






在使用sql中我们会有各种各样的条件筛选,常见的就是要踢出一部分我们不需要的数据,在where后面的踢出方法常见的有 (not in / and not / <> / !=) 这四种方法,既然存在这样四种方法,那么我们又该如果选择最佳方法呢?下面我们就一起来测试下这四种筛选条件的执行效率。
为了测试数据,我建了一张零时表@index中有三个字段:ID ,iID, idate 。然后循环插入1000000条数据。建表的语句:

declare @index table(id int,t_id int,idate date)
declare @id int,@iid int,@idatedate
set @id =1
set @iid=1000000
Set @idate = GETDATE()
while(@id<1000000)
begin
insert into @index values(@id,@iid,@idate)
set @id=@id+1
Set @iid =@iid-1
end
我们使用SET STATISTICS TIME ON ;SET STATISTICS TIME OFF来查看sql耗时,在执行前先清空缓存DBCC DROPCLEANBUFFERS;查询语句如下:
SET STATISTICS TIME ON
select * from @index where id not in (1)
select * from @index where not id=1
select * from @index where id<>1
select * from @index where id!=1
SET STATISTICS TIME OFF
Execute下我们先看看sql执行计划:

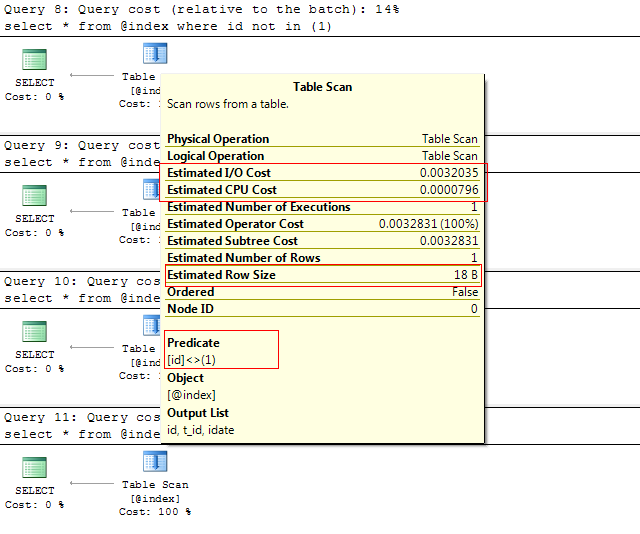
从sql执行计划中我们看不到区别,表扫描的结果页都一样,这里就不一一列出了,如果你们又怀疑可以自己试试!然后我们在看看执行结果中message消息中,我们对耗时的查询:

当我们后面跟的筛选条件只有一条时,not in 的查询结果会有明显的优势,而其他的几种查询结果也都大同小异,not似乎耗时也稍稍多点。但是往往我们在做筛选的时候not in 后面的条件会不止一个,如果只有这么一个筛选是的不出什么结果的,那么我们就加大筛选的条件。
SET STATISTICS TIME ON
select * from @index where id not in (1,10,30,33,59,66,77,100,10000)
select * from @index where not id=1 and not id=10 and not id=30 and not id=33 and not id=59 and not id=66 and not id=77 and not id=100 and not id=10000
select * from @index where id<>1 and id<>10 and id<>30 and id<>33 and id<>59 and id<>66 and id<>77 and id<>100 and id<>10000
select * from @index where id!=1 and id!=10 and id!=30 and id!=33 and id!=59 and id!=66 and id!=77 and id!=100 and id!=10000
SET STATISTICS TIME OFF
看看执行计划:
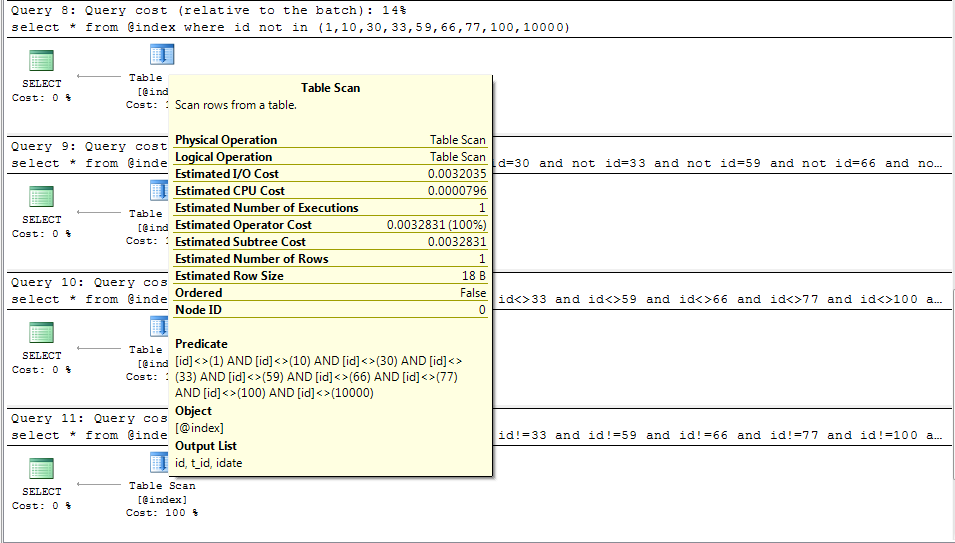
执行计划仍然相同,我们去看看耗时查询:

到这里我们已经清楚了这四种筛选方法各自的执行效率,不知道是不是由于我用的是表变量,对查询结果造成了一定的影响,如果有兴趣你们也可以试下,对于 sql查询条件我们可以尽量选择比较合适的方法来做,比较需要踢出的数据比较多我们就不可能去用后面的三种一个一个的踢出,本文demo中采用的数据量是 1000000条已经是比较大的数据量了,这里看到这四种筛选条件执行消耗的时间并没有多少优势。
由于本文使用的是表变量,并没有对物理扫描,所以并不能保证在做物理查询时一致!学术是需要严谨的论证的,不能因为片面的原因而得出结论,那么我下面就来用物理表的扫描来查看他们的执行性能。
建表的过程就不在赘述,我们直接来看看sql执行计划,依然是上面的查询语句,不过要注意我本次使用的是物理表的查询:
--------清空缓存
DBCCDROPCLEANBUFFERS
DBCCFREEPROCCACHE
SET STATISTICS TIME ON
select * from [index] where id not in (1,10,30,33,59,66,77,100,10000)
select * from [index] where not id=1 and not id=10 and not id=30 and not id=33 and not id=59 and not id=66 and not id=77 and not id=100 and not id=10000
select * from [index] where id<>1 and id<>10 and id<>30 and id<>33 and id<>59 and id<>66 and id<>77 and id<>100 and id<>10000
select * from [index] where id!=1 and id!=10 and id!=30 and id!=33 and id!=59 and id!=66 and id!=77 and id!=100 and id!=10000
SET STATISTICS TIME OFF
看看执行计划:
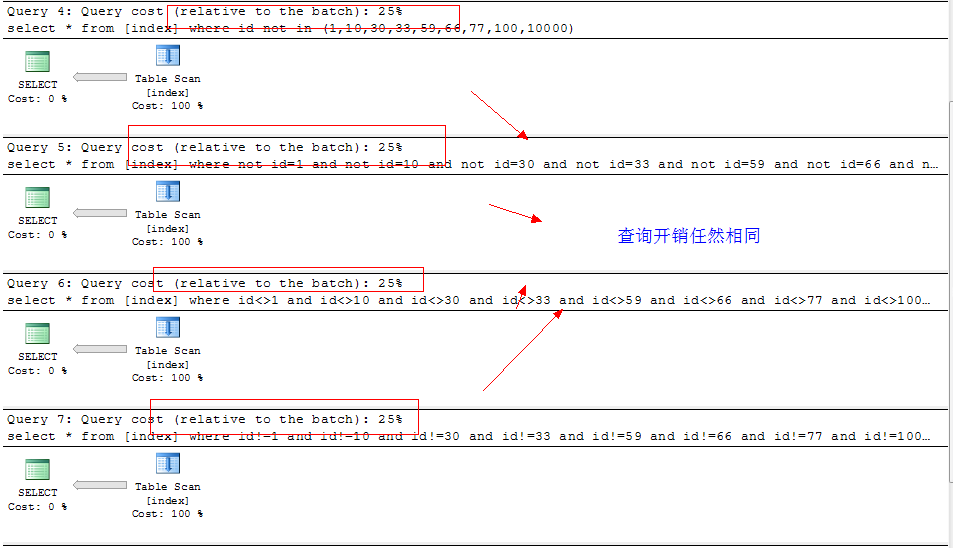
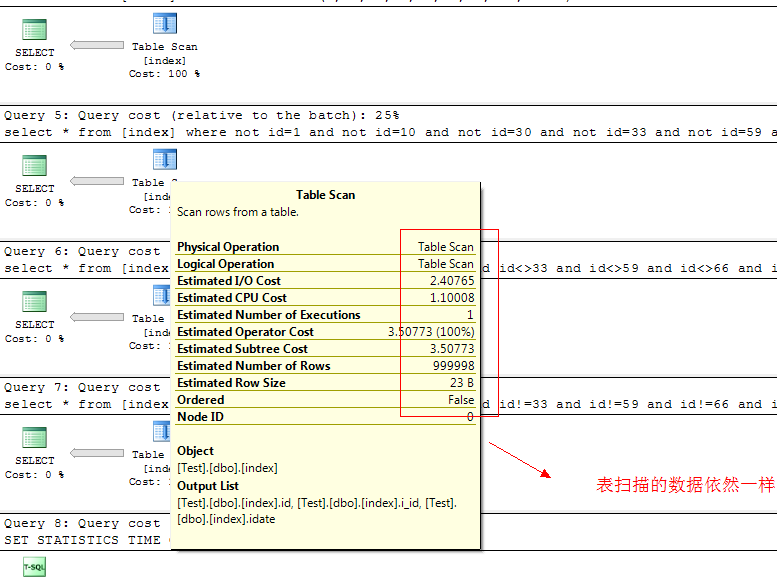
看看耗时查询结果:

程序是一门严谨的科学,很多事情都需要我们自己去做去了解,我曾不止一次看到有很多文章写道not in 在查询的时候对内存消耗严重,性能低下,在数据达到百万级别的时候查询会很慢,但是当数据量大的时候任何查询都会很慢的,既然sql中给我们提供了这些方 法,自有他的用武之地,而不能片面的觉得谁比谁更好,我们要根据需求选择,最终的目的是为了解决问题,给世界创造价值。
由于本人能力有限,文中有错误之处还望给我前辈不吝赐教!














 1783
1783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









