






有这样的一个问题mysql查询使用mysql中left(right)join筛选条件在on与where查询出的数据是否有差异。
可能只看着两个关键字看不出任何的问题。那我们使用实际的例子来说到底有没有差异。
例如存在两张表结构
表结构1
drop table if EXISTS A;
CREATE TABLE A (
ID int(1) NOT NULL,
PRIMARY KEY (ID)
) ENGINE=MyISAM DEFAULT CHARSET=latin1;
表结构2
drop table if EXISTS B;
CREATE TABLE B (
ID int(1) NOT NULL,
PRIMARY KEY (ID)
) ENGINE=MyISAM DEFAULT CHARSET=latin1;
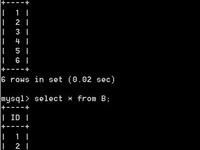
表一插入数据
insert into A values ( 1 );
insert into A values ( 2 );
insert into A values ( 3 );
insert into A values ( 4 );
insert into A values ( 5 );
insert into A values ( 6 );
表二插入数据
insert into B values ( 1 );
insert into B values ( 2 );
insert into B values ( 3 );
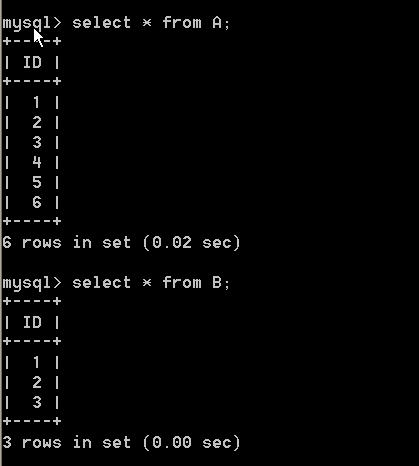
完成后A,B表数据如下:
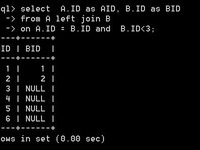
语句一
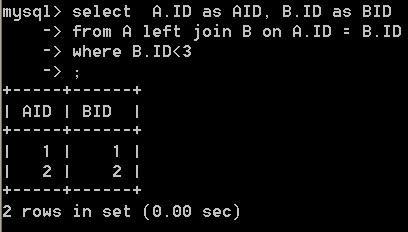
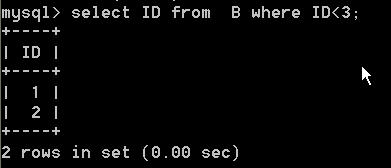
select A.ID as AID, B.ID as BID from A left join B on A.ID = B.ID where B.ID<3
语句二
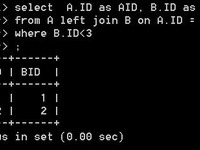
select A.ID as AID, B.ID as BID from A left join B on A.ID = B.ID and B.ID<3
以上两个语句的查询结果是否一致。
反正一切我是没有注意到这两个查询存在任何差异的【以前也没这么写过sql】。
我们看看实际结果
语句一的查询结果
语句二的查询结果为:
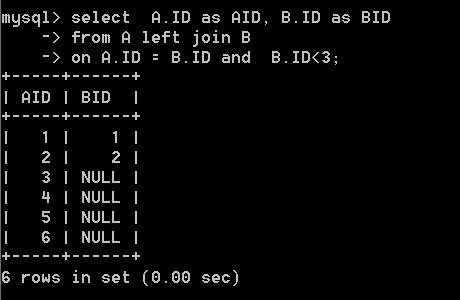
发现两个查询存在差异。
为什么会存在差异,这和on与where查询顺序有关。
我们知道标准查询关键字执行顺序为 from->where->group by->having->order by[
记得不是很清楚呢]
left join 是在from范围类所以 先on条件筛选表,然后两表再做left join。
而对于where来说在left join结果再次筛选。
第一sql语句查询过程如下等价于:
1:先是left join
select A.ID as AID, B.ID as BID from A left join B on A.ID = B.ID
查询结果如下
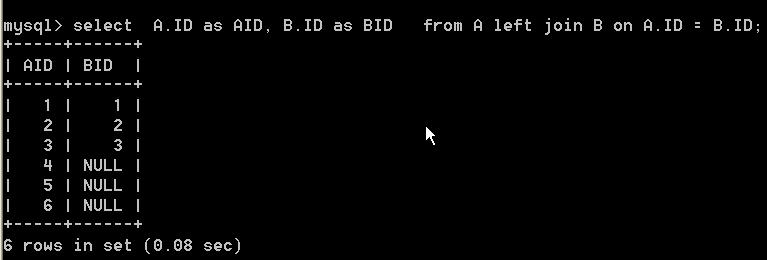
2:再查询结果中将B.ID即BID<2筛选出来。
也就是我们上面看到的结果。
第二sql语句查询过程如下等价于:
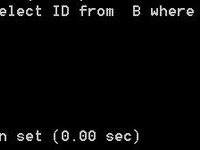
1:先按照on条件刷选表等价于先筛选B表:
2:再已上查询结果与A表做left join,这也是为什么我们看到第二个查询的sql会保留A表的原因。
ON与where的使用一定要注意场所:
(1):ON后面的筛选条件主要是针对的是关联表【而对于主表刷选条件不适用】。
例如
select A.ID as AID, B.ID as BID from A left join B on A.ID = B.ID and A.ID = 3
这个的查询结果为
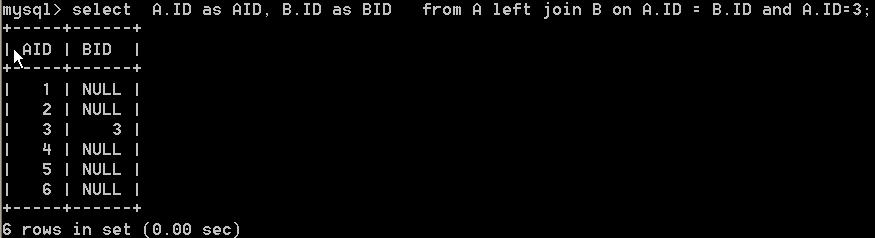
挺诧异的吧和我们期望的结果不一样,并为筛选出AID=3的数据。
但是我们也发现 AID 与 中AID 1 于2对应的值为NULL,关联表只取了满足A表筛刷选条件的值。
即主表条件在on后面时附表只取满足主表帅选条件的值、而主表还是取整表。
(2):对于主表的筛选条件应放在where后面,不应该放在ON后面
(3):对于关联表我们要区分对待。如果是要条件查询后才连接应该把查询件
放置于ON后。
如果是想再连接完毕后才筛选就应把条件放置于where后面
(4):
对于关联表我们其实可以先做子查询再做join
所以第二个sql等价于
select A.ID as AID, B1.ID as BID
from A left join ( select B.ID from B where B.ID <3 )B1 on A.ID = B1.ID
以上全在mysql5.1上测试过
大小: 17.5 KB
大小: 15.7 KB
大小: 19.1 KB
大小: 19.7 KB
大小: 9 KB
大小: 20.8 KB
7
顶
1
踩
分享到:


2011-01-12 10:11
浏览 39587
分类:数据库
评论
4 楼
greatwqs
2014-04-08
写得不错, 采用最后一种的SQL写法确实存在很多问题, 子查询数据太多.
执行效率很慢, 如果整个SQL的返回数据较多, 我用的时候还在前面加了一个insert, 经常造成MySQL死锁.
3楼第二个SQL
select * from bt left join ( select bt1.ID from bt1 where bt1.`VName`
where bt.ID <1000
执行时间少, 应该是子查询结果集比较小的原因,
如果较大还是用 LEFT JOIN XXXX ON .. AND ..
3 楼
80197675
2011-01-18
xiangzi21 写道
写的不错!
不过最后一个例子
select A.ID as AID, B1.ID as BID
from A left join ( select B.ID from B where B.ID <3 )B1 on A.ID = B1.ID
如果数据量小倒是可以,如果数据量大了mysql对关联字查询的效率不高吧?
刚才看呢下 上个是我子查询的sql写的有问题
select * from bt left join ( select bt1.ID from bt1 where bt1.`VName`
where bt.ID <1000
如果修改成上面的
查询时间为 105ms
和查询二相差不了多少。
所以应该效率是差不多......
即子查询与之间on查询效率应该差不了多少,单子查询必须写正确,像我第一次写的子查询就没写正确。
下次等测试完毕再下结论 呵呵
2 楼
80197675
2011-01-18
xiangzi21 写道
写的不错!
不过最后一个例子
select A.ID as AID, B1.ID as BID
from A left join ( select B.ID from B where B.ID <3 )B1 on A.ID = B1.ID
如果数据量小倒是可以,如果数据量大了mysql对关联字查询的效率不高吧?
恩 谢谢提醒。
会存在这样的问题,并且对于非索引列效率相差太大。
我拿这两张表做实验
CREATE TABLE `bt` (
`ID` int(10) NOT NULL,
`VName` varchar(20) NOT NULL DEFAULT '',
PRIMARY KEY (`ID`,`VName`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
CREATE TABLE `bt1` (
`ID` int(10) NOT NULL,
`VName` varchar(20) NOT NULL DEFAULT '',
KEY `ID` (`ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
分别插入10000000条数据 数据格式如下
ID vname
0 M0
1 M1
然后分别对索引列及非索引列采用两种方式查询。
索引列不存在什么差别,效率差不多。
单是对于非索引列差别相差太大。
查询语句如下
select * from bt left join ( select bt1.ID from bt1 where bt1.`VName`
where bt.ID <1000 --1
select *
from bt left join bt1 on bt.ID = bt1.`ID` and bt1.`VName`
where bt.ID <1000 --2
语句1花费 1000 rows fetched (24.860 sec)
语句2花费 1000 rows fetched (156 ms)
效率相差不是几倍而是几百倍。
1 楼
xiangzi21
2011-01-18
写的不错!
不过最后一个例子
select A.ID as AID, B1.ID as BID
from A left join ( select B.ID from B where B.ID <3 )B1 on A.ID = B1.ID
如果数据量小倒是可以,如果数据量大了mysql对关联字查询的效率不高吧?















 1330
1330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









