




简介:本文探讨了计算机系统中两种数据存储格式:大端模式(Big Endian)和小端模式(Little Endian),并介绍了它们在不同CPU架构中的字节顺序差异。解释了大端与小端模式之间的转换在跨平台数据传输中的重要性,并说明了如何将大端格式的数据转换为小端格式,以便在PC上解析。进一步,介绍了将文本形式的十六进制数据转换为二进制形式,并保存为JPG图像文件的过程,以及涉及到的关键步骤。
1. 大端模式与小端模式介绍
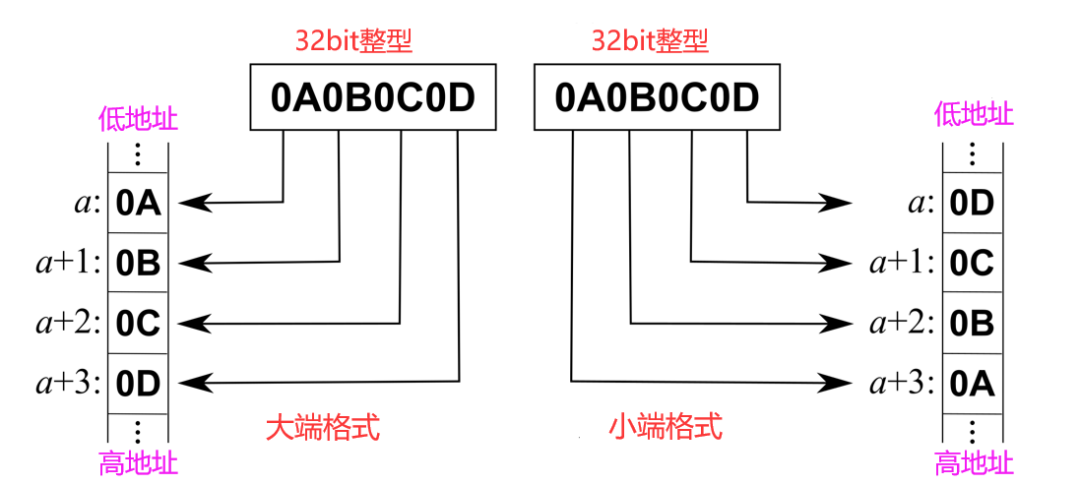
在计算机系统中,字节序(Byte Order)是指多字节数据类型在内存中的存储顺序,分为大端模式(Big-endian)和小端模式(Little-endian)。大端模式是指最高有效字节存放在最低的存储地址,而小端模式则相反。这两种模式在数据交换和硬件架构中扮演着关键角色,尤其是在不同处理器和平台间传输数据时,正确处理字节序至关重要,以避免数据被错误解析。
2.1 字节序的概念及其在数据传输中的角色
2.1.1 字节序的定义与分类
字节序,或称端序,定义了字节在内存中的排列顺序。大端模式由RFC 1700定义,广泛应用于网络协议,如TCP/IP。小端模式则常见于x86架构的处理器。了解这两种模式对于开发人员进行跨平台开发以及在网络编程中保证数据一致性的场景至关重要。
2.1.2 字节序对数据传输的影响
字节序差异会导致同一段数据在不同系统上的解读不同,因此在数据传输或存储时需要进行字节序转换。例如,一个32位整数 0x12345678 在大端系统中存储为 12 34 56 78 ,而在小端系统中则是 78 56 34 12 。若不处理这种差异,接收方可能会把发送方的数据解释为错误的数值或结构。
正确处理字节序不仅保证数据准确无误地传输,也是确保跨平台应用稳定运行的基础。
2. 跨平台数据传输中的字节序转换重要性
在现代计算领域,数据经常需要在不同平台之间传输。在这个过程中,字节序(Byte Order)的转换变得至关重要。不同的计算平台可能使用不同的字节序存储多字节数据类型(如整数和浮点数),这导致了数据格式在传输过程中的不一致性问题。
2.1 字节序的概念及其在数据传输中的角色
2.1.1 字节序的定义与分类
字节序指的是在多字节数据类型中,字节存储顺序的排列方式。字节序可以分为两种基本类型:大端字节序(Big-Endian)和小端字节序(Little-Endian)。
- 大端字节序 :最高有效字节(MSB,Most Significant Byte)存储在最小的地址处。在大端字节序中,数据的最高位字节位于内存的起始位置。
- 小端字节序 :最低有效字节(LSB,Least Significant Byte)存储在最小的地址处。在小端字节序中,数据的最低位字节位于内存的起始位置。
2.1.2 字节序对数据传输的影响
不同的计算机体系结构(如x86、ARM和MIPS)可能会使用不同的字节序。例如,Intel x86架构是小端字节序,而PowerPC和网络协议通常使用大端字节序。这种不一致性如果不加以处理,就会在数据传输过程中造成混乱。
2.2 字节序转换的必要性
2.2.1 硬件平台差异导致的字节序问题
由于不同硬件平台可能使用不同的字节序,应用程序需要处理不同平台之间的字节序差异。例如,在网络数据传输中,需要考虑发送端和接收端字节序可能不一致的问题。
2.2.2 软件兼容性对字节序转换的需求
软件系统中也广泛存在着字节序问题,特别是在设计分布式系统时。不同系统之间的数据交换必须确保字节序的统一,否则会引起数据解释错误,影响程序运行的正确性。
2.2 字节序转换方法
为了解决跨平台数据传输中的字节序问题,有必要进行字节序转换,使数据在不同系统间能正确地被解释和使用。
2.2.1 编程语言内置函数转换
现代编程语言通常提供内置函数来处理字节序转换问题。例如,C/C++语言中的 ntohs 、 ntohl 、 htons 和 htonl 函数可用于转换网络字节序和主机字节序。
#include <arpa/inet.h> // 包含网络字节序转换函数
uint32_t host_to_network(uint32_t value) {
return htonl(value); // 将主机字节序转换为网络字节序
}
uint16_t network_to_host(uint16_t value) {
return ntohs(value); // 将网络字节序转换为主机字节序
}
2.2.2 手动实现字节序转换算法
在没有内置函数的环境中,或者出于性能考虑,开发者可以手动实现字节序转换算法。下面是一个大端和小端转换的例子:
uint32_t swap_endian(uint32_t value) {
return ((value & 0xFF000000) >> 24) |
((value & 0x00FF0000) >> 8) |
((value & 0x0000FF00) << 8) |
((value & 0x000000FF) << 24);
}
在上述代码中,通过位移和按位或操作对 value 的四个字节进行顺序重排,从而实现大端和小端之间的转换。
2.2.3 字节序转换工具
除了编程实现,市场上也存在多种工具可用于字节序的转换,例如在线转换器和集成开发环境(IDE)的插件。
通过本章的介绍,我们理解了字节序及其在跨平台数据传输中的重要性,以及如何利用编程语言内置函数、手动算法和现有工具进行有效的字节序转换。在后续章节中,我们将进一步探讨将这些理论应用到实际的数据转换过程中。
3. 大端到小端数据格式转换的步骤
3.1 理解大端和小端数据格式的差异
3.1.1 大端和小端数据表示法
在计算机科学中,字节序(Byte Order)是指多字节数据在内存中的存放顺序,它决定了数据的解释方式。大端模式(Big-endian)和小端模式(Little-endian)是两种常见的字节序类型,其差异主要体现在数据的存储和解析上。
大端模式是指数据的高位字节存放在低地址处,而小端模式则是将数据的低位字节存放在低地址处。比如,假设有一个16位(2字节)的整数0x1234,其高字节是0x12,低字节是0x34。在大端模式下,0x12将被存储在低地址处,而在小端模式下,0x34将被存储在低地址处。
3.1.2 数据格式转换的基本原则
在进行大端到小端的数据格式转换时,需要遵循一定的原则,确保数据的完整性和正确性。基本原则包括:
- 识别数据的字节长度,以便正确地进行转换。
- 对于每一个字节,都要确定其在原始数据中的位置,并在转换过程中保持其位置关系。
- 转换后的数据应保持与原始数据等值,只是字节顺序发生了变化。
3.2 实现大端到小端转换的方法
3.2.1 通过编程语言内置函数转换
许多编程语言提供了内置函数或方法来支持大端和小端之间的转换。这些内置函数通常是语言标准库的一部分,使用起来非常方便。
以Python为例,可以使用 struct 模块中的 pack 和 unpack 函数来实现转换。例如,要将16位的整数 0x1234 从大端转换为小端,可以这样做:
import struct
# 大端表示的16位整数
big_endian = struct.pack(">H", 0x1234)
# 将大端的字节序转换为小端的字节序
little_endian = struct.pack("<H", struct.unpack(">H", big_endian)[0])
print(little_endian) # 输出小端格式的字节序列
该代码首先创建了一个大端格式的字节序列,然后通过 unpack 函数将其转换为整数,最后再次使用 pack 函数以小端格式输出。
3.2.2 手动实现字节序转换算法
除了使用内置函数之外,开发者还可以手动实现字节序转换算法。通过遍历字节序列并调整每个字节的位置,可以实现手动转换。
假设有一个字节序列 0x12 0x34 ,以下是手动实现大端到小端转换的示例:
def big_to_little_endian(bytes_sequence):
# 确保字节序为大端
assert bytes_sequence == bytes([0x12, 0x34]), "序列不是大端格式"
return bytes([bytes_sequence[1], bytes_sequence[0]])
# 使用函数进行转换
little_endian = big_to_little_endian(bytes([0x12, 0x34]))
print(little_endian) # 输出小端格式的字节序列
在这个例子中,函数 big_to_little_endian 接收一个字节序列,并将其转换为小端格式。这种方法不依赖于语言的内置函数,因此在一些限制条件下使用起来非常灵活。
通过上述方法,程序员可以有效地处理跨平台数据传输中的字节序问题,保证数据的正确解析。在实际应用中,选择合适的方法取决于具体的需求和开发环境。
4. 十六进制文本数据转换为二进制数据的方法
在数字计算和数据存储中,十六进制和二进制经常出现在程序员和工程师的日常工作中。十六进制由于其紧凑性和易于人类阅读的特性,常用于文本表示法来显示二进制数据。本章将探讨这两种数据表示法之间的关系,并介绍将十六进制文本数据转换为二进制数据的具体方法。
4.1 十六进制与二进制的关系
4.1.1 十六进制数的表示与转换
十六进制数系统是基于16的数制,它的基数为16,允许使用16个符号来表示数值:0-9以及A-F。其中A-F分别代表了十进制的10-15。在二进制系统中,每个十六进制位对应于4位二进制数。例如,十六进制的10实际上代表的是二进制的0001 0000。
在计算机系统中,二进制是最低层的数据表示形式,然而,由于二进制数据较难以阅读和理解,特别是对于较大的数值,因此常常使用十六进制进行表示。因此,了解十六进制与二进制之间的转换是进行数据解析和处理的基础。
// 示例:十六进制转二进制的C语言代码
#include <stdio.h>
#include <stdlib.h>
// 函数:将单个十六进制字符转换为对应的四位二进制字符串
void hexCharToBinary(char hexChar, char *binaryString) {
switch (hexChar) {
case '0': sprintf(binaryString, "0000"); break;
case '1': sprintf(binaryString, "0001"); break;
case '2': sprintf(binaryString, "0010"); break;
case '3': sprintf(binaryString, "0011"); break;
case '4': sprintf(binaryString, "0100"); break;
case '5': sprintf(binaryString, "0101"); break;
case '6': sprintf(binaryString, "0110"); break;
case '7': sprintf(binaryString, "0111"); break;
case '8': sprintf(binaryString, "1000"); break;
case '9': sprintf(binaryString, "1001"); break;
case 'A': case 'a': sprintf(binaryString, "1010"); break;
case 'B': case 'b': sprintf(binaryString, "1011"); break;
case 'C': case 'c': sprintf(binaryString, "1100"); break;
case 'D': case 'd': sprintf(binaryString, "1101"); break;
case 'E': case 'e': sprintf(binaryString, "1110"); break;
case 'F': case 'f': sprintf(binaryString, "1111"); break;
default: sprintf(binaryString, "????"); break;
}
}
// 主函数
int main() {
char hexString[] = "1A3F";
char binaryString[5];
int i;
printf("Hexadecimal: %s\n", hexString);
for (i = 0; i < sizeof(hexString) - 1; ++i) {
hexCharToBinary(hexString[i], binaryString);
printf(" %c -> %s\n", hexString[i], binaryString);
}
return 0;
}
上述代码段展示了如何将十六进制的单个字符转换为相应的四位二进制字符串。每个十六进制字符对应的二进制字符串通过一个简单的查找转换实现。
4.1.2 二进制数据的存储与应用
在计算机内部,所有的数据最终都会被转换为二进制的形式存储和处理。二进制的0和1可以非常清晰地区分电压的高低状态,这些状态可以轻松地通过电子硬件(如晶体管)来实现。
二进制数据广泛应用于计算机存储、网络通信、文件系统等多个方面。理解二进制数据如何在各种应用中转换和使用对于IT专业人员来说至关重要。例如,在文件系统中,二进制数据表示文件内容;在网络传输中,二进制数据表示网络包的内容;在数据库中,二进制数据代表存储的数据。
4.2 十六进制文本到二进制数据的转换过程
4.2.1 编程实现十六进制字符串的解析
将十六进制文本转换为二进制数据,一个常见的做法是通过编程实现十六进制字符串的解析。这种解析过程通常涉及两个步骤:首先是验证输入的十六进制字符串是否合法,然后是将每个十六进制字符转换为对应的4位二进制字符串。
以下是一个示例代码,展示了如何用Python编写一个十六进制字符串到二进制字符串的转换工具:
def hex_to_binary(hex_string):
# 移除可能存在的空格并确保是大写格式
hex_string = hex_string.replace(" ", "").upper()
binary_string = ""
# 转换每个十六进制字符到对应的四位二进制字符
for i in range(0, len(hex_string), 2):
if i+1 < len(hex_string):
hex_pair = hex_string[i:i+2]
else:
# 如果字符串长度为奇数,在最后添加一个零
hex_pair = hex_string[i:i+1] + '0'
# 将十六进制对转换为二进制,并添加到结果字符串
binary_string += bin(int(hex_pair, 16))[2:].zfill(8)
return binary_string
# 示例使用
hex_string = "4D6F7A696C6C61202521"
binary_string = hex_to_binary(hex_string)
print(f"Hex: {hex_string}\nBin: {binary_string}")
这段Python代码首先去除十六进制字符串中的空格,并确保全部转换为大写形式。之后,它遍历字符串,每两个字符为一组,将十六进制字符转换为二进制,并将结果字符串拼接起来。
4.2.2 十六进制转换工具的使用及原理
除了编程实现外,存在许多现成的十六进制转换工具,能够帮助用户轻松地将十六进制文本转换为二进制数据。这些工具通常提供图形用户界面,通过简单的拖放或复制粘贴操作即可完成转换。
一个典型的转换工具可能使用了与上述Python示例相同的逻辑,尽管具体实现可能依赖于不同的编程语言和库。基本原理都是将输入的十六进制文本视为一个数据缓冲区,并逐个字节读取每个十六进制对,将它们转换为相应的4位二进制数。
下面是十六进制转换工具的一般工作流程:
- 用户通过界面选择或输入十六进制文本。
- 工具检查输入的十六进制数是否合法。
- 工具按每两个十六进制字符一组将数据进行分组。
- 每组数据被转换为相应的8位二进制数。
- 结果以二进制字符串或二进制文件的形式展示给用户。
综上所述,无论是通过编程实现还是使用现成的转换工具,将十六进制文本数据转换为二进制数据是一个相对简单且实用的过程。它不仅加深了我们对计算机内部数据表示的理解,还为处理二进制数据提供了有力的工具和方法。
5. 二进制数据保存为JPG文件的过程及图像头部信息编码标准
5.1 二进制数据与图像文件的关系
5.1.1 图像文件格式概述
在计算机科学中,图像文件格式是用于存储数字图像信息的标准方式。不同的格式有不同的特性、优势和应用领域。例如,BMP是Windows系统的原生图像格式,GIF常用于网络动画,PNG提供了无损压缩,并广泛用于网页设计中,而JPG则以其优秀的压缩比被广泛应用于网络和数字摄影领域。
5.1.2 JPG文件格式特点及编码机制
JPG(Joint Photographic Experts Group)是一种常见的有损压缩图像文件格式。它主要用于存储连续色调的静态图像,特别是照片。JPG格式的特点在于它通过改变色彩空间并应用离散余弦变换(DCT)和量化来实现高比例的数据压缩。这使得图像文件在保持了相对较高的图像质量的同时,大幅度减小了文件的大小。
5.2 二进制数据保存为JPG文件的实现
5.2.1 二进制数据到JPG文件的转换过程
将二进制数据保存为JPG文件需要通过图像处理库来完成。这个过程通常包括创建一个新的JPG对象,将二进制数据转换为位图,并应用压缩算法。以下是使用Python语言和Pillow库实现二进制数据到JPG文件转换的简单示例:
from PIL import Image
import io
# 假设binary_data是包含图像的二进制数据
binary_data = ...
# 将二进制数据加载到字节流中
byte_stream = io.BytesIO(binary_data)
# 创建一个新的JPG图像
jpg_image = Image.open(byte_stream)
# 保存为JPG文件
jpg_image.save('output.jpg')
5.2.2 图像头部信息的编码与嵌入
JPG文件头部包含有关图像的信息,如尺寸、颜色深度、压缩信息等。这些信息被编码在文件的开始部分。当保存为JPG格式时,这些头部信息需要被正确编码以确保图像能够在不同的软件中被正确解析。
5.3 字节序转换和文件格式转换在跨平台编程中的应用
5.3.1 提高数据交换的兼容性和效率
在跨平台编程中,字节序转换确保了不同架构的计算机系统间数据的正确交换。例如,在一个大端模式的系统中存储的图像数据,在小端模式的系统中打开时需要进行字节序转换。而文件格式转换则允许不同系统共享文件,比如将原始的二进制图像数据转换为JPG格式,以便在多种设备和应用程序中使用。
5.3.2 在不同平台间共享图像文件的实践案例
假设有一个图像处理应用程序需要在MacOS(小端模式)和Linux(大端模式)之间共享图像文件。开发团队需要在软件中实现字节序和文件格式的转换,确保图像数据可以在两个平台间正确交换。在这个案例中,可以使用字节序转换库(如Python中的 struct 模块)来处理数据交换,同时将图像文件统一保存为JPG格式,以保证不同操作系统间都能无损地处理和展示图像内容。
以上章节内容提供了从理解字节序差异到二进制数据保存为JPG文件的全面解析,并且展示了字节序转换和文件格式转换在跨平台编程中的实际应用案例。通过具体步骤的介绍和代码示例,读者可以更加清楚地理解图像文件在不同平台间共享的复杂性以及解决这些问题的技术方法。
简介:本文探讨了计算机系统中两种数据存储格式:大端模式(Big Endian)和小端模式(Little Endian),并介绍了它们在不同CPU架构中的字节顺序差异。解释了大端与小端模式之间的转换在跨平台数据传输中的重要性,并说明了如何将大端格式的数据转换为小端格式,以便在PC上解析。进一步,介绍了将文本形式的十六进制数据转换为二进制形式,并保存为JPG图像文件的过程,以及涉及到的关键步骤。


















 32
32

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









