






前言
本文同时发布于笔者的《对Python内核的理解 - 连载 - 简书》文集一同发布
对于前一篇,我们讨论到字符串对象初始化过程ascii_decode函数,我们说当ascii_decode函数如果对传入参数C级别的字符指针(char*)并没做任何操作,那么unicode_decode_utf8函数将继续调用_PyUnicodeWriter_InitWithBuffer函数,unicode_decode_utf8函数的部分代码片段如下所示
static PyObject *
unicode_decode_utf8(const char *s, Py_ssize_t size,
_Py_error_handler error_handler, const char *errors,
Py_ssize_t *consumed)
{
...
s += ascii_decode(s, end, PyUnicode_1BYTE_DATA(u));
if (s == end) {
return u;
}
// Use _PyUnicodeWriter after fast path is failed.
_PyUnicodeWriter writer;
_PyUnicodeWriter_InitWithBuffer(&writer, u);
writer.pos = s - starts;
Py_ssize_t startinpos, endinpos;
const char *errmsg = "";
PyObject *error_handler_obj = NULL;
PyObject *exc = NULL;
...
}请回顾一下该函数调用的流程图
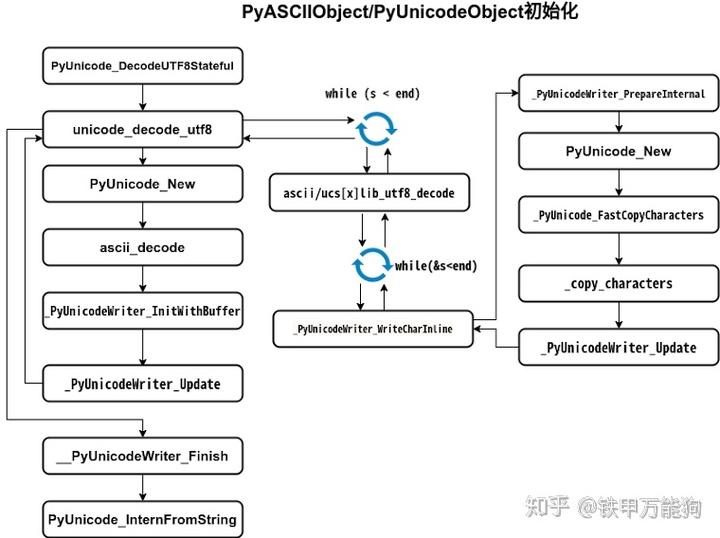
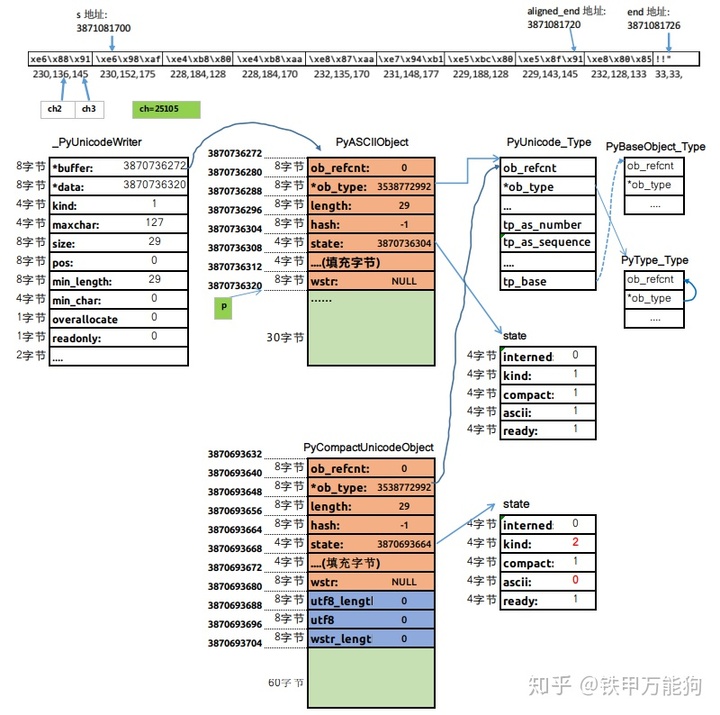
当从ascii_decode函数返回后,unicode_decode_utf8函数得到的一个PyASCIIObject对象的内存实体如下图,ascii_decode在PyUnicodeObject初始化过程中,总是先假定是一个ASCII字符串,因此我们看到state内部类的kind字段为1.
该PyASCIIObject对象的指针(引用)会作为第二个参数传递给_PyUnicodeWriter_InitWithBuffer函数做进一步处理。
_PyUnicodeWriter接口
在unicode_decode_utf8调用_PyUnicodeWriter_InitWithBuffer函数前,它初始化一个_PyUnicodeWriter类型的变量并将该内存地址传递给_PyUnicodeWriter_InitWithBuffer内联函数,那么究竟_PyUnicodeWriter在整个PyUnicode对象初始化过程中起到什么作用呢?,如果你感兴趣的话,可以追溯一下_PyUnicodeWriter的老黄历
在2010年,Python 3.3的PEP 393有了一个全新的Unicode实现,即Python类型str,一直沿用至今。PEP 393的第一个实现使用了很多32位字符缓冲区(Py_UCS4),这需要占用大量内存,并且需要太多性能开销用于转换为8位(Py_UCS1,ASCII和Latin1)或16位(Py_UCS2,BMP)字符。目前流行的CPython3.x用于Unicode字符串的内部结构非常复杂,在构建新字符串以避免存储冗余的副本,因此,字符串的内存利用必须精打细算。而_PyUnicodeWriter类接口减少昂贵的内存副本,甚至在最佳情况下完全避免内存副本。
下面是_PyUnicodeWriter的结构体的源代码,这个类接口没什么好说的。
/* --- _PyUnicodeWriter API ----------------------------------------------- */
typedef struct {
//由PyUnicode_New已分配的对象
PyObject *buffer;
void *data;
enum PyUnicode_Kind kind;
Py_UCS4 maxchar;
Py_ssize_t size;
Py_ssize_t pos;
/* 最小分配字符数 (default: 0) */
Py_ssize_t min_length;
/* 最小的字符数(default: 127, ASCII) */
Py_UCS4 min_char;
/* 如果非零,则对缓冲区进行整体分配 (default: 0). */
unsigned char overallocate;
/* 如果readonly为1,则缓冲区为共享字符串
(无法修改),并且大小设置为0。 */
unsigned char readonly;
} _PyUnicodeWriter ;明确地说,在Objects/unicodeobject.c源文件,大规模地使用了以 _PyUnicodeWriter_为前缀的函数族,而这里介绍的是_PyUnicodeWriter_InitWithBuffer是和字符串对象初始化有关的inline函数。而_PyUnicodeWriter_InitWithBuffer的实质性代码位于_PyUnicodeWriter_Update这个inline函数,如果你C语言基础扎实的话,实际上这两个函数并不存在C运行时函数栈pop/push的开销,因为它们的代码在编译后unicode_decode_utf8函数上下文的一部分。
static inline void
_PyUnicodeWriter_Update(_PyUnicodeWriter *writer)
{
writer->maxchar = PyUnicode_MAX_CHAR_VALUE(writer->buffer);
writer->data = PyUnicode_DATA(writer->buffer);
if (!writer->readonly) {
writer->kind = PyUnicode_KIND(writer->buffer);
writer->size = PyUnicode_GET_LENGTH(writer->buffer);
}
else {
/* use a value smaller than PyUnicode_1BYTE_KIND() so
_PyUnicodeWriter_PrepareKind() will copy the buffer. */
writer->kind = PyUnicode_WCHAR_KIND;
assert(writer->kind <= PyUnicode_1BYTE_KIND);
/* Copy-on-write mode: set buffer size to 0 so
* _PyUnicodeWriter_Prepare() will copy (and enlarge) the buffer on
* next write. */
writer->size = 0;
}
}
// Initialize _PyUnicodeWriter with initial buffer
static inline void
_PyUnicodeWriter_InitWithBuffer(_PyUnicodeWriter *writer, PyObject *buffer)
{
//初始化writer的所有字段为0
memset(writer, 0, sizeof(*writer));
writer->buffer = buffer;
_PyUnicodeWriter_Update(writer);
writer->min_length = writer->size;
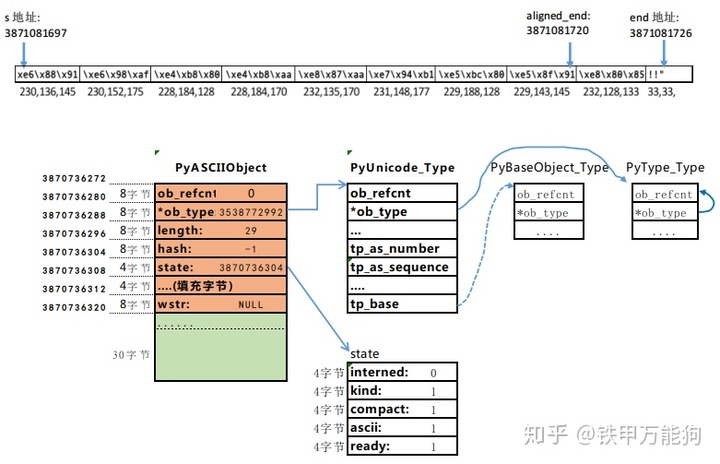
}延续前篇的例子,当执行完_PyUnicodeWriter_InitWithBuffer函数,_PyUnicodeWriter对象和PyASCIIObject对象的内存状态如下图,读者需要区分一个重要的概念,_PyUnicodeWrite对象是基于C级别的栈,而不是堆。
我们CPython的默认编码是utf-8,而utf-8的基本特征是针对不同语言文字或符号,采取不同位宽来存储对应文字或符号的编码,例如一段采用utf-8编码的字符序列,它混杂多个ASCII字符(位宽一个字节)、欧洲诸国的字符(位宽2个字节)、亚洲诸国(位宽3个字节)。那CPython如何知道从哪里开始以一个位宽去读取序列中的字符?下一次从哪里以2个字节或3个字节的位宽去读取对应的字符呢?那么CPython就引入了_PyUnicodeWriter对象,也就是说一个复杂的字符串可能包括多个_PyUnicodeWriter对象可以通过其内部字段
- pos:告知CPython在处理任何unicode字节序列时,该字节序列是否为空。
- kind:以多少位宽的字节去解释序列中的每一个字符。
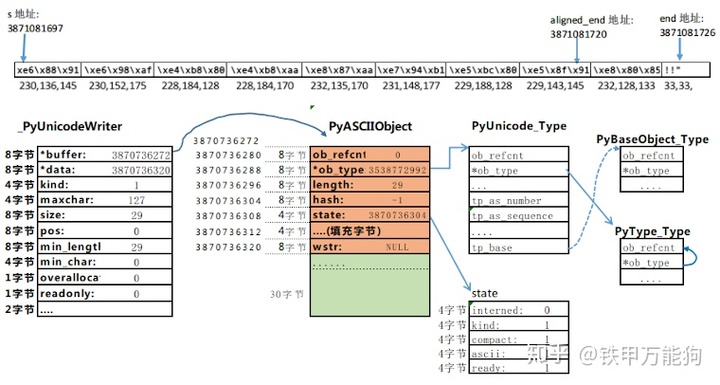
咦?_PyUnicodeWriter对象的字段data刚好指向ascii_decode返回所指向的内存地址,即整个PyASCIIOjbect的头部尾端的最后一个字节。
static Py_ssize_t
ascii_decode(const char *start, const char *end, Py_UCS1 *dest)
{
const char *p = start;
const char *aligned_end = (const char *) _Py_ALIGN_DOWN(end, SIZEOF_LONG);
....
}重点就在_Py_ALIGN_DOWN这个宏定义,将传入的指针p向下舍入到最接近以a对齐的地址边界,该地址边界不大于p,你姑且先不要深挖CPython为什么要这么做。
/* Round pointer "p" down to the closest "a"-aligned address <= "p". */
#define _Py_ALIGN_DOWN(p, a) ((void *)((uintptr_t)(p) & ~(uintptr_t)((a) - 1)))扯远了,回归正题。整个_PyUnicodeWriter_函数族大规模地引用了以下宏函数,所以理解这些宏函数对于你大脑梳理字符串对象初始化过程以及字符串各种操作的细节至关重要。
/* Fast check to determine whether an object is ready. Equivalent to
PyUnicode_IS_COMPACT(op) || ((PyUnicodeObject*)(op))->data.any) */
#define PyUnicode_IS_READY(op) (((PyASCIIObject*)op)->state.ready)
#define PyUnicode_Check(op)
PyType_FastSubclass(Py_TYPE(op), Py_TPFLAGS_UNICODE_SUBCLASS)
/* Return true if the string is compact or 0 if not.
No type checks or Ready calls are performed. */
#define PyUnicode_IS_COMPACT(op)
(((PyASCIIObject*)(op))->state.compact)
/* Return a void pointer to the raw unicode buffer. */
#define _PyUnicode_COMPACT_DATA(op)
(PyUnicode_IS_ASCII(op) ?
((void*)((PyASCIIObject*)(op) + 1)) :
((void*)((PyCompactUnicodeObject*)(op) + 1)))
#define _PyUnicode_NONCOMPACT_DATA(op)
(assert(((PyUnicodeObject*)(op))->data.any),
((((PyUnicodeObject *)(op))->data.any)))
/* Return one of the PyUnicode_*_KIND values defined above. */
#define PyUnicode_KIND(op)
(assert(PyUnicode_Check(op)),
assert(PyUnicode_IS_READY(op)),
((PyASCIIObject *)(op))->state.kind)
/* Returns the length of the unicode string. The caller has to make sure that
the string has it's canonical representation set before calling
this macro. Call PyUnicode_(FAST_)Ready to ensure that. */
#define PyUnicode_GET_LENGTH(op)
(assert(PyUnicode_Check(op)),
assert(PyUnicode_IS_READY(op)),
((PyASCIIObject *)(op))->length)
#define PyUnicode_DATA(op)
(assert(PyUnicode_Check(op)),
PyUnicode_IS_COMPACT(op) ? _PyUnicode_COMPACT_DATA(op) :
_PyUnicode_NONCOMPACT_DATA(op))
//位于Includes/object.h
static inline int
PyType_HasFeature(PyTypeObject *type, unsigned long feature) {
return ((PyType_GetFlags(type) & feature) != 0);
}
//位于Includes/object.h
#define PyType_FastSubclass(type, flag) PyType_HasFeature(type, flag)
/* Return a maximum character value which is suitable for creating another
string based on op. This is always an approximation but more efficient
than iterating over the string. */
#define PyUnicode_MAX_CHAR_VALUE(op)
(assert(PyUnicode_IS_READY(op)),
(PyUnicode_IS_ASCII(op) ?
(0x7f) :
(PyUnicode_KIND(op) == PyUnicode_1BYTE_KIND ?
(0xffU) :
(PyUnicode_KIND(op) == PyUnicode_2BYTE_KIND ?
(0xffffU) :
(0x10ffffU)))))
/* Returns the length of the unicode string. The caller has to make sure that
the string has it's canonical representation set before calling
this macro. Call PyUnicode_(FAST_)Ready to ensure that. */
#define PyUnicode_GET_LENGTH(op)
(assert(PyUnicode_Check(op)),
assert(PyUnicode_IS_READY(op)),
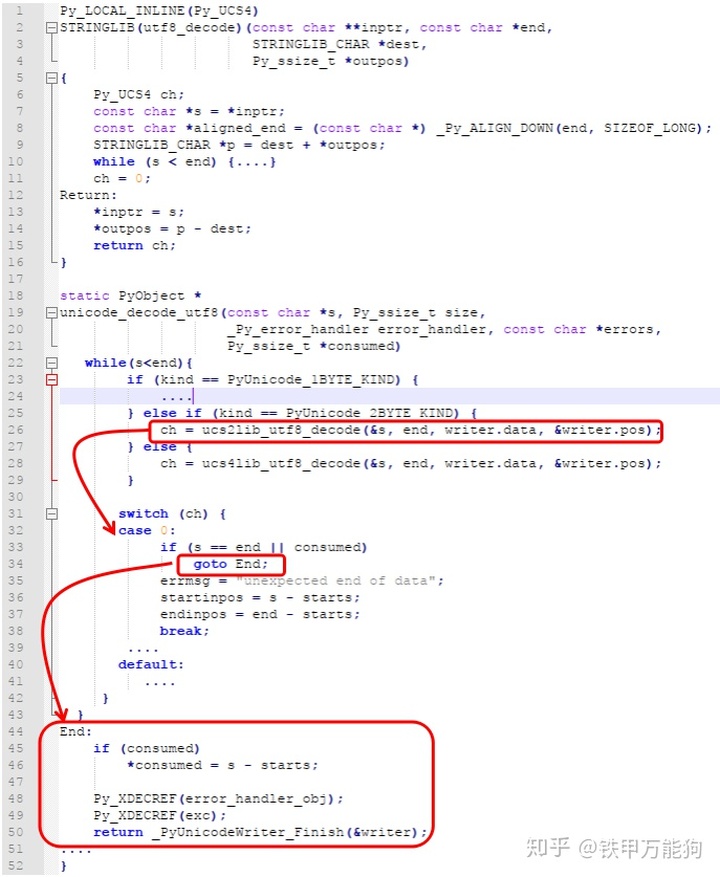
((PyASCIIObject *)(op))->length)当执行完_PyUnicodeWriter_InitWithBuffer的相关代码后,我们将注意力回到unicode_decode_utf8剩下剩下尚未展示的代码片段,源代码见Objects/unicodeobject.c文件的第5020行-5034行,该代码片段通过while循环遍历参数s的C级别unicode字节序列。并通过unicode字节宽度来选择调用对应的XX_utf8_decode函数执行解码操作。
unicode_decode_utf8(const char *s, Py_ssize_t size,
_Py_error_handler error_handler, const char *errors,
Py_ssize_t *consumed)
...
writer.pos = s - starts;
Py_ssize_t startinpos, endinpos;
const char *errmsg = "";
PyObject *error_handler_obj = NULL;
PyObject *exc = NULL;
while (s < end) {
Py_UCS4 ch;
int kind = writer.kind;
if (kind == PyUnicode_1BYTE_KIND) {
if (PyUnicode_IS_ASCII(writer.buffer)){
ch = asciilib_utf8_decode(&s, end, writer.data, &writer.pos);
}
else{
ch = ucs1lib_utf8_decode(&s, end, writer.data, &writer.pos);
}
} else if (kind == PyUnicode_2BYTE_KIND) {
ch = ucs2lib_utf8_decode(&s, end, writer.data, &writer.pos);
} else {
assert(kind == PyUnicode_4BYTE_KIND);
ch = ucs4lib_utf8_decode(&s, end, writer.data, &writer.pos);
}
....
}
}其中的asciilib_utf8_decode函数、ucs1lib_utf8_decode函数、ucs2lib_utf8_decode函数和ucs4lib_utf8_decode函数,它们的函数实体由如下函数签名定义。由于该函数200多行,我没打算在本篇罗列,其详细代码位于Objects/stringlib/codecs.h源文件的第22行-253行。该函数签名带有宏名称的定义,也就是说会在编译时,生成各自函数名对应的函数副本。
Py_LOCAL_INLINE(Py_UCS4) STRINGLIB(utf8_decode)(
const char**,
const char*,
STRINGLIB_CHAR*,
Py_ssize_t*)从上面的_PyUnicodeWriter对象的内存图可知,因为变量kind=1,它会调用asciilib_utf8_decode函数,在while中的ch一个char变量,初始值ch=230,即指向C级别unicode字节序列的起始位置.
Py_LOCAL_INLINE(Py_UCS4) STRINGLIB(utf8_decode)(
const char** inptr,
const char* end,
STRINGLIB_CHAR* dest,
Py_ssize_t* outpos){
Py_UCS4 ch;
const char *s = *inptr;
const char *aligned_end = (const char *) _Py_ALIGN_DOWN(end, SIZEOF_LONG);
STRINGLIB_CHAR *p = dest + *outpos;
while(s<end){
ch=(unsigned char)*s; //230
if(ch<0x80){ //0x80=128
.....
}
if(ch<0xE0){ //0xe0=224
.....
}
if(ch<0xF0){//0x=240
/* xE0xA0x80-xEFxBFxBF -- 0800-FFFF */
Py_UCS4 ch2, ch3;
if (end - s < 3) {
/* unexpected end of data: the caller will decide whether
it's an error or not */
if (end - s < 2)
break;
ch2 = (unsigned char)s[1];
if (!IS_CONTINUATION_BYTE(ch2) ||
(ch2 < 0xA0 ? ch == 0xE0 : ch == 0xED))
/* for clarification see comments below */
goto InvalidContinuation1;
break;
}
ch2 = (unsigned char)s[1];
ch3 = (unsigned char)s[2];
if (!IS_CONTINUATION_BYTE(ch2)) {
/* invalid continuation byte */
goto InvalidContinuation1;
}
if (ch == 0xE0) {
if (ch2 < 0xA0)
/* invalid sequence
xE0x80x80-xE0x9FxBF -- fake 0000-0800 */
goto InvalidContinuation1;
} else if (ch == 0xED && ch2 >= 0xA0) {
/* Decoding UTF-8 sequences in range xEDxA0x80-xEDxBFxBF
will result in surrogates in range D800-DFFF. Surrogates are
not valid UTF-8 so they are rejected.
See https://www.unicode.org/versions/Unicode5.2.0/ch03.pdf
(table 3-7) and http://www.rfc-editor.org/rfc/rfc3629.txt */
goto InvalidContinuation1;
}
if (!IS_CONTINUATION_BYTE(ch3)) {
/* invalid continuation byte */
goto InvalidContinuation2;
}
ch = (ch << 12) + (ch2 << 6) + ch3 -
((0xE0 << 12) + (0x80 << 6) + 0x80);
assert ((ch > 0x07FF) && (ch <= 0xFFFF));
s += 3;
if (STRINGLIB_MAX_CHAR <= 0x07FF ||
(STRINGLIB_MAX_CHAR < 0xFFFF && ch > STRINGLIB_MAX_CHAR))
/* Out-of-range */
goto Return;
*p++ = ch;
continue;
}
if(ch<0xF5){
....
}
goto InvalidStart;
}
ch=0;
Return:
*inptr = s;
*outpos = p - dest;
return ch;
InvalidStart:
ch = 1;
goto Return;
InvalidContinuation1:
ch = 2;
goto Return;
InvalidContinuation2:
ch = 3;
goto Return;
InvalidContinuation3:
ch = 4;
goto Return;
}仅当if(ch<0xF0)语句块内的代码执行完成后,此时变量ch=25105,该ch变量由asciilib_utf8_decode函数会返回给unicode_decode_utf8函数,s指针已经偏移至s+=3的位置,即指向字节xe6,如下内存图所示
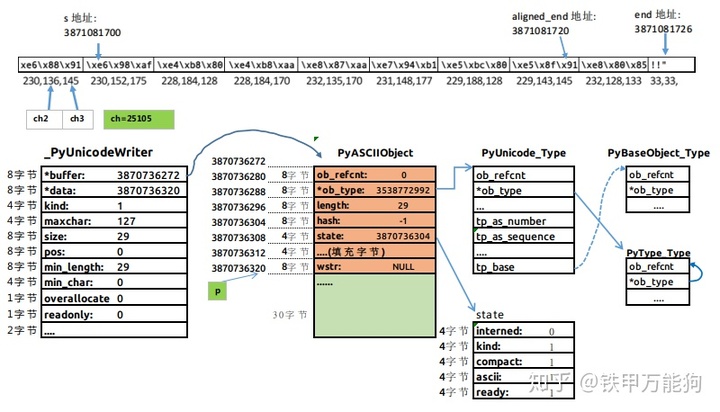
接下来,ch=25105传递到switch/case语句块,很明显这里直接执行default的分支中的_PyUnicodeWriter_WriteCharInline,这是一个宏函数,其实质函数主体为_PyUnicodeWriter_PrepareInternal。
unicode_decode_utf8(const char *s, Py_ssize_t size,
_Py_error_handler error_handler, const char *errors,
Py_ssize_t *consumed)
switch (ch) {
case 0:
.....
case 1:
.....
case 2:
.....
case 3:
case 4:
.....
default:
if (_PyUnicodeWriter_WriteCharInline(&writer, ch) < 0)
goto onError;
continue;
}
.....
}
static inline int
_PyUnicodeWriter_WriteCharInline(_PyUnicodeWriter *writer, Py_UCS4 ch)
{
assert(ch <= MAX_UNICODE);
if (_PyUnicodeWriter_Prepare(writer, 1, ch) < 0)
return -1;
PyUnicode_WRITE(writer->kind, writer->data, writer->pos, ch);
writer->pos++;
return 0;
}
/* Prepare the buffer to write 'length' characters
with the specified maximum character.
Return 0 on success, raise an exception and return -1 on error. */
#define _PyUnicodeWriter_Prepare(WRITER, LENGTH, MAXCHAR)
(((MAXCHAR) <= (WRITER)->maxchar
&& (LENGTH) <= (WRITER)->size - (WRITER)->pos)
? 0
: (((LENGTH) == 0)
? 0
: _PyUnicodeWriter_PrepareInternal((WRITER), (LENGTH), (MAXCHAR))))
int
_PyUnicodeWriter_PrepareInternal(_PyUnicodeWriter *writer,
Py_ssize_t length, Py_UCS4 maxchar)
{
Py_ssize_t newlen;
PyObject *newbuffer;
assert(maxchar <= MAX_UNICODE);
/* ensure that the _PyUnicodeWriter_Prepare macro was used */
assert((maxchar > writer->maxchar && length >= 0)
|| length > 0);
if (length > PY_SSIZE_T_MAX - writer->pos) {
PyErr_NoMemory();
return -1;
}
newlen = writer->pos + length;
maxchar = Py_MAX(maxchar, writer->min_char);
if (writer->buffer == NULL) {
.....
}
else if (newlen > writer->size) {
.....
}
else if (maxchar > writer->maxchar) {
assert(!writer->readonly);
newbuffer = PyUnicode_New(writer->size, maxchar);
if (newbuffer == NULL)
return -1;
_PyUnicode_FastCopyCharacters(newbuffer, 0,
writer->buffer, 0, writer->pos);
Py_SETREF(writer->buffer, newbuffer);
}
_PyUnicodeWriter_Update(writer);
return 0;
#undef OVERALLOCATE_FACTOR
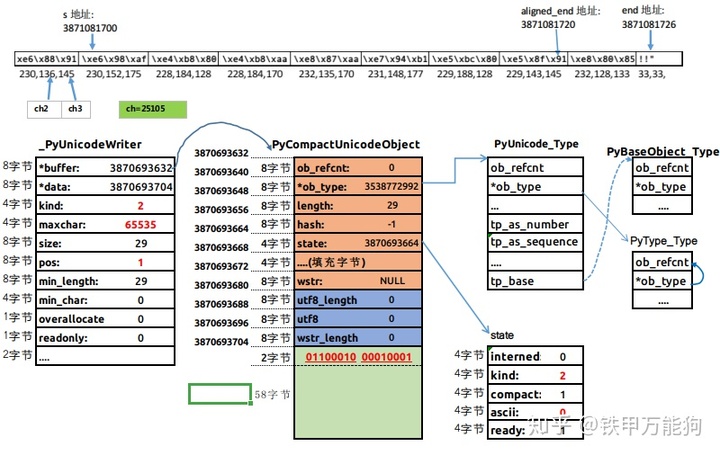
}在执行_PyUnicodeWriter_PrepareInternal函数时很明显执行else if (maxchar > writer->maxchar)语句块内的代码,在本示例再次执行PyUnicode_New函数重新分配内存并返回一个全新的PyASCIIObject对象,它由临时变量newbuffer托管。在未执行_PyUnicode_FastCopyCharacters函数之前,其内存状态如下
在执行_PyUnicode_FastCopyCharacters函数时,由于参数PyUnicodeWriter对象的pos字段仍然为0,那么它调用的_copy_characaters函数的how_many参数就是writer->pos=0传递过去的副本。这决定本示例中_copy_characters函数并不会执行实际的拷贝操作,而是立即返回_PyUnicode_FastCopyCharacters函数。
void
_PyUnicode_FastCopyCharacters(
PyObject *to, Py_ssize_t to_start,
PyObject *from, Py_ssize_t from_start, Py_ssize_t how_many)
{
(void)_copy_characters(to, to_start, from, from_start, how_many, 0);
}从_PyUnicodeWriter_WriteCharInline函数在返回前会调用PyUnicode_WRITE宏函数,从上面的内存状态图可知kind参数是2,data参数就是writer->data,index参数就是writer->pos=0,value参数就是ch=25105。我们分析一下这里发生什么。
- 首先,PyUnicode_WRITE中会执行case PyUnicode_2BYTE_KIND的代码分支。
- 然后,向PyCompactUnicode对象的data字段区域的首两个字节写入25105这个值。就是((Py_UCS2 *)(data))[(index)] = (Py_UCS2)(value)这条语句所做的事情。完整的代码如下所示
#define PyUnicode_WRITE(kind, data, index, value)
do {
switch ((kind)) {
case PyUnicode_1BYTE_KIND: {
assert((kind) == PyUnicode_1BYTE_KIND);
((Py_UCS1 *)(data))[(index)] = (Py_UCS1)(value);
break;
}
case PyUnicode_2BYTE_KIND: {
assert((kind) == PyUnicode_2BYTE_KIND);
((Py_UCS2 *)(data))[(index)] = (Py_UCS2)(value);
break;
}
default: {
assert((kind) == PyUnicode_4BYTE_KIND);
((Py_UCS4 *)(data))[(index)] = (Py_UCS4)(value);
}
}
} while (0)那么执行完PyUnicode_WRITE宏函数的相关代码后的内存状态,如下图所示。
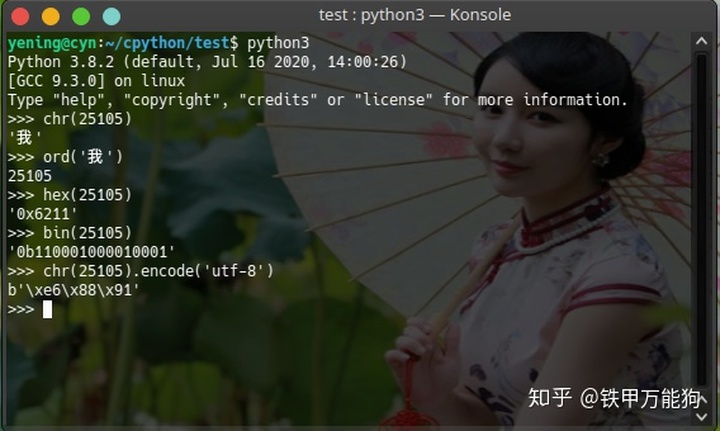
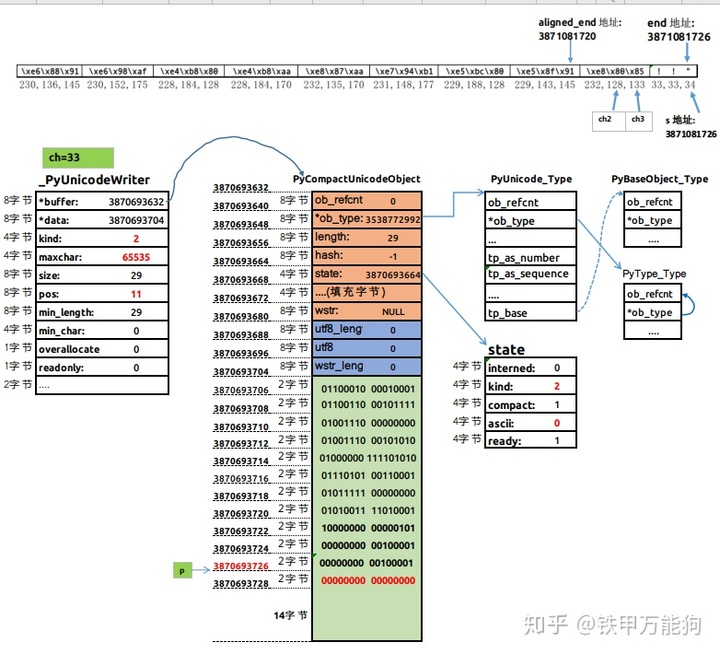
你可能会疑问ch=25105还不知道表示什么意思,这个我们用Python的chr函数和ord函数,你就一目了然啦。显然十进制的25105,十六进制0x6211,二进制的"01100010 00010001"和utf-8编码形式的x36x88x91都表示中文字"我"
当_PyUnicodeWriter_WriteCharInline执行完成后,并返回到unicode_decode_utf8函数的while循环的上下文。到这里C级别的char指针s已经指向unicode字节序列中s[3]的位置,并且已经将字符串中“我是一个自由开发者”的第一个汉字以2个字节的形式写入PyCompactUnicodeObject对象的data指针所指向的60字节内存区域的起始两个字节的内存空间。
从当前的内存图可知,PyCompactUnicodeObject对象的kind=2,这次的unicode_decode_utf8函数会调用ucs2lib_utf8_decode函数,CPU控制权落在ucs2lib_utf8_decode函数内的while循环执行主要执行if(ch<0xF0)条件语句块内的代码,并且在每次循环偏移char指针s,直到s到达end指针的位置。
- 首先,unsigned char类型的局部变量ch、ch2、ch3,分别在每次遍历过程中托管s、s+1、s+2对应位置的字节数据,我们s、s+1、s+3分别指向三个字节就表示一个utf-8编码的汉字,最后2字节表示的unicode编码值。
- 然后 执行下面这条语句,事实上完成utf-8编码到unicode编码这个转换操作。
ch = (ch << 12) + (ch2 << 6) + ch3 -((0xE0 << 12) + (0x80 << 6) + 0x80);- 最后,将ch变量保存的2字节位宽的unicode编码值拷贝到指针p指向PyCompactUnicode对象的data字段所指向的内存区域,拷贝完成后,p指针向data内存区域的高地址偏移一次。
*p++=ch
continue
我们用一个内存状态图的gif动画来展示一下ucs2lib_utf8_decode函数内部while循环如何从C级别的字节序列将数据拷贝到PyCompactUnicode对象的data内存区域。

当s指针偏移至end指针,跳出ucs2lib_utf8_decode内部整个while循环,并且会将循环后的ch=0返回给上一层unicode_decocde_utf8函数,你应该已经想到ch=0其实就是作为整个字符串的结束字符NULL或'0
'或拷贝到PyUnicodeCompact对象的data内存区域,也就是data[s.length-1]的位置。
我们本示例的中文字字符串在CPython内部初始化后的内存图如下图,之前说过_PyUnicodeWriter对象是基于栈的,当整个基于unicode_decode_utf8的函数栈销毁前,_PyUnicodeWriter_Finish函数需要将_PyUnicodeWriter对象托管的PyASCIIObject或其子类返回给外部的Python代码,随之_PyUnicodeWriter对象就跟随unicode_decode_utf8的函数栈一起销毁。
我们分析发现整个PyASCIIObject/PyUnicodeObject的初始化整个过程。一个简单的字符串对象,经历千辛万苦的函数调用地狱。
整个PyASCIIObject/PyUnicodeObject对象初始化过程,实际上是对C级别char指针所指向的字节序列执行解码和拷贝序列中字节数据到其PyASCIIObject对象或及其子类对象的包装过程。这个过程。涉及1到3次不等的malloc函数内存分配。为什么呢?
CPython会首先假定传入的C级别字节序列是一个简单ASCII字节序列。因此第一次按照PyUnicode_1BYTE_KIND的模式去计算字符串所需的堆内存空间。而后续的字节编码检测算法发现该C级别的字节序列并非是一个ASCII字节序列,就会尝试以PyUnicode_2BYTE_KIND的模式,再次从算内存空间并调用malloc分配函数。这意味着,很明显吧,之前的malloc分配的内存做了"无用功"。请问这样能字符串初始化的性能高效个锤子啊~!!.














 1164
1164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









