







简介:Prometheus是一个开源监控和警报系统,专门设计用于云原生环境,强调简单性、高可用性与自动化。它具有强大的查询语言和灵活的警报管理功能,并提供与Grafana的集成。版本2.17.1带来了性能优化和新特性。本文将引导您通过下载和解压特定版本的Prometheus来安装和部署,以及解释其核心组件、数据模型、查询语言、服务发现和警报处理机制,同时提供最佳实践来确保监控系统的有效性和效率。 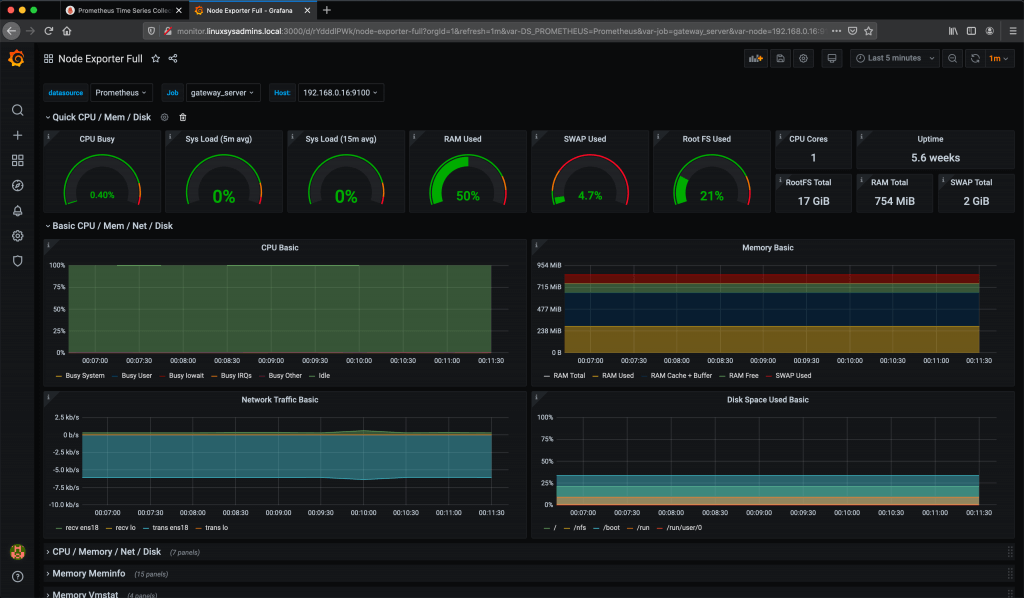
1. Prometheus系统架构与组件
1.1 Prometheus的架构概述
Prometheus是一个开源的系统监控和警报工具包,具有高可靠性和易于使用的特性。它的架构设计简单,易于扩展和集成到复杂的环境中。Prometheus通过使用pull模型来从各个目标上收集时间序列数据,支持服务发现,并能够存储收集的数据,以用于历史数据的查询和分析。
1.2 核心组件解析
1.2.1 Prometheus Server
Prometheus Server是整个监控系统的中心,负责收集和存储数据。它定期从配置好的目标中抓取(scrape)指标数据,并对抓取到的数据进行处理和存储。Prometheus Server使用独立的时序数据库来存储这些数据,并提供了PromQL(Prometheus Query Language)查询语言,允许用户对数据进行查询和分析。
1.2.2 Pushgateway
Pushgateway是Prometheus的一个辅助组件,主要用于处理短生命周期的任务的监控数据。在某些情况下,客户端应用可能不能直接暴露端口给Prometheus Server进行数据抓取,这时可以通过Pushgateway作为中转站,将数据推送(push)到Pushgateway,再由Prometheus Server从Pushgateway拉取数据。
1.2.3 Node Exporter
Node Exporter是一个用于暴露Linux/Unix主机系统级指标的监控代理。它能够收集各种系统级别的数据,比如CPU使用率、内存使用情况、磁盘I/O等。通过在每个需要监控的节点上运行Node Exporter,Prometheus Server就可以从这些实例上抓取到主机级别的监控数据。
1.2.4 Alertmanager
Alertmanager是Prometheus生态系统中的警报管理器。它的主要作用是接收从Prometheus Server发送来的警报,对这些警报进行分组、抑制以及去重处理,并负责将它们通过邮件、webhook等方式发送给相关的责任人。Alertmanager支持多种通知渠道,提供了灵活的告警管理策略。
通过了解这些核心组件以及它们之间的交互方式,我们可以构建一个强大的监控系统,对复杂的IT环境进行高效监控。接下来的章节将深入解析每个组件的功能和应用。
2. Prometheus数据模型和时间序列数据库
2.1 时间序列基础
2.1.1 时间序列的定义
在监控系统中,时间序列是一个基本的数据结构,通常用于存储和表示随时间变化的度量值。每个时间序列由一系列数据点组成,每个点都有一个时间戳和一个对应于该时间点的值。在Prometheus中,时间序列的数据点是按照时间顺序连续存储的,以实现高效的查询和分析。
时间序列在Prometheus中由度量名称(metric name)和一系列的键值对标签(label pairs)来唯一标识。度量名称用于描述这个度量值的本质(例如,http_requests_total),而标签则为度量值的不同维度提供了上下文(例如,method="GET"、status="200 OK")。这种数据模型的多维特性使得Prometheus能够非常灵活地对监控数据进行查询和聚合。
2.1.2 标签与多维数据
标签是Prometheus数据模型中的一个核心概念,它允许用户对数据进行分类和过滤,从而实现对度量值的更细致管理和查询。每个标签由一个键(key)和一个值(value)组成,它们都是字符串类型。利用标签,用户可以根据业务需要定制多种标签组合,如服务名、环境类型、服务器位置等,以适应不同的查询需求。
通过标签的组合,Prometheus能够对数据进行切片和分组,实现对数据的多种维度的查询。比如,通过查询 http_requests_total{method="GET",status="200"} 可以获取所有HTTP GET请求中状态码为200的请求总数。此外,Prometheus还提供了一些内置的标签,如 __name__ (度量名称的别名),以及支持使用正则表达式进行复杂的查询。
2.2 Prometheus的数据存储
2.2.1 TSDB的原理
Prometheus使用自定义的时间序列数据库(TSDB)来存储监控数据。TSDB是专门为时序数据设计的数据库,它的底层结构是基于时间戳对数据进行排序和存储,这使得时间序列的查询效率非常高。
TSDB在内部使用块(block)来存储数据,每个块包含一定时间范围内的数据点。当数据点达到一定数量时,这些点就会被写入一个不可变的块中,并且该块被压缩以节省存储空间。这种设计不仅优化了存储效率,还使得数据压缩后更加适合进行高效查询。
2.2.2 数据保留和压缩
在Prometheus中,数据保留策略是通过配置文件中的 retention 参数来设置的。它定义了数据保留的最长时间。超出这个时间范围的数据会被自动清理,以避免消耗过多的存储空间。
压缩是TSDB的另一个关键特性。Prometheus使用一种称为“段”(segment)的机制来管理压缩的数据。每个段都是一个包含多个块的文件,这些块都是按时间顺序排列的。在查询时,Prometheus可以高效地遍历这些段,以检索出需要的数据点。由于数据被压缩存储,因此段文件的大小要远小于原始数据的大小,这显著提高了数据的存储效率。
2.3 数据模型的高级应用
2.3.1 使用Histograms和Summaries
Prometheus的数据模型支持两种高级数据类型:Histograms和Summaries。这些高级数据类型是为了支持更复杂的监控需求而设计的,例如统计服务的响应时间分布或计算服务请求的百分比。
Histograms允许用户跟踪数值数据的分布情况,例如,通过记录每个区间(bucket)内的样本数量,用户可以轻松地计算出请求的百分比或者获取数值数据的分布直方图。而Summaries则提供了记录事件数值的总和和数量的另一种方式,它们可以用来计算事件的平均值和标准差。
2.3.2 数据模型的实践案例分析
让我们来看一个实践案例:假设我们有一个网络服务,并希望监控它的响应时间。为了更好地了解响应时间的分布情况,我们可以使用Histogram数据类型。设置一个Histogram,指定不同大小的区间来记录响应时间。
histogram_quantiles:
- 0.95
- 0.99
http_request_duration_seconds_bucket{le="1.0"}
http_request_duration_seconds_bucket{le="2.0"}
http_request_duration_seconds_bucket{le="+Inf"}
http_request_duration_seconds_sum
http_request_duration_seconds_count
在这个Histogram中,我们有多个 le (less than or equal)标签,它们定义了响应时间的区间。每个区间内的样本数量由 http_request_duration_seconds_bucket 指标表示。另外,我们还可以通过 http_request_duration_seconds_sum 和 http_request_duration_seconds_count 来计算出响应时间的总和和数量。
通过这种方式,我们不仅可以获取响应时间的分布情况,还能得到响应时间的聚合信息。例如,我们可以使用 histogram_quantiles 函数来计算95%和99%的响应时间分位数,这对于衡量服务的性能和制定监控告警策略非常有帮助。
histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket[5m])) by (le))
上述PromQL查询计算了过去5分钟内,95%的请求响应时间。这里,我们使用了 rate 函数来计算每秒的增加速率,并通过 sum 函数对所有的区间进行了聚合计算,以获取整体的95%分位数。
通过这些高级数据模型的应用,Prometheus的用户能够获得比基本计数器和计量器更为丰富和深入的业务洞察。
3. PromQL查询语言功能与应用
3.1 PromQL基础语法
3.1.1 数据查询基础
PromQL(Prometheus Query Language)是Prometheus提供的强大查询语言,用于查询和处理时间序列数据。在Prometheus中,所有的数据都是以时间序列的形式存储的,每个时间序列由指标名称和一组键值对标签组成。
查询时间序列数据时,PromQL语句的基本结构是:
<metric_name>{<labelMatchers>}
这里 <metric_name> 是指标名称,而 <labelMatchers> 是标签匹配器,可以有多个,用逗号分隔。
例如,查询 http_requests_total 这个指标的全部时间序列可以使用如下查询:
http_requests_total
查询包含特定标签的数据时,可以使用 = 和 != 来匹配特定的值,或者使用 =~ 和 !~ 进行正则匹配:
http_requests_total{job="prometheus"}
http_requests_total{job=~"prometheus|node_exporter"}
此外,为了查询特定的时间范围内的数据,可以使用范围选择器 [] :
http_requests_total[5m]
此语句表示查询过去5分钟内的 http_requests_total 时间序列数据。
3.1.2 时间序列的选择与过滤
时间序列的选择和过滤是监控系统中常见的需求。在PromQL中,可以通过多种方式选择和过滤时间序列数据:
使用 offset 关键字可以获取某个时间点的历史数据:
http_requests_total offset 1h
此语句会返回1小时前的 http_requests_total 数据。
使用聚合函数如 sum() 、 avg() 、 min() 、 max() 和 count() 可以对一组时间序列执行聚合运算。例如,计算所有HTTP请求的总量:
sum(http_requests_total)
通过 group_left 或 group_right 来实现分组聚合:
sum by (job) (http_requests_total)
使用花括号 {} 来匹配多个标签:
http_requests_total{method="GET", job="prometheus"}
利用 or 、 and 和 unless 关键字进行逻辑运算:
http_requests_total{status="200"} or http_requests_total{status="300"}
这些查询示例展示了如何在PromQL中对时间序列数据进行选择和过滤。掌握这些基础操作后,可以对监控数据进行更复杂的分析。
3.2 PromQL高级特性
3.2.1 函数与聚合操作
PromQL提供了丰富的内置函数,以支持对时间序列数据的复杂处理。这些函数包括统计学函数、数学函数、时间函数等。
例如,要计算HTTP请求的平均响应时间,我们可以使用如下查询:
avg by (method) (rate(http_response_time_seconds[5m]))
这里使用了 rate 函数来获取每秒的HTTP响应时间,并通过 avg 聚合函数计算平均值。
时间相关的函数如 time() 、 timestamp() 可以用来获取当前时间或时间序列的最新时间戳。
数学函数如 exp() , log() , sqrt() 等可以用来进行数学运算。
字符串处理函数如 strContains() , strReplace() 等在处理包含文本标签的时间序列数据时非常有用。
3.2.2 范围查询与子查询
范围查询是PromQL中非常重要的特性之一,允许用户查询某个时间范围内的数据快照。例如,获取过去一小时内的HTTP请求总数可以使用:
http_requests_total[1h]
子查询允许在查询中嵌套另一个查询语句。这在需要从一个查询的结果中获取数据并用其作为另一个查询的输入时非常有用。例如:
increase(http_requests_total[5m])[5m:]
这里, increase(http_requests_total[5m]) 是一个子查询,它计算了过去5分钟内HTTP请求的增量,然后我们取这个增量的5分钟平均值。
3.3 PromQL在监控中的应用
3.3.1 编写复杂查询实例
在实际监控中,我们经常需要编写复杂的查询来提取有意义的监控指标。例如,如果我们想要找出在特定时间范围内响应时间超过500毫秒的所有HTTP请求,可以使用如下查询:
http_response_time_seconds > 0.5
这个查询会返回所有 http_response_time_seconds 大于0.5秒的时间序列数据。
进一步地,如果我们需要监控不同HTTP方法的请求成功率,可以编写如下查询:
sum(rate(http_requests_total{status="200"}[5m])) / sum(rate(http_requests_total[5m]))
这个查询首先计算每秒成功状态的HTTP请求数量,然后除以总的请求数量,得到成功率。
3.3.2 监控告警规则的定义
告警规则定义是监控系统中的关键任务。在Prometheus中,我们可以定义告警规则,当监控数据触发特定条件时产生告警。
告警规则定义文件通常包含一个或多个规则,每个规则由一组表达式和一些参数组成,例如:
groups:
- name: example
rules:
- alert: HighRequestLatency
expr: job:increase(http_request_total{code="200"}[5m]) > 100
for: 10m
labels:
severity: page
annotations:
summary: High request latency
在这个例子中,我们定义了一个名为 HighRequestLatency 的告警规则,当 http_request_total 指标(成功请求)在过去5分钟内增长超过100次时,这个告警会在10分钟后触发。告警的严重性级别标记为 page ,并且告警信息中会包含一个摘要: High request latency 。
这个告警规则的定义表明,通过PromQL,我们可以非常灵活地定义各种复杂条件的监控告警,从而让监控系统更智能地响应各种运营状况。
4. Prometheus服务发现机制
4.1 服务发现机制概述
Prometheus作为一个现代的监控系统,其强大的服务发现机制是其核心特性之一。服务发现允许Prometheus动态地发现它需要监控的目标,无需手动配置每一个监控项。通过服务发现,Prometheus可以自动检测和监控新的服务实例,这在大规模动态环境(例如Kubernetes)中尤为重要。
服务发现机制通常基于如下两种模型:
- Pull模型 :Prometheus定期从配置的发现端点拉取数据。这种模型适用于Prometheus能够直接访问目标系统的场景。
- Push模型 :目标系统主动将指标数据推送到一个Pushgateway,然后Prometheus从Pushgateway拉取数据。这适用于短暂的任务或网络隔离的服务。
Prometheus支持多种服务发现方式,包括基于文件的服务发现、Kubernetes、Consul、AWS EC2等。每种方式都有其特点和适用场景,可以根据实际环境的需要进行选择和配置。
4.2 Kubernetes环境下的服务发现
4.2.1 Kubernetes自动发现配置
在Kubernetes环境下,Prometheus可以利用Kubernetes的API来发现服务和Pods。通过这种方式,Prometheus能够自动地获取集群中运行的服务实例信息,并对它们进行监控。
要设置Kubernetes自动发现,需要配置一个Kubernetes服务发现规则。这可以通过在Prometheus的配置文件中添加相应的serviceMonitor或podMonitor资源来实现。下面是一个简单的配置示例:
apiVersion: ***/v1
kind: ServiceMonitor
metadata:
name: example-monitor
labels:
k8s-app: prometheus-example
spec:
jobLabel: k8s-app
selector:
matchLabels:
k8s-app: prometheus-example
namespaceSelector:
matchNames:
- default
endpoints:
- port: http-metrics
上述配置中, ServiceMonitor 资源定义了Prometheus需要监控的目标。 selector 用于选择哪些服务会被监控, endpoints 则定义了监控的服务端点。
4.2.2 配置文件的服务发现
虽然Kubernetes提供了自动发现的便利,但在某些情况下,可能还是需要使用配置文件的方式来指定目标。这通常发生在你想要精确控制哪些目标被监控,以及如何被监控的时候。
配置文件的服务发现涉及到Prometheus配置文件中的 scrape_configs 部分。下面是一个配置文件服务发现的示例:
scrape_configs:
- job_name: 'file-based-discovery'
file_sd_configs:
- files:
- targets.json
在 targets.json 文件中,你可以列出所有需要被监控的目标,如下:
[
{
"targets": ["host1:port", "host2:port"],
"labels": {
"app": "example-app",
"env": "dev"
}
}
]
4.3 其他环境的服务发现配置
4.3.1 EC2自动发现
在AWS EC2环境中,Prometheus可以通过AWS官方提供的服务发现模块来自动发现EC2实例。这种配置方式要求Prometheus能够访问EC2的元数据API,以及安装了适当的云配置插件。
scrape_configs:
- job_name: 'ec2'
ec2_sd_configs:
- region: eu-west-1
access_key: YOUR_ACCESS_KEY
secret_key: YOUR_SECRET_KEY
port: 9100
refresh_interval: 5m
4.3.2 Azure云服务发现
对于Azure云环境,可以使用Azure云服务发现插件来自动发现服务。配置步骤类似于EC2自动发现,但需要注意的是,你需要根据Azure云的配置来填写相应的参数。
scrape_configs:
- job_name: 'azure'
azure_sd_configs:
- resource_group: YOUR_RESOURCE_GROUP
port: 9100
通过以上不同环境的服务发现配置,Prometheus能够灵活地适应各种监控需求,并实现自动化的目标发现与监控。在接下来的章节中,我们将深入了解Alertmanager的警报处理和通知机制,以及如何与Grafana集成,来完善监控系统的可视化和报警功能。
5. Alertmanager的警报处理和通知
5.1 Alertmanager功能简介
Alertmanager是Prometheus生态系统中的一个关键组件,专门用于管理和处理由Prometheus Server生成的警报。它支持警报的聚合、分组、抑制以及发送通知等功能,使得管理员能够有效地接收和响应系统中的异常情况。为了实现这些功能,Alertmanager提供了灵活的通知机制,支持多种通知渠道,如电子邮件、Slack、Webhooks等。
Alertmanager的处理流程一般从接收到警报开始,然后根据配置的路由规则来分组和抑制警报,最后通过配置的通知渠道发送警报。在整个处理过程中,Alertmanager允许用户根据需要来定义不同的通知策略和抑制规则,以达到精确的警报管理。
5.2 警报规则和路由
5.2.1 警报规则的编写
警报规则定义了当Prometheus检测到某个表达式的结果满足警报条件时,应该触发的警报。这些规则通常在Prometheus的配置文件中定义,并且可以包含多个警报配置。一个基本的警报规则如下所示:
groups:
- name: example
rules:
- alert: HighRequestLatency
expr: job:response_time:99-percentile{job="myjob"} > 1
for: 10m
labels:
severity: page
annotations:
summary: High request latency
在上述例子中,定义了一个名为 HighRequestLatency 的警报。它监控名为 myjob 的作业,并在该作业的99百分位数响应时间超过1秒时触发。 for 参数定义了警报条件需要持续一段时间(这里是10分钟)才能被触发,这有助于避免因为瞬时错误而触发警报。
5.2.2 警报分组与路由策略
Alertmanager允许对警报进行分组,这样当多个实例出现相同问题时,管理员只收到一个通知,而不是针对每个实例都接收一次。此外,路由策略允许根据不同的条件将警报分发到不同的通知渠道。路由树的配置示例如下:
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'webhook'
receivers:
- name: 'webhook'
webhook_configs:
- url: '***'
在该配置中, group_by 指定了分组的依据, group_wait 和 group_interval 分别定义了等待时间和间隔时间, repeat_interval 指定了警报重复发送的间隔时间。 receivers 定义了当警报满足路由条件时,应被发送到的接收者。
5.3 警报通知渠道
5.3.1 邮件通知配置
邮件通知是Alertmanager支持的一种通知方式,为了配置邮件通知,需要在Alertmanager的配置文件中指定SMTP服务器的相关信息以及发送邮件所需的认证信息,如下所示:
smtp_smarthost: '***:587'
smtp_from: '***'
smtp_auth_username: 'username'
smtp_auth_password: 'password'
templates:
- 'path/to/template/*.tmpl'
route:
# ... 路由规则定义 ...
receivers:
- name: 'email-notifier'
email_configs:
- to: '***'
send_resolved: true
5.3.2 Webhook与第三方通知集成
除了邮件通知,Alertmanager同样支持将警报发送到Webhook,从而集成到多种第三方通知服务中,比如企业微信、钉钉、PagerDuty等。Webhook通知的配置示例如下:
receivers:
- name: 'webhook'
webhook_configs:
- url: '***'
http_config:
authorization:
type: Bearer
credentials: 'secret-token'
在上述配置中,指定发送通知到一个Webhook地址,并且在发送请求时包含授权头信息。
通过这些警报处理和通知功能,Alertmanager极大地增强了Prometheus监控系统的健壮性与可用性,确保了系统管理员能够及时得到系统异常的通知,并采取相应的响应措施。
6. Prometheus与Grafana的集成
Grafana 是一个流行的开源数据可视化工具,常与 Prometheus 一起使用以提供更加丰富的数据展示和告警管理功能。本章将深入探讨如何将 Prometheus 与 Grafana 集成,并详细说明如何安装、配置以及创建仪表板和可视化。
6.1 Grafana基础与安装
6.1.1 Grafana的架构与功能
Grafana 是一个可扩展的开源监控解决方案,它通过图表和仪表板来展示时间序列数据。Grafana 的架构允许它从多种数据源获取数据,并通过不同的图表和可视化方式展示这些数据。Grafana 支持的数据源非常广泛,包括 Prometheus、InfluxDB、Graphite、Elasticsearch 等。
Grafana 的核心功能包括:
- 动态仪表板 :创建动态的、实时更新的仪表板,支持多种图表类型。
- 告警通知 :配置不同的通知渠道,包括电子邮件、Slack、PagerDuty 等。
- 用户管理 :权限控制、用户认证和团队协作。
- 插件生态 :一个活跃的社区支持多种插件,扩展其功能。
6.1.2 安装Grafana的步骤
安装 Grafana 的过程相对简单,可以通过多种方式进行,包括使用官方的预编译包、Docker 容器或直接下载二进制文件。
以下是使用预编译包安装 Grafana 的步骤:
- 从 Grafana 官方网站下载适合您操作系统的最新版本。
- 根据您的操作系统,运行相应的安装脚本或包管理命令。
- 启动 Grafana 服务。
- 通过浏览器访问 Grafana 的默认端口(通常是 3000),并完成首次配置。
示例:在Ubuntu上通过包管理安装 Grafana
# 添加Grafana仓库
echo "deb ***" | sudo tee -a /etc/apt/sources.list.d/grafana.list
# 导入仓库签名密钥
curl ***
* 更新包索引
sudo apt-get update
# 安装Grafana
sudo apt-get install -y grafana
# 启动Grafana服务
sudo systemctl enable grafana-server
sudo systemctl start grafana-server
# 访问Grafana Web界面,默认地址为 *** ,使用默认的 admin/admin 登录。
安装完成后,Grafana 默认监听本地的 3000 端口。打开浏览器,输入 URL 访问 Grafana。
6.1.3 Grafana配置与优化
Grafana 提供了一个配置文件(grafana.ini),用于控制各种设置,例如数据库、日志、安全性、通知等。
示例:grafana.ini 配置文件片段
[database]
# 数据库类型,可以是 sqlite3, mysql, postgres, mssql
type = mysql
# 数据库地址和端口
host = ***.*.*.*:3306
# 数据库用户名
user = grafana
# 数据库密码
password = grafana_pass
[server]
# 服务器的HTTP端口
http_port = 3000
# 是否启用SSL模式
enablegzip = true
[log]
# 日志模式: console, file, 或者日志文件路径
mode = file
# 日志文件路径
path = /var/log/grafana/grafana.log
对于生产环境,建议更改默认的数据库、日志级别、访问地址和端口,并设置反向代理以提高安全性。
6.2 Grafana的数据源配置
6.2.1 添加Prometheus数据源
在 Grafana 中添加 Prometheus 作为数据源需要提供 Prometheus 的 HTTP API 端点。一旦配置完成,Grafana 就可以从 Prometheus 服务器获取数据,用于创建仪表板和图表。
操作步骤:
- 登录 Grafana Web 界面。
- 点击侧边栏的齿轮图标,进入 "Data Sources"。
- 点击 "Add data source",选择 "Prometheus"。
- 输入 Prometheus 服务器的 URL(例如:***)。
- 保存并测试数据源连接。
6.2.2 配置高级选项
Grafana 提供了高级选项以适应不同的使用场景。例如,可以配置数据源的 HTTP 请求超时时间、数据抓取间隔、查询缓存等。
示例:配置Prometheus数据源的高级选项
[datasources]
# Promtheus数据源的名称
name = Prometheus
# 数据源类型
type = prometheus
# Prometheus的HTTP API端点
url = ***
* 是否使用SSL连接
useSSL = false
# HTTP请求超时时间,单位毫秒
http_timeout = 30000
# 额外的HTTP请求头部
[datasources.http_header]
X-Header-Name = Value
在高级配置中,还可以定义 PromQL 查询的默认间隔时间,这些设置将应用于所有使用该数据源的仪表板。
6.3 创建仪表板与可视化
6.3.1 设计仪表板布局
设计一个有效的仪表板布局需要考虑数据的展示逻辑、用户的视觉体验以及操作的便利性。Grafana 提供了一个直观的拖放界面来设计仪表板。
设计布局的步骤:
- 在 Grafana 中创建一个新的仪表板。
- 使用拖放功能添加图表、单值显示和表格等组件。
- 调整组件的大小和位置以形成清晰的布局。
- 配置每个组件的数据源、查询和选项,以展示所需的数据。
6.3.2 配置图表与面板
图表是展示时间序列数据的核心组件。Grafana 支持多种图表类型,包括折线图、面积图、柱状图和饼图等。
配置图表的步骤:
- 选择要展示的数据源和查询。
- 配置查询的 PromQL 表达式。
- 选择图表类型和相关的设置,如图例显示方式、坐标轴设置等。
- 设置图表的标题和描述,以及面板的详细信息。
示例:添加一个折线图展示服务器的 CPU 使用率
panels:
- title: 'CPU Usage'
type: 'graph'
gridPos:
h: 8
w: 12
x: 0
y: 0
PrometheusQuery: 'sum(rate(node_cpu{mode="idle"}[5m])):lag 1m'
targets:
- refId: 'A'
query: 'sum(rate(node_cpu{mode="idle"}[5m])):lag 1m'
legendFormat: '{{instance}}'
axes:
left:
show: true
right:
show: false
bottom:
show: true
values: [now-1h,now,now+1h]
alert:
critical:
query:
refId: 'A'
query: 'sum(rate(node_cpu{mode="idle"}[5m])) <= 0.1'
reducer: avg
在 Grafana 中创建这样的仪表板和面板,可以让您直观地监控 Prometheus 收集的指标数据。您可以继续添加更多图表和组件,以全面监控和分析您的环境。
7. Prometheus的安装、配置与最佳实践
安装、配置和优化Prometheus是每个IT专业人员在构建监控系统时所必须掌握的技能。接下来,我们将深入探讨如何安装、配置Prometheus,并分享一些最佳实践,以确保您的监控系统能够有效地运行。
7.1 Prometheus的安装与部署
7.1.1 下载与安装Prometheus
首先,您需要从Prometheus的官方网站下载最新版本的安装包。Prometheus提供多种安装方式,包括预编译的二进制文件、Docker镜像以及适用于各种操作系统的安装包。对于大多数用户来说,使用官方提供的二进制文件进行安装是最简单的选择。
以下是在Linux环境下使用二进制文件安装Prometheus的步骤:
# 下载Prometheus
wget ***
* 解压压缩包
tar xvf prometheus-2.33.3.linux-amd64.tar.gz
# 进入目录并启动Prometheus服务
cd prometheus-2.33.3.linux-amd64
./prometheus
7.1.2 部署最佳实践
在部署Prometheus时,您应该考虑以下几点最佳实践:
- 资源分配 :确保Prometheus服务器有足够的CPU和内存资源,尤其是在处理大量时间序列数据时。
- 数据持久化 :配置持久化存储,以便在Prometheus重启后,数据不会丢失。
- 安全性配置 :配置TLS/SSL以确保数据传输的安全,同时配置好认证和授权。
- 备份 :定期备份Prometheus配置文件和数据,以防系统故障。
7.2 配置与监控设置
7.2.1 配置文件详解
Prometheus通过配置文件来定义监控目标和行为。配置文件一般命名为 prometheus.yml ,它定义了抓取作业、告警规则、持久化存储位置等重要参数。
下面是一个简单的配置文件示例:
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
在这个配置文件中, global 节定义了全局设置,比如抓取间隔( scrape_interval )和评估间隔( evaluation_interval )。 scrape_configs 节定义了需要监控的作业。
7.2.2 监控目标的设置方法
要添加新的监控目标,您需要在 scrape_configs 节中添加相应的配置。以下是如何配置Node Exporter以监控Linux服务器的示例:
- job_name: 'linux-nodes'
static_configs:
- targets: ['***:9100', '***:9100']
在这个配置中, job_name 定义了作业名称, static_configs 定义了目标服务器的地址和端口。
7.3 Prometheus最佳实践建议
7.3.1 监控策略与架构设计
设计有效的监控策略时,需要考虑以下因素:
- 目标选择 :选择重要的系统组件和应用进行监控。
- 标签管理 :合理使用标签来区分不同时间序列,便于查询和警报管理。
- 规则设计 :精心设计告警规则,确保及时得到重要事件的通知。
7.3.2 性能优化与故障排除
在使用Prometheus过程中,可能会遇到性能瓶颈或故障。以下是一些优化和故障排除的建议:
- 查询优化 :合理使用聚合和子查询,避免复杂的查询操作拖慢系统性能。
- 内存管理 :监控内存使用情况,并适当调整内存限制参数。
- 日志分析 :定期查看Prometheus日志,分析可能的错误和警告信息。
通过遵循这些最佳实践,您可以确保Prometheus在您的IT环境中的高效运行,及时发现并响应系统潜在的问题。
简介:Prometheus是一个开源监控和警报系统,专门设计用于云原生环境,强调简单性、高可用性与自动化。它具有强大的查询语言和灵活的警报管理功能,并提供与Grafana的集成。版本2.17.1带来了性能优化和新特性。本文将引导您通过下载和解压特定版本的Prometheus来安装和部署,以及解释其核心组件、数据模型、查询语言、服务发现和警报处理机制,同时提供最佳实践来确保监控系统的有效性和效率。















 1647
1647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









