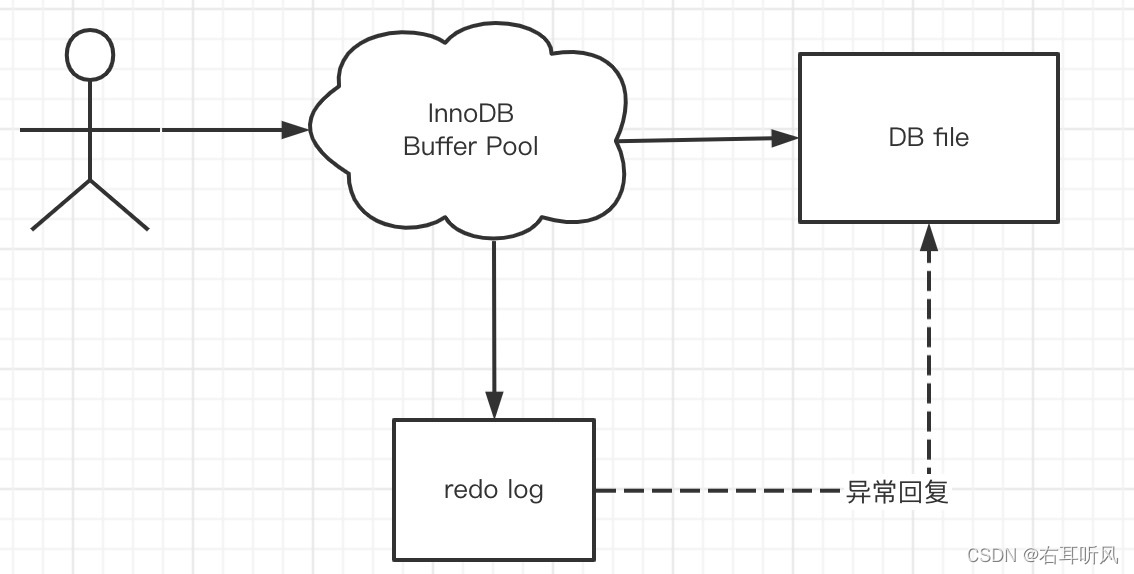
这个日志文件就是磁盘的redo log(叫做重做日志)。
有人问,为什么不直接写到db file里面去?为什么先写日志再写磁盘?
写日志文件和写数据文件有什么区别?
我们说一下磁盘寻址过程。这个是磁盘的构造。磁盘的盘片不停地旋转,磁头会在磁盘表面画出一个圆形的轨迹,这个叫磁道。从内到外半径不同有很多磁道。然后又用半径线,把磁道分割成了扇区。如果要写数据必须找到数据对应的扇区,这个过程就叫寻址。
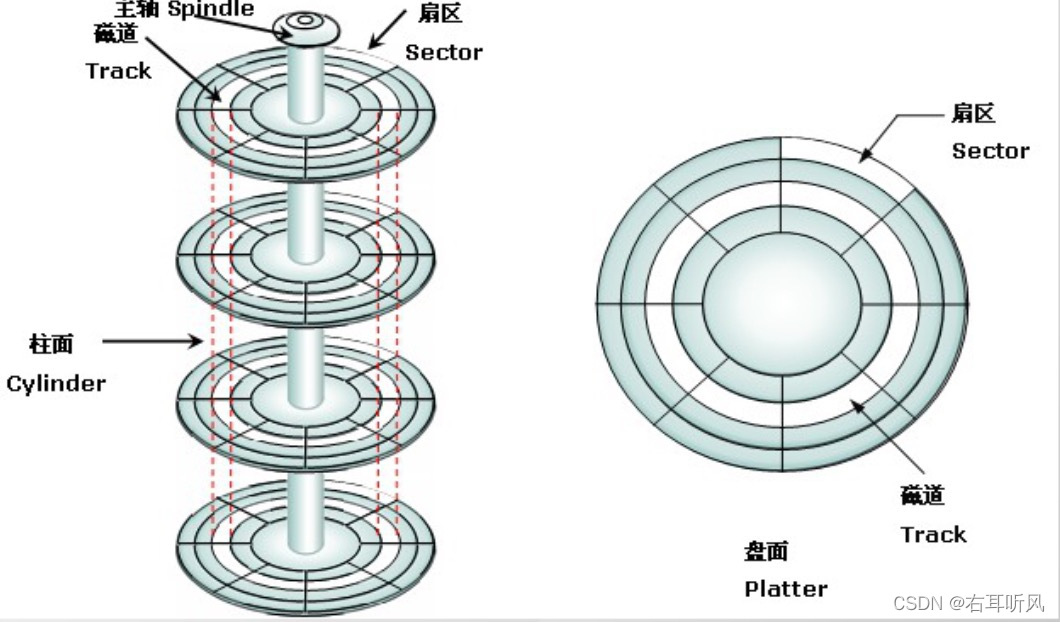
如果我们所需的数据随机分散在不同页的不同扇区中,那么就需要旋转去找。这个就是随机I/O,读取速度比较慢。
假设我们已经找到了第一块数据,并且其它所需的数据就在这一块数据后面,那么就不用重新寻址,可以依次拿到我们所需的数据,这个就叫顺序I/O。
刷盘是随机IO,而记录日志是顺序IO(连续写的),顺序IO效率更高。
redo log位于/var/lib/mysql目录下的ib_logfile0和ib_logfile1,默认2个文件。每个48M。
redo log 有什么特点
1、redo log是InnoDB存储引擎实现的,并不是所有存储引擎都有。支持崩溃恢复是InnoDB的一个特性。
2、redo log不是记录数据页更新之后的状态,而是记录的是"在某个数据页做了什么修改"。属于物理日志。
3、redo log的大小固定,前面的内容会被覆盖,一旦写满,就会触发Buffer pool到磁盘的同步,以便于腾出空间记录后面的修改。
除了redo log之外,还有一个跟修改有关的日志,叫做undo log。redo log和undo log与事务密切相关,统称为事务日志。
undo log
undo log(回滚日志或撤销日志)记录了事务发生之前的数据状态,分为insert undo log和update undo log。如果修改数据时出现异常,可以用undo log来实现回滚操作。(保持了原子性)
redo log和undo log与事务密切相关,统称为事务日志。
InnoDB总体架构
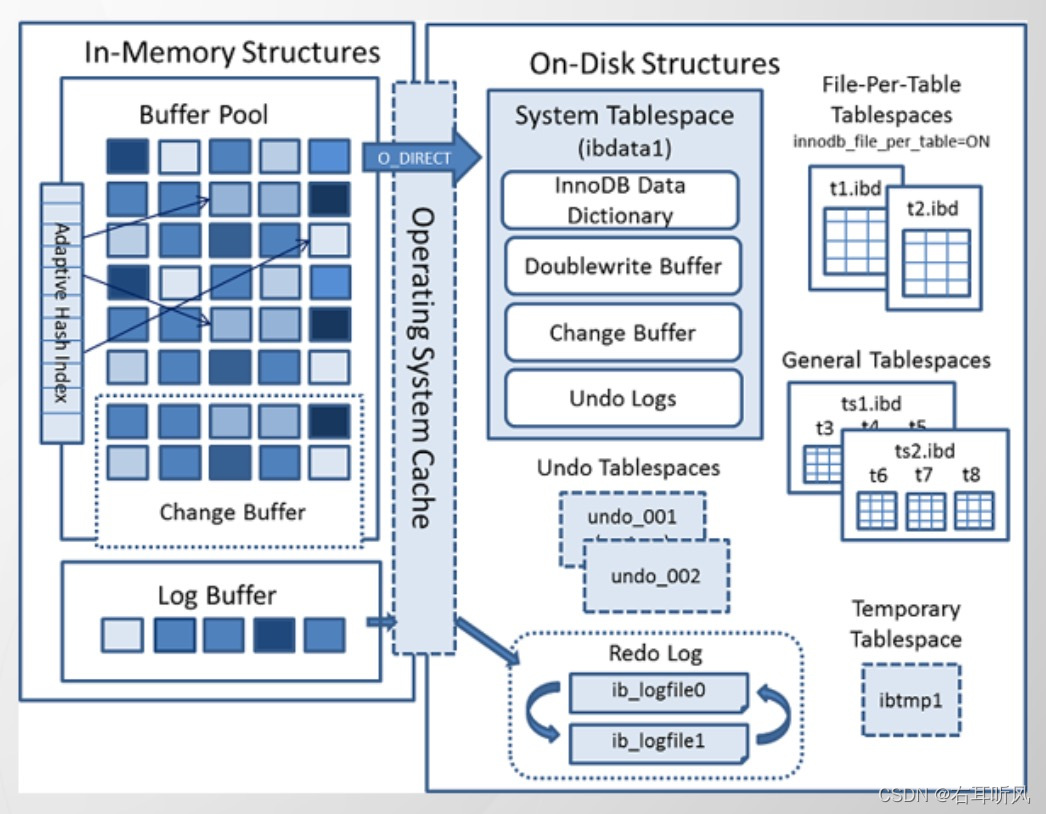
表空间可以看做InnoDB存储引擎结构的最高层,所有的数据都存放在表空间。InnoDB表空间分为5类。
系统表空间system tablespace
InnoDB系统表空间包含InnoDB 数据字典和双写缓冲区、undo logs。
数据字典:有内部表组成,存储表定义和索引的元数据(定义信息)。
双写缓冲
InnoDB的页和操作系统的页大小不一致,InnoDB默认16K,操作系统页大小4K,InnoDB的页写入磁盘时,一个页需要分4次写入。
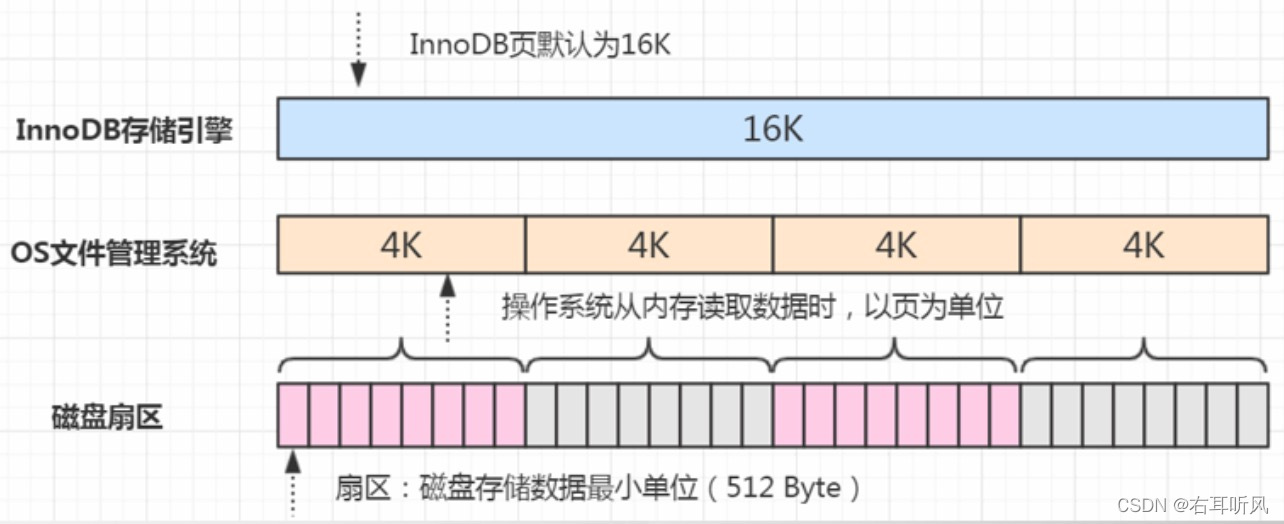
如果存储引擎正在写入页的数据到磁盘时发生了宕机,可能出现页只写了一部分。比如只写了4K就宕机了,这种情况叫做部分写失效。可能会导致数据丢失。
我们不是有redo log吗?但是有个问题,如果这个页本身已经损坏,用它来做崩溃恢复是没有意义的。所以在使用redo log之前,需要一个页的副本。如果出现了写入失效,就用页的副本来还原这个页,然后再用redo log。这个页的副本叫做double write。InnoDB的双写技术,保证了数据页的可靠性。
独占表空间file-per-table tablespaces
我们可以让每张表独占一个表空间。
通用表空间 general tablespaces
通用表空间也是一种共享的表空间。
临时表空间
存储临时表的数据
undo log tablespace
binlog
binlog以事件的形式记录所有的DDL和DML语句。可以用来做主从复制和数据恢复。
跟redo log不同,它的文件是可以追加的,没有固定大小限制。
在开启binlog功能的情况下,我们可以把binlog导出成sql语句,把所有的操作重放一遍,来实现数据的恢复。
binlog的另一个功能就是实现主从复制,它的原理就是从服务器读取mater的binlog,然后执行一遍。
有了binlog和redo log之后,我们看一下一条更新的SQL是怎么执行的。
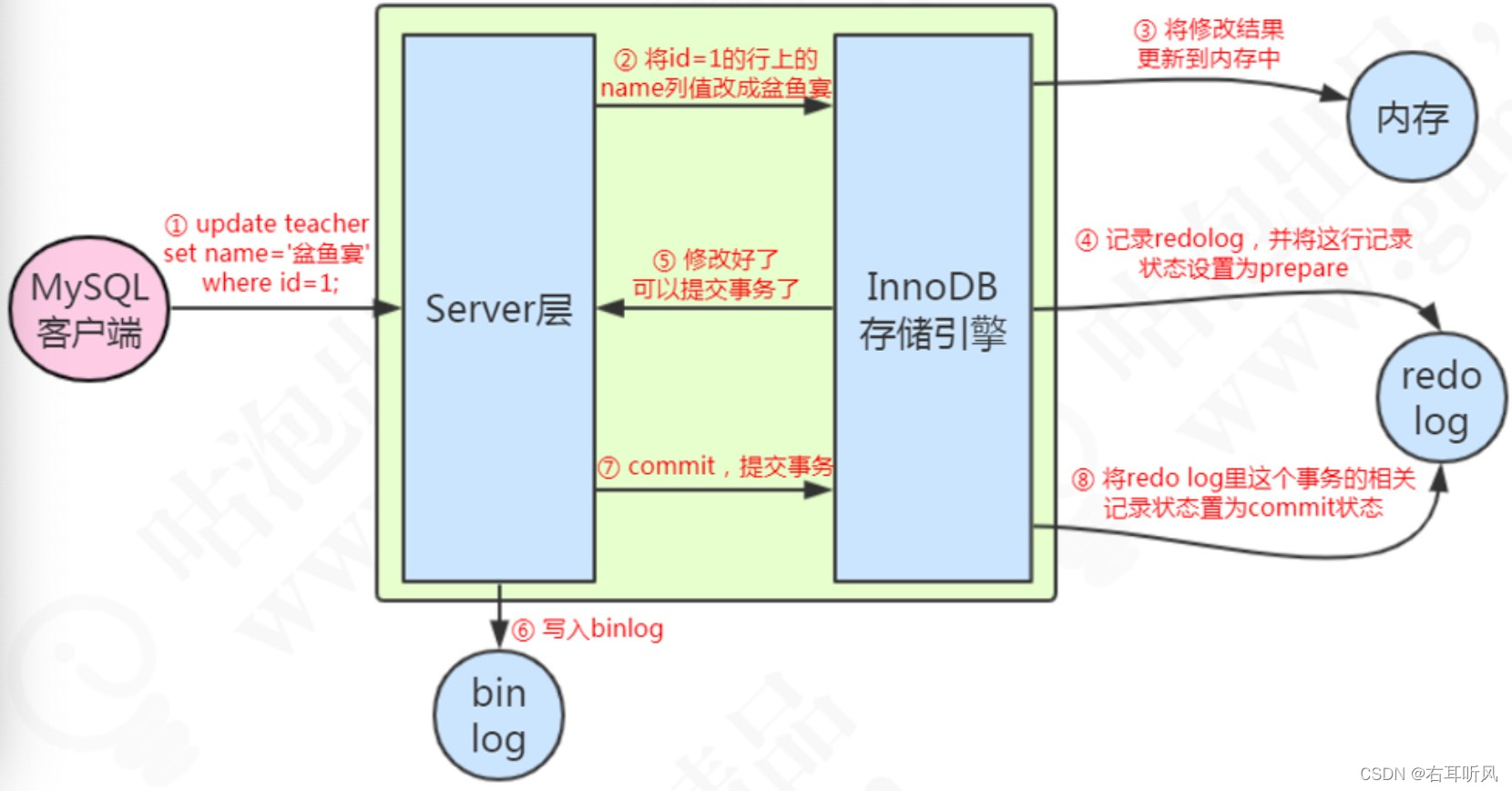
这张图片的重点:
1、先记录到内存,再写日志文件。
2、记录redo log 分为两个阶段。
3、存储引擎和server记录不同的日志
4、先记录redo,再记录binlog。
为什么需要redo log两阶段提交?
举例:
如果写完redo log,还没有写完binlog的时候,mysql重启了。
因为redo log可以再重启的时候用于恢复数据,所以写入磁盘的数据不对。因为binlog里面没有记录这个日志,所以binlog去恢复数据或者同步到从库,就会出现数据不一致的情况。
简单那来说2次redo log的提交,类似于分布式事务。














 1781
1781











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









