






 本文介绍如何在Word文档中自动合并上下行内容相同的表格单元格,详细阐述了处理Word表格的步骤,包括读取数据、判断合并条件、合并单元格以及处理合并后的内容重复问题。通过Python实现这一功能,适用于自动化办公场景。
本文介绍如何在Word文档中自动合并上下行内容相同的表格单元格,详细阐述了处理Word表格的步骤,包括读取数据、判断合并条件、合并单元格以及处理合并后的内容重复问题。通过Python实现这一功能,适用于自动化办公场景。
实例28讲了如何在Excel文件中自动合并上下行相同内容的单元格,此例则讲一讲如何在Word文件中做类似的操作。因为处理Excel和Word的模块是不同的,所以合并单元格也有一些差异。相对来说,Word中的操作更麻烦一些。
在Excel中,我们手动合并单元格后,合并的单元格中只保留1个值,而Word则全部保留。比如在word中,3个单元格的内容都是“ABC”,合并之后就变成了“ABCABCABC”,这显然不是我们想要的。下图是原始文档,要求将第2列和第3列中,上下相邻单元格内容一样的合并。
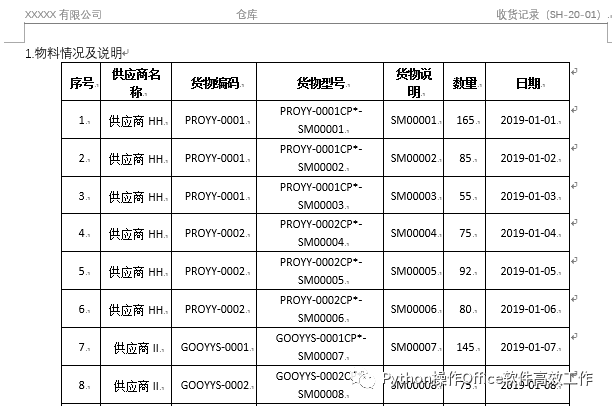
还是先定义合并单元格函数,以便后续多次调用。由于处理Word中表格的代码与处理Excel不同,所以函数也要做微调。主要变化就是合并的函数表达,对于word中的表格,表达式是table.cell(row1,col1).merge(table.cell(row2,col2)),意思是将第row1行col1列到row2行col2列之间的表格合并(row2,col2要分别大于等于row1和col1)。需要注意的是cell(0,0)表示第一行第一列的单元格,以此类推。如下函数是在例28的基础上修改的。
#定义合并单元格的函数
def Merge_cells(table,target_list,start_row,col):
''' table: 是需要操作的表格 target_list: 是目标列表,即含有重复数据的列表 start_row: 是开始行,即表格中开始比对数据的行(需要将标题除开) col: 是需要处理数据的列 '''
start = 0 #开始行计数
end = 0 #结束行计数
reference = target_list[0] #设定基准,以列表中的第一个字符串开始
for i in range(len(target_list)): #遍历列表
if target_list[i] != reference: #开始比对,如果内容不同执行如下
reference = target_list[i] #基准变成列表中下一个字符串
end = i - 1
table.cell(start+start_row,col).merge(table.cell(end+start_row,col))
start = end + 1
if i == len(target_list) - 1: #遍历到最后一行,按如下操作
end = i
table.cell(start+start_row,col).merge(table.cell(end+start_row,col))然后需要读取word中相应表格里的数据,并提取出来,以便作为是否合并的判断基础。使用Document打开word文档,先查看一下其中表格的个数,以便我们锁定要处理的表格。由于word里面可能有隐藏表格,或者一个表格中有一段去掉了边框,让人看起来像是两个表格,直接在word中去数表格个数有时会不靠谱。
通过len(doc.tables)看到,这个文档里面有2个表格。打开word文档,我们可以看到要处理的表格是第一个,即doc.tables[0]。如果情况较为复杂,我们可以打印表格中第一行单元格的内容进一步确认是否是我们需要处理的表格。确认好表格的序号后,就可以开始读取内容了。
from docx import Document
doc = Document("收货记录.docx")
print("这个工作表有 {} 个表格。\n".format(len(doc.tables))) #查看表格中的个数,以便锁定我们要处理的表格
print("第一个表格的第一行的单元格中的内容如下:")
for i in doc.tables[0].rows[0].cells: #读取第一个表格的第一行的单元格中的内容
print(i.text)
》
这个工作表有 2 个表格。
第一个表格的第一行的单元格中的内容如下:
序号
供应商名称
货物编码
货物型号
货物说明
数量
日期
#读取word文档中的第一个表格的第二和第三列除标题和尾部总数行的数据
doc = Document("收货记录.docx")
table = doc.tables[0] #已确定是第一个表格,其索引是0
supplier = [] #存储供应商名称
pn = [] #存储物料编码
max_row = len(table.rows) #获取最大一行
print("表格共有{}行".format(max_row))
#读取第二行到29行,第2,3列中的数据
for i in range(1,max_row-1):
supplier_name = table.rows[i].cells[1].text #cells[1]指表格第二列
supplier.append(supplier_name)
for i in range(1,max_row-1):
material_pn = table.rows[i].cells[2].text #cells[2]指表格第三列
pn.append(material_pn)
print("获取到{}个供应商名称,{}个物料编码。".format(len(supplier),len(pn)))
>>
表格共有30行
获取到28个供应商名称,28个物料编码。以上程序,获取了表格中第2列和第3列的数据,并存入了列表supplier和pn。然后就可以开始判断,并合并单元格了。下面调用之前定义好的函数Merge_cells,传入相应的参数,运行即可完成单元格合并。
Merge_cells(table,supplier,1,1) #开始合并行为2,索引为1;供应商名称是在2列,索引为1
Merge_cells(table,pn,1,2) #开始合并行为2,索引为1;物料编码是在3列,索引为2
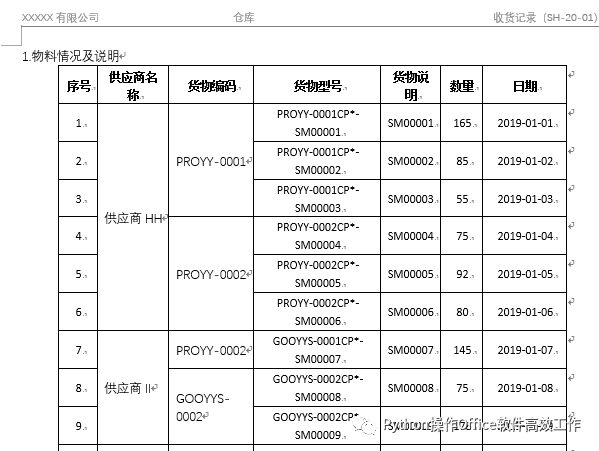
doc.save("检查.docx")到这一步,合并单元格算是完成了,但结果如下图所示,原单元格中的内容全部集中在一起,造成了重复内容。我们需要重写这些单元格以覆盖掉重复的内容,即可得到我们想要的结果。

#重新往第2和第3列写入数据,以覆盖之前重复的数据
for row in range(1,len(supplier)+1):
table.cell(row,1).text = supplier[row-2]
table.cell(row,2).text = pn[row-2]
doc.save("收货记录-合并单元格.docx")为什么写入合并单元格的时候,也是将合并之前的每个单元格都写了一次(比如写入“供应商HH”到第二行第1到6列的时候,写入了6次),为什么不会造成重复内容呢?是因为每写一次,就将原来的内容清空了。最终结果如下,目标达成!
如果您有需要处理的问题,可发邮件到我邮箱:donyo@qq.com,一起探讨解决方案。
以上在Jupyter notebook上完成,所用到的代码及Excel 资料已上传GitHub及百度网盘, 欢迎下载到本地随意玩。
Python版本:Python 3.6 64bit
操作系统:Windows 7
GitHub:Office_Automation_by_Using_Python
百度Pan:“pan.baidu”加上“.com/s/1WXcoYts_uNJmccfJ0lrmWg” 提取码: kry7
知乎:Python操作Office软件高效工作

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









